 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-Text Modeling with Zero-Shot Transfer from Contrastive Captioners
Dec 09, 2022



This work explores an efficient approach to establish a foundational video-text model for tasks including open-vocabulary video classification, text-to-video retrieval, video captioning and video question-answering. We present VideoCoCa that reuses a pretrained image-text contrastive captioner (CoCa) model and adapt it to video-text tasks with minimal extra training. While previous works adapt image-text models with various cross-frame fusion modules (for example, cross-frame attention layer or perceiver resampler) and finetune the modified architecture on video-text data, we surprisingly find that the generative attentional pooling and contrastive attentional pooling layers in the image-text CoCa design are instantly adaptable to ``flattened frame embeddings'', yielding a strong zero-shot transfer baseline for many video-text tasks. Specifically, the frozen image encoder of a pretrained image-text CoCa takes each video frame as inputs and generates \(N\) token embeddings per frame for totally \(T\) video frames. We flatten \(N \times T\) token embeddings as a long sequence of frozen video representation and apply CoCa's generative attentional pooling and contrastive attentional pooling on top. All model weights including pooling layers are directly loaded from an image-text CoCa pretrained model. Without any video or video-text data, VideoCoCa's zero-shot transfer baseline already achieves state-of-the-art results on zero-shot video classification on Kinetics 400/600/700, UCF101, HMDB51, and Charades, as well as zero-shot text-to-video retrieval on MSR-VTT and ActivityNet Captions. We also explore lightweight finetuning on top of VideoCoCa, and achieve strong results on video question-answering (iVQA, MSRVTT-QA, MSVD-QA) and video captioning (MSR-VTT, ActivityNet, Youcook2). Our approach establishes a simple and effective video-text baseline for future research.
SODA: A Natural Language Processing Package to Extract Social Determinants of Health for Cancer Studies
Dec 06, 2022



Objective: We aim to develop an open-source natural language processing (NLP) package, SODA (i.e., SOcial DeterminAnts), with pre-trained transformer models to extract social determinants of health (SDoH) for cancer patients, examine the generalizability of SODA to a new disease domain (i.e., opioid use), and evaluate the extraction rate of SDoH using cancer populations. Methods: We identified SDoH categories and attributes and developed an SDoH corpus using clinical notes from a general cancer cohort. We compared four transformer-based NLP models to extract SDoH, examined the generalizability of NLP models to a cohort of patients prescribed with opioids, and explored customization strategies to improve performance. We applied the best NLP model to extract 19 categories of SDoH from the breast (n=7,971), lung (n=11,804), and colorectal cancer (n=6,240) cohorts. Results and Conclusion: We developed a corpus of 629 cancer patients notes with annotations of 13,193 SDoH concepts/attributes from 19 categories of SDoH. The Bidirectional Encoder Representations from Transformers (BERT) model achieved the best strict/lenient F1 scores of 0.9216 and 0.9441 for SDoH concept extraction, 0.9617 and 0.9626 for linking attributes to SDoH concepts. Fine-tuning the NLP models using new annotations from opioid use patients improved the strict/lenient F1 scores from 0.8172/0.8502 to 0.8312/0.8679. The extraction rates among 19 categories of SDoH varied greatly, where 10 SDoH could be extracted from >70% of cancer patients, but 9 SDoH had a low extraction rate (<70% of cancer patients). The SODA package with pre-trained transformer models is publicly available at https://github.com/uf-hobiinformatics-lab/SDoH_SODA.
