 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFINE-CONTROL: A Semi-supervised Distillation Method For Conditional Image Generation
Sep 26, 2025Conditional image generation models have achieved remarkable results by leveraging text-based control to generate customized images. However, the high resource demands of these models and the scarcity of well-annotated data have hindered their deployment on edge devices, leading to enormous costs and privacy concerns, especially when user data is sent to a third party. To overcome these challenges, we propose Refine-Control, a semi-supervised distillation framework. Specifically, we improve the performance of the student model by introducing a tri-level knowledge fusion loss to transfer different levels of knowledge. To enhance generalization and alleviate dataset scarcity, we introduce a semi-supervised distillation method utilizing both labeled and unlabeled data. Our experiments reveal that Refine-Control achieves significant reductions in computational cost and latency, while maintaining high-fidelity generation capabilities and controllability, as quantified by comparative metrics.
Enriching Knowledge Distillation with Intra-Class Contrastive Learning
Sep 26, 2025Since the advent of knowledge distillation, much research has focused on how the soft labels generated by the teacher model can be utilized effectively. Existing studies points out that the implicit knowledge within soft labels originates from the multi-view structure present in the data. Feature variations within samples of the same class allow the student model to generalize better by learning diverse representations. However, in existing distillation methods, teacher models predominantly adhere to ground-truth labels as targets, without considering the diverse representations within the same class. Therefore, we propose incorporating an intra-class contrastive loss during teacher training to enrich the intra-class information contained in soft labels. In practice, we find that intra-class loss causes instability in training and slows convergence. To mitigate these issues, margin loss is integrated into intra-class contrastive learning to improve the training stability and convergence speed. Simultaneously, we theoretically analyze the impact of this loss on the intra-class distances and inter-class distances. It has been proved that the intra-class contrastive loss can enrich the intra-class diversity. Experimental results demonstrate the effectiveness of the proposed method.
Towards Understanding Feature Learning in Parameter Transfer
Sep 26, 2025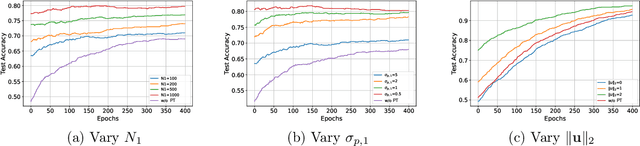
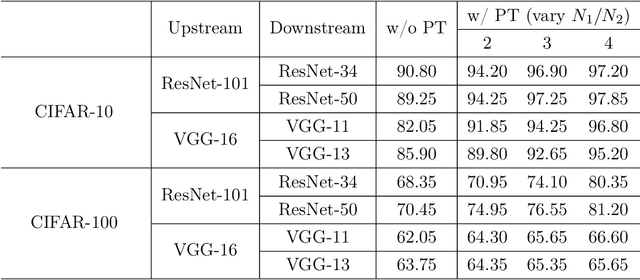
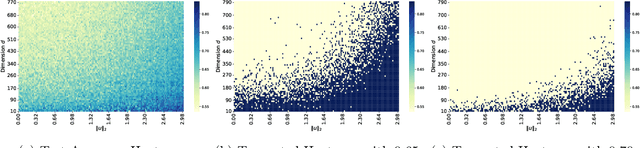
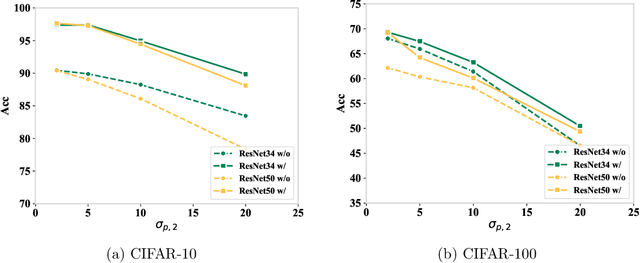
Parameter transfer is a central paradigm in transfer learning, enabling knowledge reuse across tasks and domains by sharing model parameters between upstream and downstream models. However, when only a subset of parameters from the upstream model is transferred to the downstream model, there remains a lack of theoretical understanding of the conditions under which such partial parameter reuse is beneficial and of the factors that govern its effectiveness. To address this gap, we analyze a setting in which both the upstream and downstream models are ReLU convolutional neural networks (CNNs). Within this theoretical framework, we characterize how the inherited parameters act as carriers of universal knowledge and identify key factors that amplify their beneficial impact on the target task. Furthermore, our analysis provides insight into why, in certain cases, transferring parameters can lead to lower test accuracy on the target task than training a new model from scratch. Numerical experiments and real-world data experiments are conducted to empirically validate our theoretical findings.
Unreliable Partial Label Learning with Recursive Separation
Feb 20, 2023Partial label learning (PLL) is a typical weakly supervised learning problem in which each instance is associated with a candidate label set, and among which only one is true. However, the assumption that the ground-truth label is always among the candidate label set would be unrealistic, as the reliability of the candidate label sets in real-world applications cannot be guaranteed by annotators. Therefore, a generalized PLL named Unreliable Partial Label Learning (UPLL) is proposed, in which the true label may not be in the candidate label set. Due to the challenges posed by unreliable labeling, previous PLL methods will experience a marked decline in performance when applied to UPLL. To address the issue, we propose a two-stage framework named Unreliable Partial Label Learning with Recursive Separation (UPLLRS). In the first stage, the self-adaptive recursive separation strategy is proposed to separate the training set into a reliable subset and an unreliable subset. In the second stage, a disambiguation strategy is employed to progressively identify the ground-truth labels in the reliable subset. Simultaneously, semi-supervised learning methods are adopted to extract valuable information from the unreliable subset. Our method demonstrates state-of-the-art performance as evidenced by experimental results, particularly in situations of high unreliability.
Learning From Biased Soft Labels
Feb 16, 2023



Knowledge distillation has been widely adopted in a variety of tasks and has achieved remarkable successes. Since its inception, many researchers have been intrigued by the dark knowledge hidden in the outputs of the teacher model. Recently, a study has demonstrated that knowledge distillation and label smoothing can be unified as learning from soft labels. Consequently, how to measure the effectiveness of the soft labels becomes an important question. Most existing theories have stringent constraints on the teacher model or data distribution, and many assumptions imply that the soft labels are close to the ground-truth labels. This paper studies whether biased soft labels are still effective. We present two more comprehensive indicators to measure the effectiveness of such soft labels. Based on the two indicators, we give sufficient conditions to ensure biased soft label based learners are classifier-consistent and ERM learnable. The theory is applied to three weakly-supervised frameworks. Experimental results validate that biased soft labels can also teach good students, which corroborates the soundness of the theory.