 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Switching Text Generation and Injection in Mandarin-English ASR
Mar 20, 2023



Code-switching speech refers to a means of expression by mixing two or more languages within a single utterance. Automatic Speech Recognition (ASR) with End-to-End (E2E) modeling for such speech can be a challenging task due to the lack of data. In this study, we investigate text generation and injection for improving the performance of an industry commonly-used streaming model, Transformer-Transducer (T-T), in Mandarin-English code-switching speech recognition. We first propose a strategy to generate code-switching text data and then investigate injecting generated text into T-T model explicitly by Text-To-Speech (TTS) conversion or implicitly by tying speech and text latent spaces. Experimental results on the T-T model trained with a dataset containing 1,800 hours of real Mandarin-English code-switched speech show that our approaches to inject generated code-switching text significantly boost the performance of T-T models, i.e., 16% relative Token-based Error Rate (TER) reduction averaged on three evaluation sets, and the approach of tying speech and text latent spaces is superior to that of TTS conversion on the evaluation set which contains more homogeneous data with the training set.
Unreliable Partial Label Learning with Recursive Separation
Feb 20, 2023Partial label learning (PLL) is a typical weakly supervised learning problem in which each instance is associated with a candidate label set, and among which only one is true. However, the assumption that the ground-truth label is always among the candidate label set would be unrealistic, as the reliability of the candidate label sets in real-world applications cannot be guaranteed by annotators. Therefore, a generalized PLL named Unreliable Partial Label Learning (UPLL) is proposed, in which the true label may not be in the candidate label set. Due to the challenges posed by unreliable labeling, previous PLL methods will experience a marked decline in performance when applied to UPLL. To address the issue, we propose a two-stage framework named Unreliable Partial Label Learning with Recursive Separation (UPLLRS). In the first stage, the self-adaptive recursive separation strategy is proposed to separate the training set into a reliable subset and an unreliable subset. In the second stage, a disambiguation strategy is employed to progressively identify the ground-truth labels in the reliable subset. Simultaneously, semi-supervised learning methods are adopted to extract valuable information from the unreliable subset. Our method demonstrates state-of-the-art performance as evidenced by experimental results, particularly in situations of high unreliability.
Learning From Biased Soft Labels
Feb 16, 2023



Knowledge distillation has been widely adopted in a variety of tasks and has achieved remarkable successes. Since its inception, many researchers have been intrigued by the dark knowledge hidden in the outputs of the teacher model. Recently, a study has demonstrated that knowledge distillation and label smoothing can be unified as learning from soft labels. Consequently, how to measure the effectiveness of the soft labels becomes an important question. Most existing theories have stringent constraints on the teacher model or data distribution, and many assumptions imply that the soft labels are close to the ground-truth labels. This paper studies whether biased soft labels are still effective. We present two more comprehensive indicators to measure the effectiveness of such soft labels. Based on the two indicators, we give sufficient conditions to ensure biased soft label based learners are classifier-consistent and ERM learnable. The theory is applied to three weakly-supervised frameworks. Experimental results validate that biased soft labels can also teach good students, which corroborates the soundness of the theory.
Efficient End-to-End Video Question Answering with Pyramidal Multimodal Transformer
Feb 04, 2023This paper presents a new method for end-to-end Video Question Answering (VideoQA), aside from the current popularity of using large-scale pre-training with huge feature extractors. We achieve this with a pyramidal multimodal transformer (PMT) model, which simply incorporates a learnable word embedding layer, a few convolutional and transformer layers. We use the anisotropic pyramid to fulfill video-language interactions across different spatio-temporal scales. In addition to the canonical pyramid, which includes both bottom-up and top-down pathways with lateral connections, novel strategies are proposed to decompose the visual feature stream into spatial and temporal sub-streams at different scales and implement their interactions with the linguistic semantics while preserving the integrity of local and global semantics. We demonstrate better or on-par performances with high computational efficiency against state-of-the-art methods on five VideoQA benchmarks. Our ablation study shows the scalability of our model that achieves competitive results for text-to-video retrieval by leveraging feature extractors with reusable pre-trained weights, and also the effectiveness of the pyramid.