Training Text-To-Speech Systems From Synthetic Data: A Practical Approach For Accent Transfer Tasks
Aug 28, 2022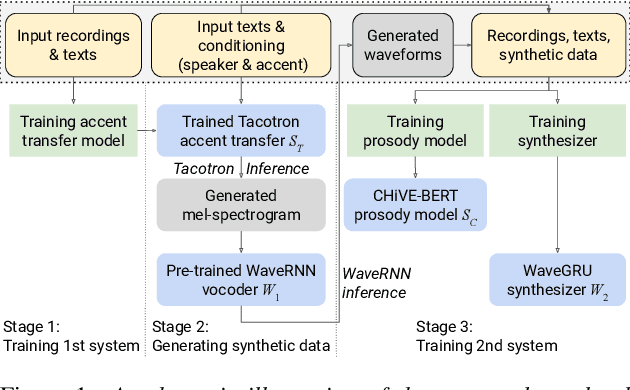
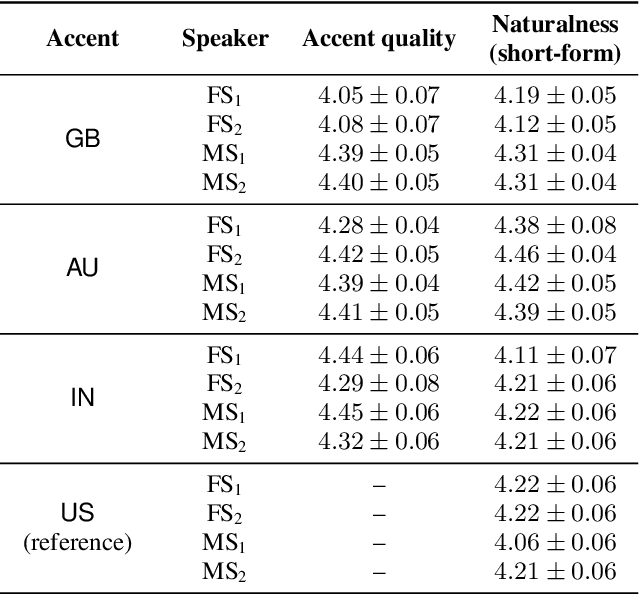
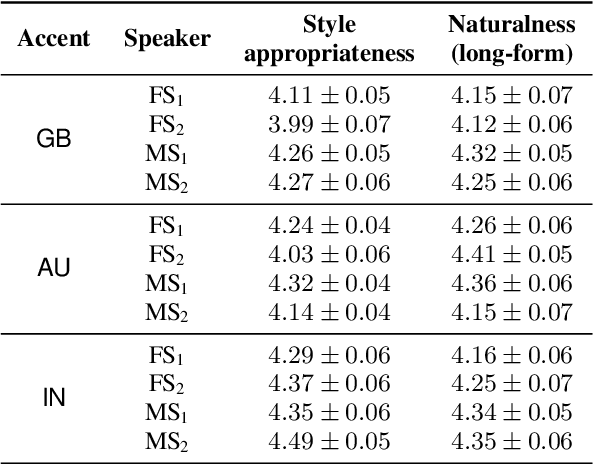
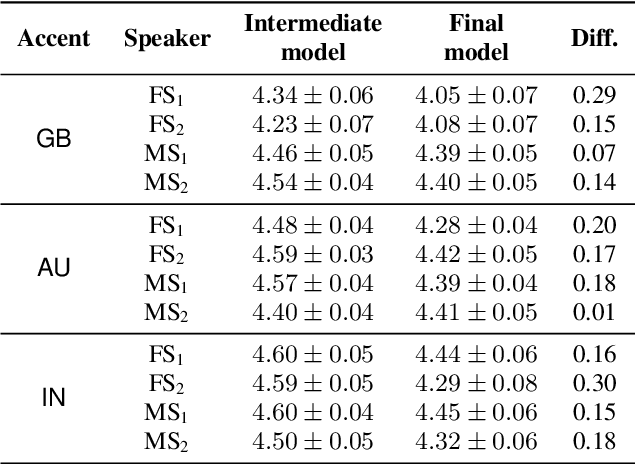
Transfer tasks in text-to-speech (TTS) synthesis - where one or more aspects of the speech of one set of speakers is transferred to another set of speakers that do not feature these aspects originally - remains a challenging task. One of the challenges is that models that have high-quality transfer capabilities can have issues in stability, making them impractical for user-facing critical tasks. This paper demonstrates that transfer can be obtained by training a robust TTS system on data generated by a less robust TTS system designed for a high-quality transfer task; in particular, a CHiVE-BERT monolingual TTS system is trained on the output of a Tacotron model designed for accent transfer. While some quality loss is inevitable with this approach, experimental results show that the models trained on synthetic data this way can produce high quality audio displaying accent transfer, while preserving speaker characteristics such as speaking style.
