 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient End-to-End Video Question Answering with Pyramidal Multimodal Transformer
Feb 04, 2023This paper presents a new method for end-to-end Video Question Answering (VideoQA), aside from the current popularity of using large-scale pre-training with huge feature extractors. We achieve this with a pyramidal multimodal transformer (PMT) model, which simply incorporates a learnable word embedding layer, a few convolutional and transformer layers. We use the anisotropic pyramid to fulfill video-language interactions across different spatio-temporal scales. In addition to the canonical pyramid, which includes both bottom-up and top-down pathways with lateral connections, novel strategies are proposed to decompose the visual feature stream into spatial and temporal sub-streams at different scales and implement their interactions with the linguistic semantics while preserving the integrity of local and global semantics. We demonstrate better or on-par performances with high computational efficiency against state-of-the-art methods on five VideoQA benchmarks. Our ablation study shows the scalability of our model that achieves competitive results for text-to-video retrieval by leveraging feature extractors with reusable pre-trained weights, and also the effectiveness of the pyramid.
Multilevel Hierarchical Network with Multiscale Sampling for Video Question Answering
May 09, 2022
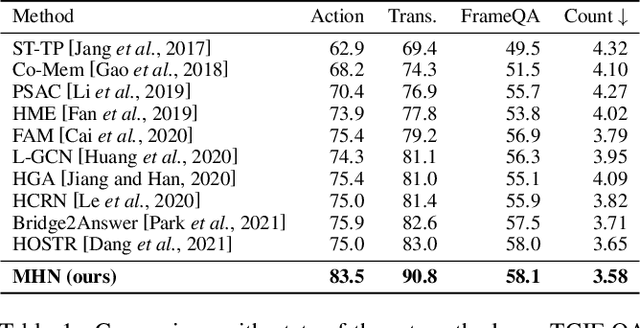
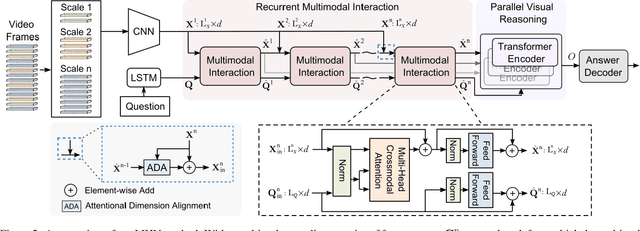
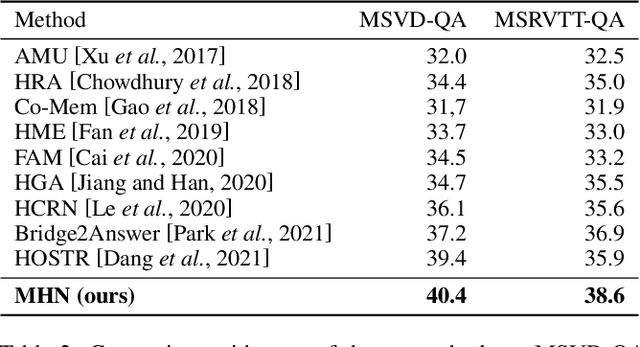
Video question answering (VideoQA) is challenging given its multimodal combination of visual understanding and natural language processing. While most existing approaches ignore the visual appearance-motion information at different temporal scales, it is unknown how to incorporate the multilevel processing capacity of a deep learning model with such multiscale information. Targeting these issues, this paper proposes a novel Multilevel Hierarchical Network (MHN) with multiscale sampling for VideoQA. MHN comprises two modules, namely Recurrent Multimodal Interaction (RMI) and Parallel Visual Reasoning (PVR). With a multiscale sampling, RMI iterates the interaction of appearance-motion information at each scale and the question embeddings to build the multilevel question-guided visual representations. Thereon, with a shared transformer encoder, PVR infers the visual cues at each level in parallel to fit with answering different question types that may rely on the visual information at relevant levels. Through extensive experiments on three VideoQA datasets, we demonstrate improved performances than previous state-of-the-arts and justify the effectiveness of each part of our method.