Towards a Single Unified Model for Effective Detection, Segmentation, and Diagnosis of Eight Major Cancers Using a Large Collection of CT Scans
Jan 28, 2023



Human readers or radiologists routinely perform full-body multi-organ multi-disease detection and diagnosis in clinical practice, while most medical AI systems are built to focus on single organs with a narrow list of a few diseases. This might severely limit AI's clinical adoption. A certain number of AI models need to be assembled non-trivially to match the diagnostic process of a human reading a CT scan. In this paper, we construct a Unified Tumor Transformer (UniT) model to detect (tumor existence and location) and diagnose (tumor characteristics) eight major cancer-prevalent organs in CT scans. UniT is a query-based Mask Transformer model with the output of multi-organ and multi-tumor semantic segmentation. We decouple the object queries into organ queries, detection queries and diagnosis queries, and further establish hierarchical relationships among the three groups. This clinically-inspired architecture effectively assists inter- and intra-organ representation learning of tumors and facilitates the resolution of these complex, anatomically related multi-organ cancer image reading tasks. UniT is trained end-to-end using a curated large-scale CT images of 10,042 patients including eight major types of cancers and occurring non-cancer tumors (all are pathology-confirmed with 3D tumor masks annotated by radiologists). On the test set of 631 patients, UniT has demonstrated strong performance under a set of clinically relevant evaluation metrics, substantially outperforming both multi-organ segmentation methods and an assembly of eight single-organ expert models in tumor detection, segmentation, and diagnosis. Such a unified multi-cancer image reading model (UniT) can significantly reduce the number of false positives produced by combined multi-system models. This moves one step closer towards a universal high-performance cancer screening tool.
A deep local attention network for pre-operative lymph node metastasis prediction in pancreatic cancer via multiphase CT imaging
Jan 04, 2023



Lymph node (LN) metastasis status is one of the most critical prognostic and cancer staging factors for patients with resectable pancreatic ductal adenocarcinoma (PDAC), or in general, for any types of solid malignant tumors. Preoperative prediction of LN metastasis from non-invasive CT imaging is highly desired, as it might be straightforwardly used to guide the following neoadjuvant treatment decision and surgical planning. Most studies only capture the tumor characteristics in CT imaging to implicitly infer LN metastasis and very few work exploit direct LN's CT imaging information. To the best of our knowledge, this is the first work to propose a fully-automated LN segmentation and identification network to directly facilitate the LN metastasis status prediction task. Nevertheless LN segmentation/detection is very challenging since LN can be easily confused with other hard negative anatomic structures (e.g., vessels) from radiological images. We explore the anatomical spatial context priors of pancreatic LN locations by generating a guiding attention map from related organs and vessels to assist segmentation and infer LN status. As such, LN segmentation is impelled to focus on regions that are anatomically adjacent or plausible with respect to the specific organs and vessels. The metastasized LN identification network is trained to classify the segmented LN instances into positives or negatives by reusing the segmentation network as a pre-trained backbone and padding a new classification head. More importantly, we develop a LN metastasis status prediction network that combines the patient-wise aggregation results of LN segmentation/identification and deep imaging features extracted from the tumor region. Extensive quantitative nested five-fold cross-validation is conducted on a discovery dataset of 749 patients with PDAC.
