 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoAR: Autoregressive Video Generation via Next-Frame & Scale Prediction
Jan 09, 2026Recent advances in video generation have been dominated by diffusion and flow-matching models, which produce high-quality results but remain computationally intensive and difficult to scale. In this work, we introduce VideoAR, the first large-scale Visual Autoregressive (VAR) framework for video generation that combines multi-scale next-frame prediction with autoregressive modeling. VideoAR disentangles spatial and temporal dependencies by integrating intra-frame VAR modeling with causal next-frame prediction, supported by a 3D multi-scale tokenizer that efficiently encodes spatio-temporal dynamics. To improve long-term consistency, we propose Multi-scale Temporal RoPE, Cross-Frame Error Correction, and Random Frame Mask, which collectively mitigate error propagation and stabilize temporal coherence. Our multi-stage pretraining pipeline progressively aligns spatial and temporal learning across increasing resolutions and durations. Empirically, VideoAR achieves new state-of-the-art results among autoregressive models, improving FVD on UCF-101 from 99.5 to 88.6 while reducing inference steps by over 10x, and reaching a VBench score of 81.74-competitive with diffusion-based models an order of magnitude larger. These results demonstrate that VideoAR narrows the performance gap between autoregressive and diffusion paradigms, offering a scalable, efficient, and temporally consistent foundation for future video generation research.
MoE Adapter for Large Audio Language Models: Sparsity, Disentanglement, and Gradient-Conflict-Free
Jan 08, 2026Extending the input modality of Large Language Models~(LLMs) to the audio domain is essential for achieving comprehensive multimodal perception. However, it is well-known that acoustic information is intrinsically \textit{heterogeneous}, entangling attributes such as speech, music, and environmental context. Existing research is limited to a dense, parameter-shared adapter to model these diverse patterns, which induces \textit{gradient conflict} during optimization, as parameter updates required for distinct attributes contradict each other. To address this limitation, we introduce the \textit{\textbf{MoE-Adapter}}, a sparse Mixture-of-Experts~(MoE) architecture designed to decouple acoustic information. Specifically, it employs a dynamic gating mechanism that routes audio tokens to specialized experts capturing complementary feature subspaces while retaining shared experts for global context, thereby mitigating gradient conflicts and enabling fine-grained feature learning. Comprehensive experiments show that the MoE-Adapter achieves superior performance on both audio semantic and paralinguistic tasks, consistently outperforming dense linear baselines with comparable computational costs. Furthermore, we will release the related code and models to facilitate future research.
FROST-Drive: Scalable and Efficient End-to-End Driving with a Frozen Vision Encoder
Jan 06, 2026End-to-end (E2E) models in autonomous driving aim to directly map sensor inputs to control commands, but their ability to generalize to novel and complex scenarios remains a key challenge. The common practice of fully fine-tuning the vision encoder on driving datasets potentially limits its generalization by causing the model to specialize too heavily in the training data. This work challenges the necessity of this training paradigm. We propose FROST-Drive, a novel E2E architecture designed to preserve and leverage the powerful generalization capabilities of a pretrained vision encoder from a Vision-Language Model (VLM). By keeping the encoder's weights frozen, our approach directly transfers the rich, generalized world knowledge from the VLM to the driving task. Our model architecture combines this frozen encoder with a transformer-based adapter for multimodal fusion and a GRU-based decoder for smooth waypoint generation. Furthermore, we introduce a custom loss function designed to directly optimize for Rater Feedback Score (RFS), a metric that prioritizes robust trajectory planning. We conduct extensive experiments on Waymo Open E2E Dataset, a large-scale datasets deliberately curated to capture the long-tail scenarios, demonstrating that our frozen-encoder approach significantly outperforms models that employ full fine-tuning. Our results provide substantial evidence that preserving the broad knowledge of a capable VLM is a more effective strategy for achieving robust, generalizable driving performance than intensive domain-specific adaptation. This offers a new pathway for developing vision-based models that can better handle the complexities of real-world application domains.
End-to-End Test-Time Training for Long Context
Dec 31, 2025We formulate long-context language modeling as a problem in continual learning rather than architecture design. Under this formulation, we only use a standard architecture -- a Transformer with sliding-window attention. However, our model continues learning at test time via next-token prediction on the given context, compressing the context it reads into its weights. In addition, we improve the model's initialization for learning at test time via meta-learning at training time. Overall, our method, a form of Test-Time Training (TTT), is End-to-End (E2E) both at test time (via next-token prediction) and training time (via meta-learning), in contrast to previous forms. We conduct extensive experiments with a focus on scaling properties. In particular, for 3B models trained with 164B tokens, our method (TTT-E2E) scales with context length in the same way as Transformer with full attention, while others, such as Mamba 2 and Gated DeltaNet, do not. However, similar to RNNs, TTT-E2E has constant inference latency regardless of context length, making it 2.7 times faster than full attention for 128K context. Our code is publicly available.
