 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLIOS: An LLM-Augmented Real-Time Multi-Modal Interactive Enhancement Overlay System for Douyin Live Streaming
Mar 03, 2026We present DLIOS, a Large Language Model (LLM)-augmented real-time multi-modal interactive enhancement overlay system for Douyin (TikTok) live streaming. DLIOS employs a three-layer transparent window architecture for independent rendering of danmaku (scrolling text), gift and like particle effects, and VIP entrance animations, built around an event-driven WebView2 capture pipeline and a thread-safe event bus. On top of this foundation we contribute an LLM broadcast automation framework comprising: (1) a per-song four-segment prompt scheduling system (T1 opening/transition, T2 empathy, T3 era story/production notes, T4 closing) that generates emotionally coherent radio-style commentary from lyric metadata; (2) a JSON-serializable RadioPersonaConfig schema supporting hot-swap multi-persona broadcasting; (3) a real-time danmaku quick-reaction engine with keyword routing to static urgent speech or LLM-generated empathetic responses; and (4) the Suwan Li AI singer-songwriter persona case study -- over 100 AI-generated songs produced with Suno. A 36-hour stress test demonstrates: zero danmaku overlap, zero deadlock crashes, gift effect P95 latency <= 180 ms, LLM-to-TTS segment P95 latency <= 2.1 s, and TTS integrated loudness gain of 9.5 LUFS. live streaming; danmaku; large language model; prompt engineering; virtual persona; WebView2; WINMM; TTS; Suno; loudness normalization; real-time scheduling
From Visual Perception to Deep Empathy: An Automated Assessment Framework for House-Tree-Person Drawings Using Multimodal LLMs and Multi-Agent Collaboration
Dec 23, 2025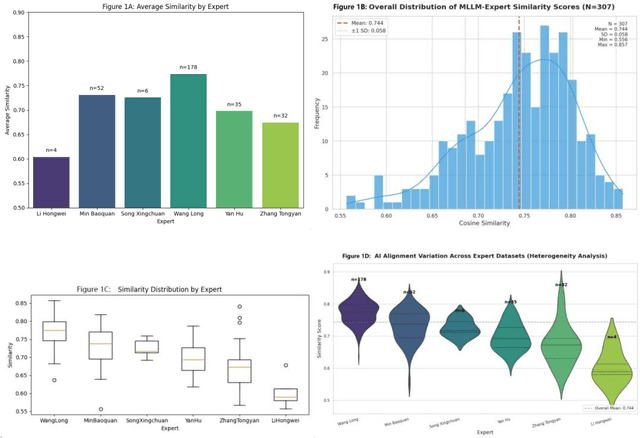
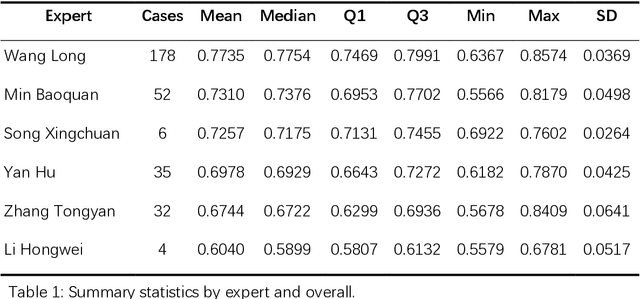
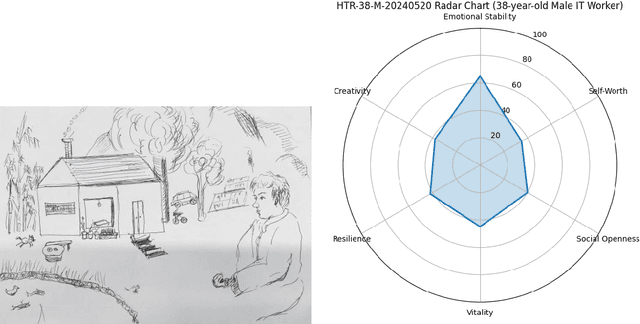
Background: The House-Tree-Person (HTP) drawing test, introduced by John Buck in 1948, remains a widely used projective technique in clinical psychology. However, it has long faced challenges such as heterogeneous scoring standards, reliance on examiners subjective experience, and a lack of a unified quantitative coding system. Results: Quantitative experiments showed that the mean semantic similarity between Multimodal Large Language Model (MLLM) interpretations and human expert interpretations was approximately 0.75 (standard deviation about 0.05). In structurally oriented expert data sets, this similarity rose to 0.85, indicating expert-level baseline comprehension. Qualitative analyses demonstrated that the multi-agent system, by integrating social-psychological perspectives and destigmatizing narratives, effectively corrected visual hallucinations and produced psychological reports with high ecological validity and internal coherence. Conclusions: The findings confirm the potential of multimodal large models as standardized tools for projective assessment. The proposed multi-agent framework, by dividing roles, decouples feature recognition from psychological inference and offers a new paradigm for digital mental-health services. Keywords: House-Tree-Person test; multimodal large language model; multi-agent collaboration; cosine similarity; computational psychology; artificial intelligence