N-Grammer: Augmenting Transformers with latent n-grams
Jul 13, 2022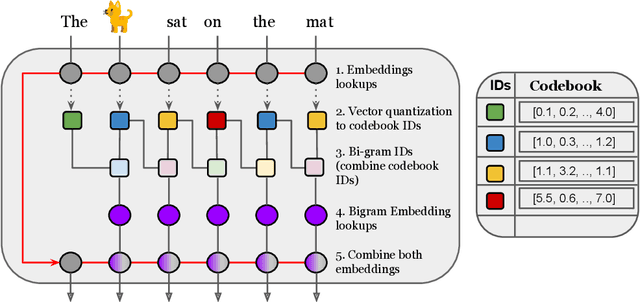
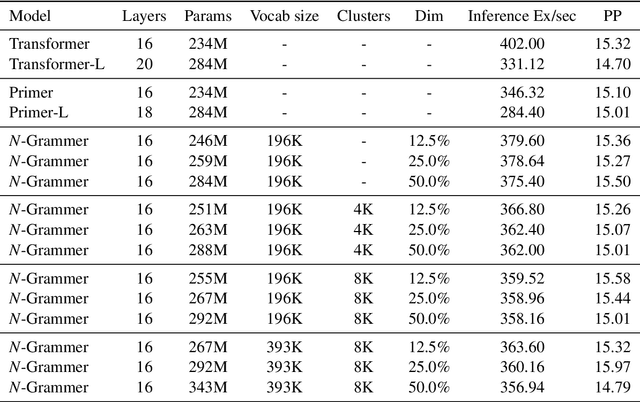

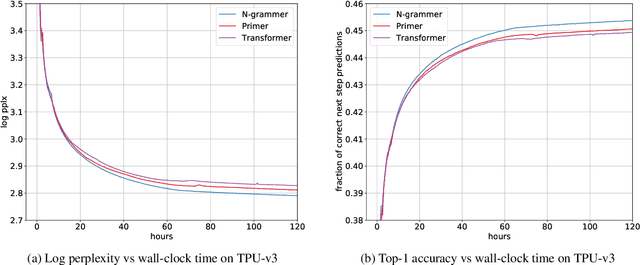
Transformer models have recently emerged as one of the foundational models in natural language processing, and as a byproduct, there is significant recent interest and investment in scaling these models. However, the training and inference costs of these large Transformer language models are prohibitive, thus necessitating more research in identifying more efficient variants. In this work, we propose a simple yet effective modification to the Transformer architecture inspired by the literature in statistical language modeling, by augmenting the model with n-grams that are constructed from a discrete latent representation of the text sequence. We evaluate our model, the N-Grammer on language modeling on the C4 data-set as well as text classification on the SuperGLUE data-set, and find that it outperforms several strong baselines such as the Transformer and the Primer. We open-source our model for reproducibility purposes in Jax.
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jun 22, 2022

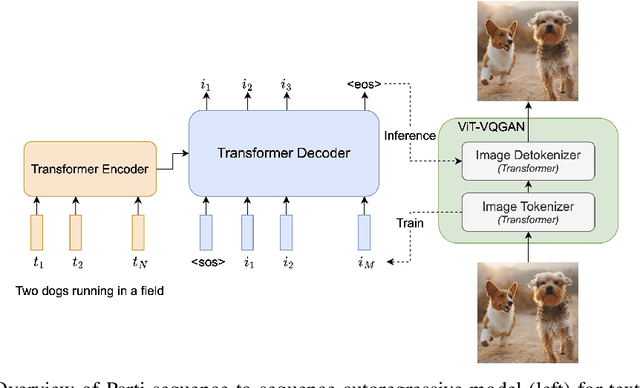
We present the Pathways Autoregressive Text-to-Image (Parti) model, which generates high-fidelity photorealistic images and supports content-rich synthesis involving complex compositions and world knowledge. Parti treats text-to-image generation as a sequence-to-sequence modeling problem, akin to machine translation, with sequences of image tokens as the target outputs rather than text tokens in another language. This strategy can naturally tap into the rich body of prior work on large language models, which have seen continued advances in capabilities and performance through scaling data and model sizes. Our approach is simple: First, Parti uses a Transformer-based image tokenizer, ViT-VQGAN, to encode images as sequences of discrete tokens. Second, we achieve consistent quality improvements by scaling the encoder-decoder Transformer model up to 20B parameters, with a new state-of-the-art zero-shot FID score of 7.23 and finetuned FID score of 3.22 on MS-COCO. Our detailed analysis on Localized Narratives as well as PartiPrompts (P2), a new holistic benchmark of over 1600 English prompts, demonstrate the effectiveness of Parti across a wide variety of categories and difficulty aspects. We also explore and highlight limitations of our models in order to define and exemplify key areas of focus for further improvements. See https://parti.research.google/ for high-resolution images.