From Visual Perception to Deep Empathy: An Automated Assessment Framework for House-Tree-Person Drawings Using Multimodal LLMs and Multi-Agent Collaboration
Dec 23, 2025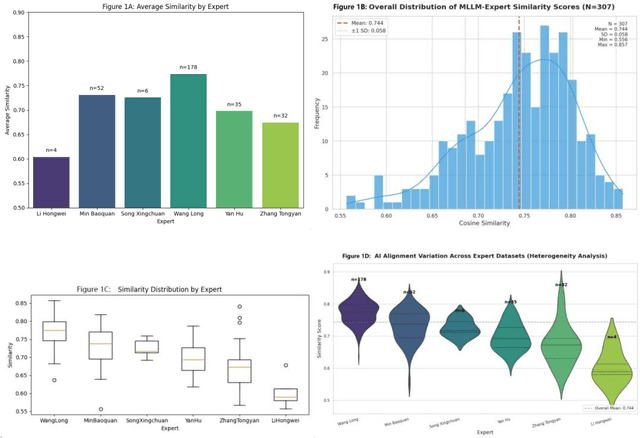
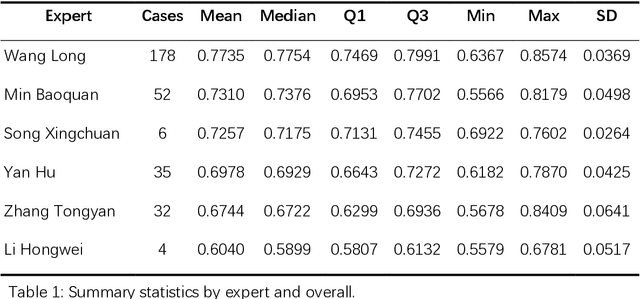
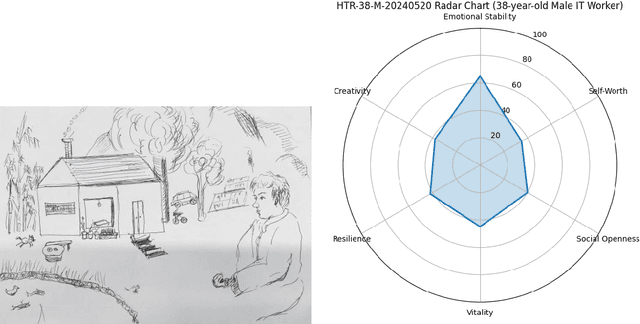
Background: The House-Tree-Person (HTP) drawing test, introduced by John Buck in 1948, remains a widely used projective technique in clinical psychology. However, it has long faced challenges such as heterogeneous scoring standards, reliance on examiners subjective experience, and a lack of a unified quantitative coding system. Results: Quantitative experiments showed that the mean semantic similarity between Multimodal Large Language Model (MLLM) interpretations and human expert interpretations was approximately 0.75 (standard deviation about 0.05). In structurally oriented expert data sets, this similarity rose to 0.85, indicating expert-level baseline comprehension. Qualitative analyses demonstrated that the multi-agent system, by integrating social-psychological perspectives and destigmatizing narratives, effectively corrected visual hallucinations and produced psychological reports with high ecological validity and internal coherence. Conclusions: The findings confirm the potential of multimodal large models as standardized tools for projective assessment. The proposed multi-agent framework, by dividing roles, decouples feature recognition from psychological inference and offers a new paradigm for digital mental-health services. Keywords: House-Tree-Person test; multimodal large language model; multi-agent collaboration; cosine similarity; computational psychology; artificial intelligence
PSI3D: Plug-and-Play 3D Stochastic Inference with Slice-wise Latent Diffusion Prior
Dec 20, 2025Diffusion models are highly expressive image priors for Bayesian inverse problems. However, most diffusion models cannot operate on large-scale, high-dimensional data due to high training and inference costs. In this work, we introduce a Plug-and-play algorithm for 3D stochastic inference with latent diffusion prior (PSI3D) to address massive ($1024\times 1024\times 128$) volumes. Specifically, we formulate a Markov chain Monte Carlo approach to reconstruct each two-dimensional (2D) slice by sampling from a 2D latent diffusion model. To enhance inter-slice consistency, we also incorporate total variation (TV) regularization stochastically along the concatenation axis. We evaluate our performance on optical coherence tomography (OCT) super-resolution. Our method significantly improves reconstruction quality for large-scale scientific imaging compared to traditional and learning-based baselines, while providing robust and credible reconstructions.