Breaking trade-offs in speech separation with sparsely-gated mixture of experts
Nov 11, 2022Several trade-offs need to be balanced when employing monaural speech separation (SS) models in conversational automatic speech recognition (ASR) systems. A larger SS model generally achieves better output quality at an expense of higher computation, meanwhile, a better SS model for overlapping speech often produces distorted output for non-overlapping speech. This paper addresses these trade-offs with a sparsely-gated mixture-of-experts (MoE). The sparsely-gated MoE architecture allows the separation models to be enlarged without compromising the run-time efficiency, which also helps achieve a better separation-distortion trade-off. To further reduce the speech distortion without compromising the SS capability, a multi-gate MoE framework is also explored, where different gates handle non-overlapping and overlapping frames differently. ASR experiments are conducted by using a simulated dataset for measuring both the speech separation accuracy and the speech distortion. Two advanced SS models, Conformer and WavLM-based models, are used as baselines. The sparsely-gated MoE models show a superior SS capability with less speech distortion, meanwhile marginally increasing the run-time computational cost. Experimental results using real conversation recordings are also presented, showing MoE's effectiveness in an end-to-end evaluation setting.
Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization
Aug 21, 2022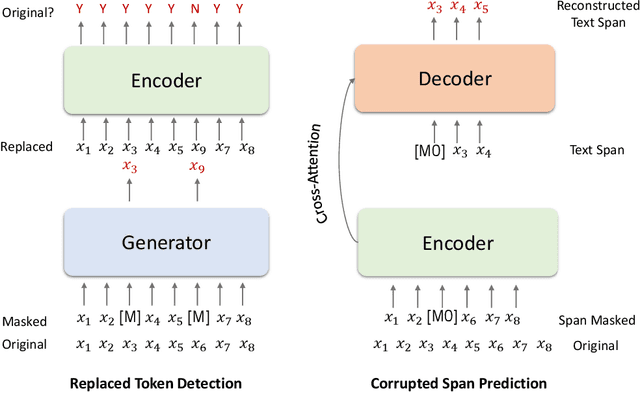

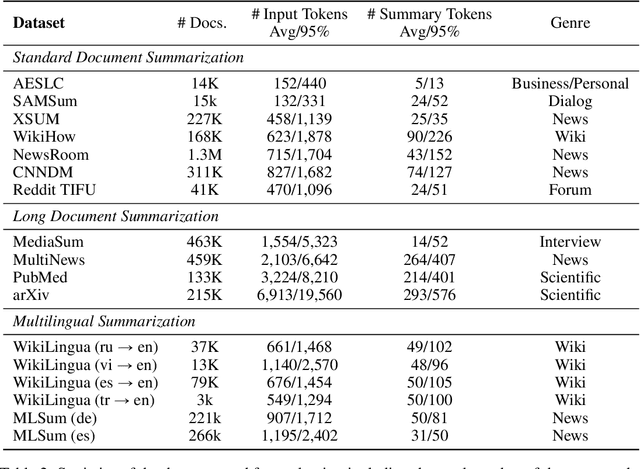
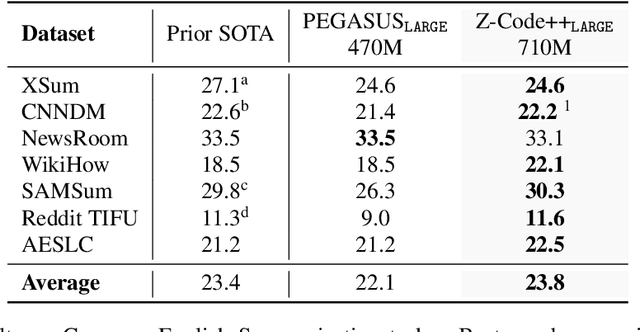
This paper presents Z-Code++, a new pre-trained language model optimized for abstractive text summarization. The model extends the state of the art encoder-decoder model using three techniques. First, we use a two-phase pre-training process to improve model's performance on low-resource summarization tasks. The model is first pre-trained using text corpora for language understanding, and then is continually pre-trained on summarization corpora for grounded text generation. Second, we replace self-attention layers in the encoder with disentangled attention layers, where each word is represented using two vectors that encode its content and position, respectively. Third, we use fusion-in-encoder, a simple yet effective method of encoding long sequences in a hierarchical manner. Z-Code++ creates new state of the art on 9 out of 13 text summarization tasks across 5 languages. Our model is parameter-efficient in that it outperforms the 600x larger PaLM-540B on XSum, and the finetuned 200x larger GPT3-175B on SAMSum. In zero-shot and few-shot settings, our model substantially outperforms the competing models.