Building Machine Translation Systems for the Next Thousand Languages
May 16, 2022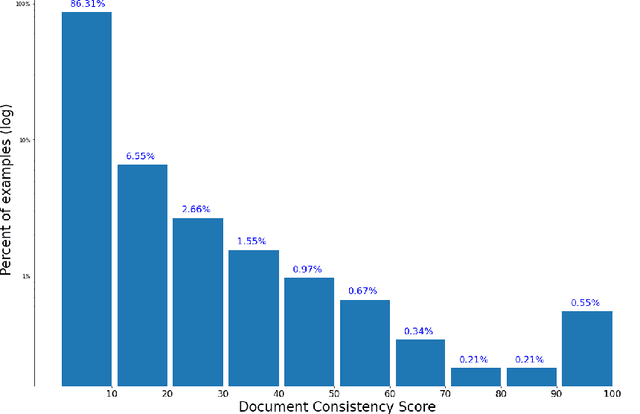
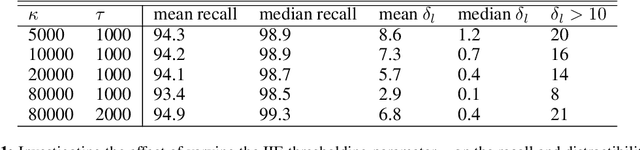

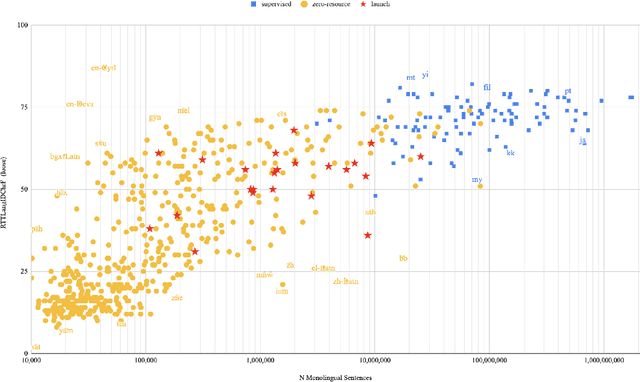
In this paper we share findings from our effort to build practical machine translation (MT) systems capable of translating across over one thousand languages. We describe results in three research domains: (i) Building clean, web-mined datasets for 1500+ languages by leveraging semi-supervised pre-training for language identification and developing data-driven filtering techniques; (ii) Developing practical MT models for under-served languages by leveraging massively multilingual models trained with supervised parallel data for over 100 high-resource languages and monolingual datasets for an additional 1000+ languages; and (iii) Studying the limitations of evaluation metrics for these languages and conducting qualitative analysis of the outputs from our MT models, highlighting several frequent error modes of these types of models. We hope that our work provides useful insights to practitioners working towards building MT systems for currently understudied languages, and highlights research directions that can complement the weaknesses of massively multilingual models in data-sparse settings.
CoCa: Contrastive Captioners are Image-Text Foundation Models
May 04, 2022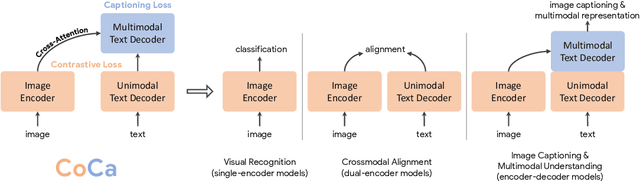

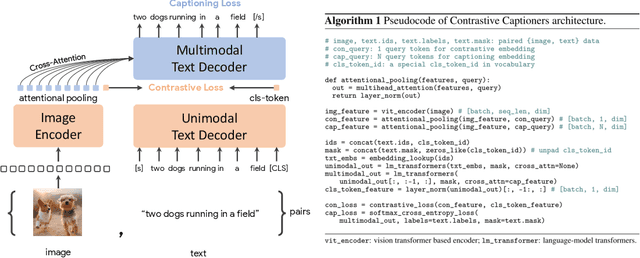
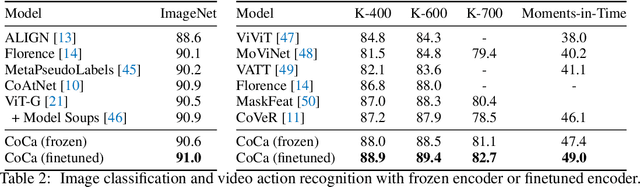
Exploring large-scale pretrained foundation models is of significant interest in computer vision because these models can be quickly transferred to many downstream tasks. This paper presents Contrastive Captioner (CoCa), a minimalist design to pretrain an image-text encoder-decoder foundation model jointly with contrastive loss and captioning loss, thereby subsuming model capabilities from contrastive approaches like CLIP and generative methods like SimVLM. In contrast to standard encoder-decoder transformers where all decoder layers attend to encoder outputs, CoCa omits cross-attention in the first half of decoder layers to encode unimodal text representations, and cascades the remaining decoder layers which cross-attend to the image encoder for multimodal image-text representations. We apply a contrastive loss between unimodal image and text embeddings, in addition to a captioning loss on the multimodal decoder outputs which predicts text tokens autoregressively. By sharing the same computational graph, the two training objectives are computed efficiently with minimal overhead. CoCa is pretrained end-to-end and from scratch on both web-scale alt-text data and annotated images by treating all labels simply as text, seamlessly unifying natural language supervision for representation learning. Empirically, CoCa achieves state-of-the-art performance with zero-shot transfer or minimal task-specific adaptation on a broad range of downstream tasks, spanning visual recognition (ImageNet, Kinetics-400/600/700, Moments-in-Time), crossmodal retrieval (MSCOCO, Flickr30K, MSR-VTT), multimodal understanding (VQA, SNLI-VE, NLVR2), and image captioning (MSCOCO, NoCaps). Notably on ImageNet classification, CoCa obtains 86.3% zero-shot top-1 accuracy, 90.6% with a frozen encoder and learned classification head, and new state-of-the-art 91.0% top-1 accuracy on ImageNet with a finetuned encoder.