Distillation of Discrete Diffusion by Exact Conditional Distribution Matching
Dec 15, 2025Discrete diffusion models (DDMs) are a powerful class of generative models for categorical data, but they typically require many function evaluations for a single sample, making inference expensive. Existing acceleration methods either rely on approximate simulators, such as $τ$-leaping, or on distillation schemes that train new student models and auxiliary networks with proxy objectives. We propose a simple and principled distillation alternative based on \emph{conditional distribution matching}. Our key observation is that the reverse conditional distribution of clean data given a noisy state, $p_{0\mid t}(x_0 \mid x_t)$, admits a Markov decomposition through intermediate times and can be recovered from marginal density ratios and the known forward CTMC kernel. We exploit this structure to define distillation objectives that directly match conditional distributions between a pre-trained teacher and a low-NFE student, both for one-step and few-step samplers.
Blink: Dynamic Visual Token Resolution for Enhanced Multimodal Understanding
Dec 11, 2025Multimodal large language models (MLLMs) have achieved remarkable progress on various vision-language tasks, yet their visual perception remains limited. Humans, in comparison, perceive complex scenes efficiently by dynamically scanning and focusing on salient regions in a sequential "blink-like" process. Motivated by this strategy, we first investigate whether MLLMs exhibit similar behavior. Our pilot analysis reveals that MLLMs naturally attend to different visual regions across layers and that selectively allocating more computation to salient tokens can enhance visual perception. Building on this insight, we propose Blink, a dynamic visual token resolution framework that emulates the human-inspired process within a single forward pass. Specifically, Blink includes two modules: saliency-guided scanning and dynamic token resolution. It first estimates the saliency of visual tokens in each layer based on the attention map, and extends important tokens through a plug-and-play token super-resolution (TokenSR) module. In the next layer, it drops the extended tokens when they lose focus. This dynamic mechanism balances broad exploration and fine-grained focus, thereby enhancing visual perception adaptively and efficiently. Extensive experiments validate Blink, demonstrating its effectiveness in enhancing visual perception and multimodal understanding.
PRISM: Probabilistic and Robust Inverse Solver with Measurement-Conditioned Diffusion Prior for Blind Inverse Problems
Sep 19, 2025Diffusion models are now commonly used to solve inverse problems in computational imaging. However, most diffusion-based inverse solvers require complete knowledge of the forward operator to be used. In this work, we introduce a novel probabilistic and robust inverse solver with measurement-conditioned diffusion prior (PRISM) to effectively address blind inverse problems. PRISM offers a technical advancement over current methods by incorporating a powerful measurement-conditioned diffusion model into a theoretically principled posterior sampling scheme. Experiments on blind image deblurring validate the effectiveness of the proposed method, demonstrating the superior performance of PRISM over state-of-the-art baselines in both image and blur kernel recovery.
Dataset and Benchmark for Enhancing Critical Retained Foreign Object Detection
Jul 09, 2025Critical retained foreign objects (RFOs), including surgical instruments like sponges and needles, pose serious patient safety risks and carry significant financial and legal implications for healthcare institutions. Detecting critical RFOs using artificial intelligence remains challenging due to their rarity and the limited availability of chest X-ray datasets that specifically feature critical RFOs cases. Existing datasets only contain non-critical RFOs, like necklace or zipper, further limiting their utility for developing clinically impactful detection algorithms. To address these limitations, we introduce "Hopkins RFOs Bench", the first and largest dataset of its kind, containing 144 chest X-ray images of critical RFO cases collected over 18 years from the Johns Hopkins Health System. Using this dataset, we benchmark several state-of-the-art object detection models, highlighting the need for enhanced detection methodologies for critical RFO cases. Recognizing data scarcity challenges, we further explore image synthetic methods to bridge this gap. We evaluate two advanced synthetic image methods, DeepDRR-RFO, a physics-based method, and RoentGen-RFO, a diffusion-based method, for creating realistic radiographs featuring critical RFOs. Our comprehensive analysis identifies the strengths and limitations of each synthetic method, providing insights into effectively utilizing synthetic data to enhance model training. The Hopkins RFOs Bench and our findings significantly advance the development of reliable, generalizable AI-driven solutions for detecting critical RFOs in clinical chest X-rays.