Temporal Pyramid Transformer with Multimodal Interaction for Video Question Answering
Sep 10, 2021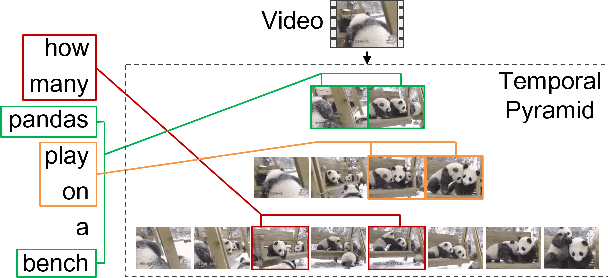
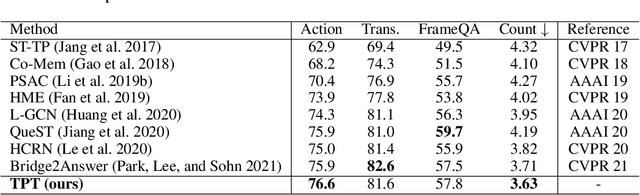
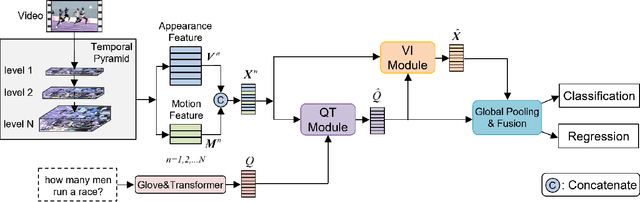
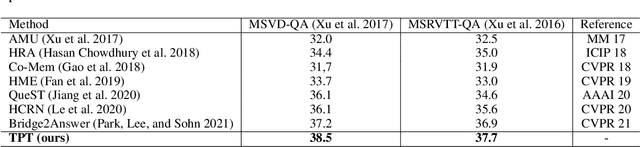
Video question answering (VideoQA) is challenging given its multimodal combination of visual understanding and natural language understanding. While existing approaches seldom leverage the appearance-motion information in the video at multiple temporal scales, the interaction between the question and the visual information for textual semantics extraction is frequently ignored. Targeting these issues, this paper proposes a novel Temporal Pyramid Transformer (TPT) model with multimodal interaction for VideoQA. The TPT model comprises two modules, namely Question-specific Transformer (QT) and Visual Inference (VI). Given the temporal pyramid constructed from a video, QT builds the question semantics from the coarse-to-fine multimodal co-occurrence between each word and the visual content. Under the guidance of such question-specific semantics, VI infers the visual clues from the local-to-global multi-level interactions between the question and the video. Within each module, we introduce a multimodal attention mechanism to aid the extraction of question-video interactions, with residual connections adopted for the information passing across different levels. Through extensive experiments on three VideoQA datasets, we demonstrate better performances of the proposed method in comparison with the state-of-the-arts.
STA-VPR: Spatio-temporal Alignment for Visual Place Recognition
Apr 09, 2021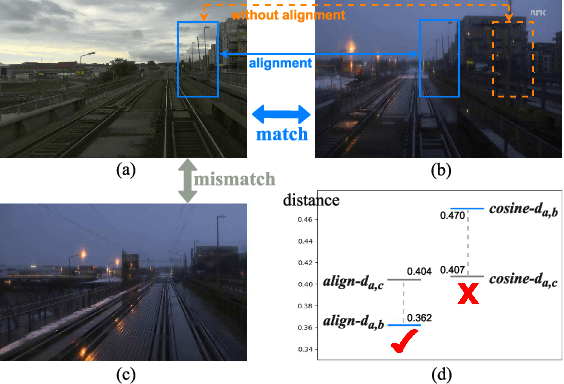
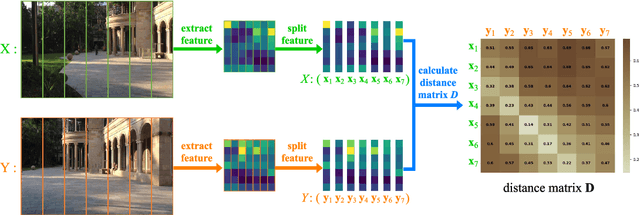
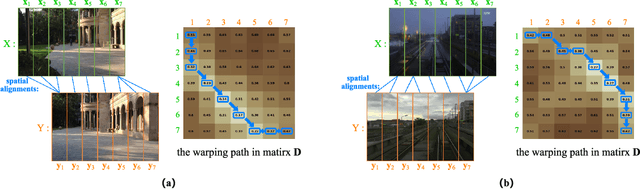
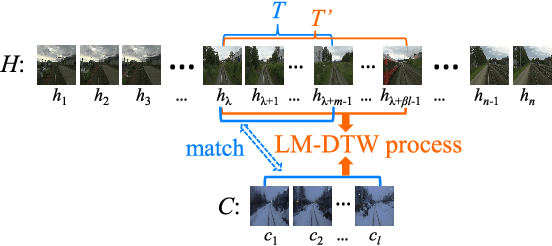
Recently, the methods based on Convolutional Neural Networks (CNNs) have gained popularity in the field of visual place recognition (VPR). In particular, the features from the middle layers of CNNs are more robust to drastic appearance changes than handcrafted features and high-layer features. Unfortunately, the holistic mid-layer features lack robustness to large viewpoint changes. Here we split the holistic mid-layer features into local features, and propose an adaptive dynamic time warping (DTW) algorithm to align local features from the spatial domain while measuring the distance between two images. This realizes viewpoint-invariant and condition-invariant place recognition. Meanwhile, a local matching DTW (LM-DTW) algorithm is applied to perform image sequence matching based on temporal alignment, which achieves further improvements and ensures linear time complexity. We perform extensive experiments on five representative VPR datasets. The results show that the proposed method significantly improves the CNN-based methods. Moreover, our method outperforms several state-of-the-art methods while maintaining good run-time performance. This work provides a novel way to boost the performance of CNN methods without any re-training for VPR. The code is available at https://github.com/Lu-Feng/STA-VPR.