Predicting the protein-ligand affinity from molecular dynamics trajectories
Aug 19, 2022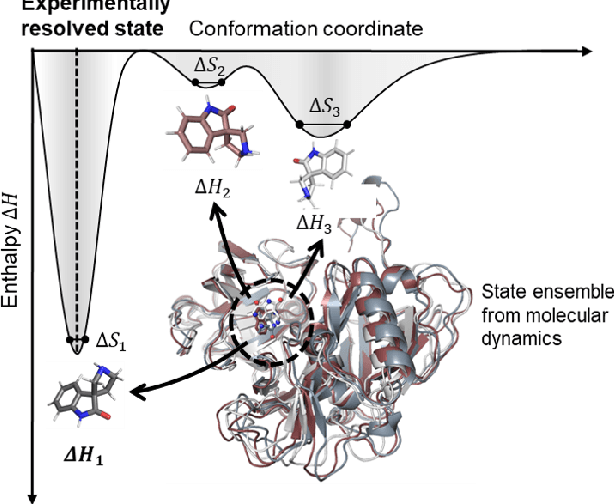
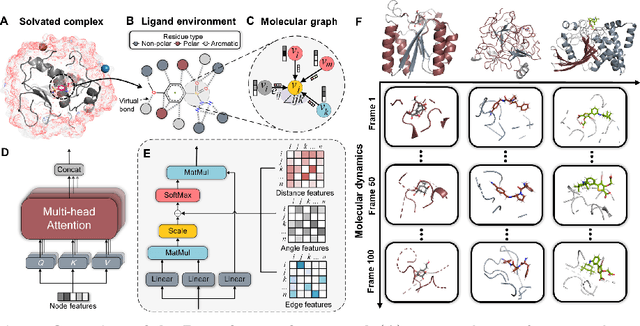
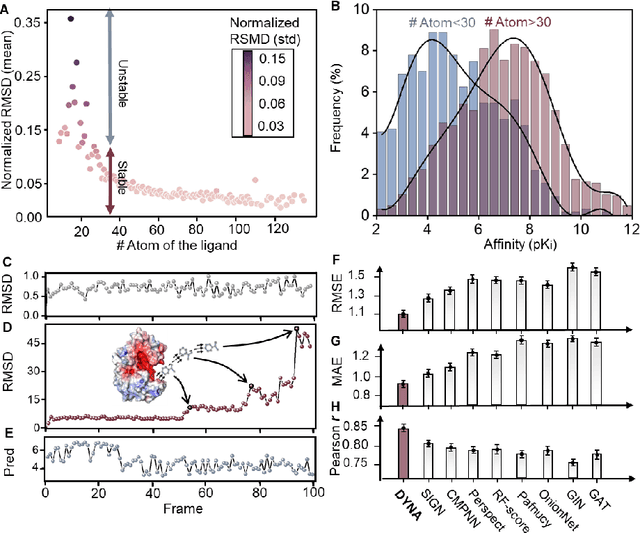
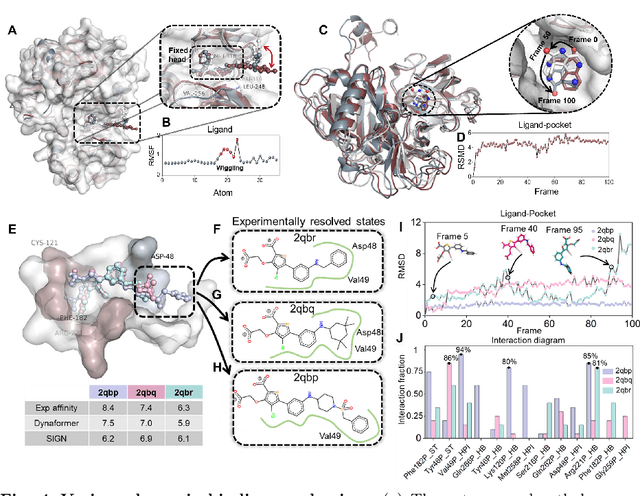
The accurate protein-ligand binding affinity prediction is essential in drug design and many other molecular recognition problems. Despite many advances in affinity prediction based on machine learning techniques, they are still limited since the protein-ligand binding is determined by the dynamics of atoms and molecules. To this end, we curated an MD dataset containing 3,218 dynamic protein-ligand complexes and further developed Dynaformer, a graph-based deep learning framework. Dynaformer can fully capture the dynamic binding rules by considering various geometric characteristics of the interaction. Our method shows superior performance over the methods hitherto reported. Moreover, we performed virtual screening on heat shock protein 90 (HSP90) by integrating our model with structure-based docking. We benchmarked our performance against other baselines, demonstrating that our method can identify the molecule with the highest experimental potency. We anticipate that large-scale MD dataset and machine learning models will form a new synergy, providing a new route towards accelerated drug discovery and optimization.