* Accepted for publication in IEEE RA-L 2021
Recognizing Micro-expression in Video Clip with Adaptive Key-frame Mining
Sep 19, 2020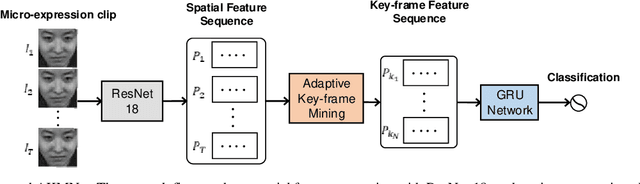
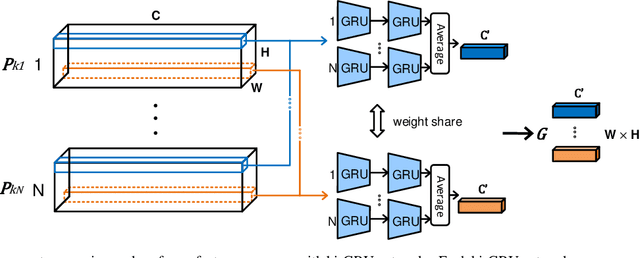
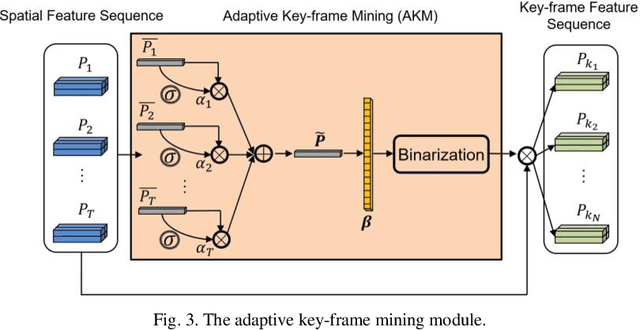
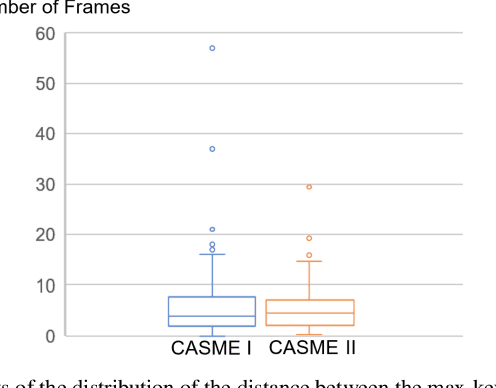
As a spontaneous expression of emotion on face, micro-expression is receiving increasing focus. Whist better recognition accuracy is achieved by various deep learning (DL) techniques, one characteristic of micro-expression has been not fully leveraged. That is, such facial movement is transient and sparsely localized through time. Therefore, the representation learned from a long video clip is usually redundant. On the other hand, methods utilizing the single apex frame require manual annotations and sacrifice the temporal dynamic information. To simultaneously spot and recognize such fleeting facial movement, we propose a novel end-to-end deep learning architecture, referred to as Adaptive Key-frame Mining Network (AKMNet). Operating on the raw video clip of micro-expression, AKMNet is able to learn discriminative spatio-temporal representation by combining the spatial feature of self-exploited local key frames and their global-temporal dynamics. Empirical and theoretical evaluations show advantages of the proposed approach with improved performance comparing with other state-of-the-art methods.