Quantized Training of Gradient Boosting Decision Trees
Jul 20, 2022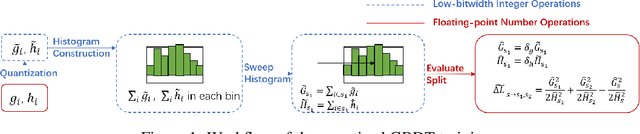
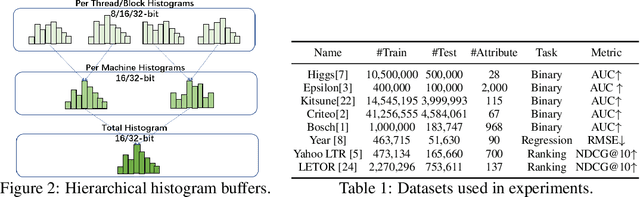
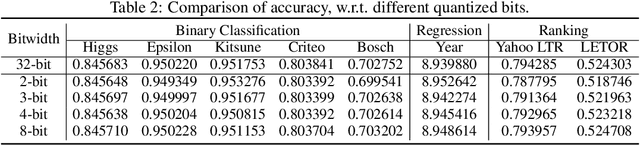
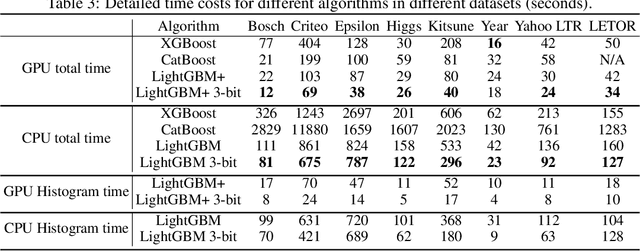
Recent years have witnessed significant success in Gradient Boosting Decision Trees (GBDT) for a wide range of machine learning applications. Generally, a consensus about GBDT's training algorithms is gradients and statistics are computed based on high-precision floating points. In this paper, we investigate an essentially important question which has been largely ignored by the previous literature: how many bits are needed for representing gradients in training GBDT? To solve this mystery, we propose to quantize all the high-precision gradients in a very simple yet effective way in the GBDT's training algorithm. Surprisingly, both our theoretical analysis and empirical studies show that the necessary precisions of gradients without hurting any performance can be quite low, e.g., 2 or 3 bits. With low-precision gradients, most arithmetic operations in GBDT training can be replaced by integer operations of 8, 16, or 32 bits. Promisingly, these findings may pave the way for much more efficient training of GBDT from several aspects: (1) speeding up the computation of gradient statistics in histograms; (2) compressing the communication cost of high-precision statistical information during distributed training; (3) the inspiration of utilization and development of hardware architectures which well support low-precision computation for GBDT training. Benchmarked on CPU, GPU, and distributed clusters, we observe up to 2$\times$ speedup of our simple quantization strategy compared with SOTA GBDT systems on extensive datasets, demonstrating the effectiveness and potential of the low-precision training of GBDT. The code will be released to the official repository of LightGBM.