Show, Don't Tell: Demonstrations Outperform Descriptions for Schema-Guided Task-Oriented Dialogue
Apr 08, 2022
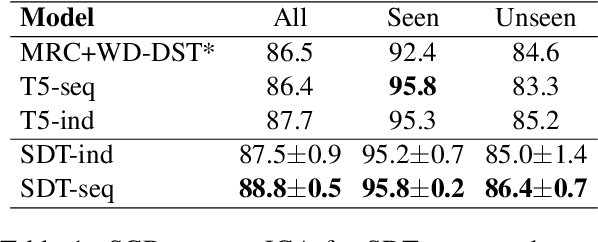
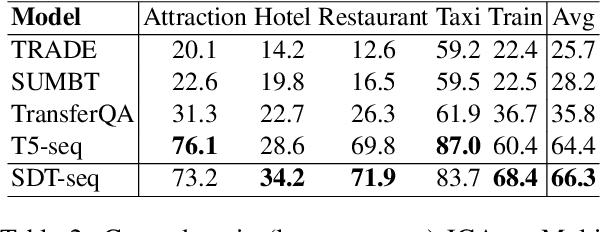

Building universal dialogue systems that can seamlessly operate across multiple domains/APIs and generalize to new ones with minimal supervision and maintenance is a critical challenge. Recent works have leveraged natural language descriptions for schema elements to enable such systems; however, descriptions can only indirectly convey schema semantics. In this work, we propose Show, Don't Tell, a prompt format for seq2seq modeling which uses a short labeled example dialogue to show the semantics of schema elements rather than tell the model via descriptions. While requiring similar effort from service developers, we show that using short examples as schema representations with large language models results in stronger performance and better generalization on two popular dialogue state tracking benchmarks: the Schema-Guided Dialogue dataset and the MultiWoZ leave-one-out benchmark.
Pathways: Asynchronous Distributed Dataflow for ML
Mar 23, 2022
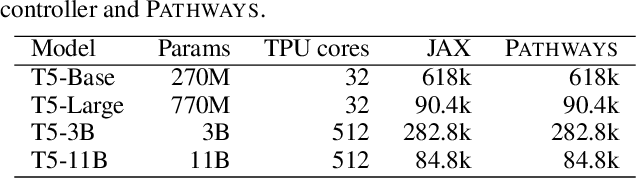
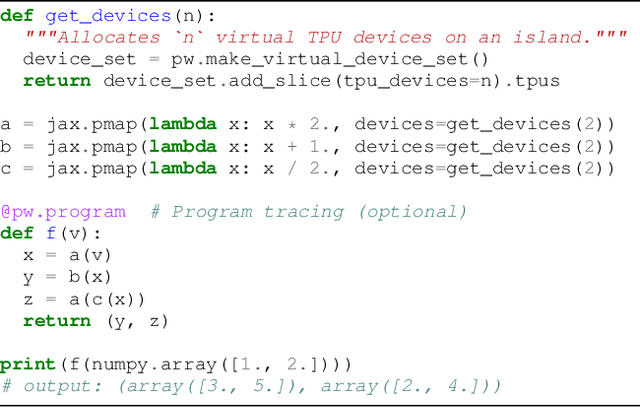
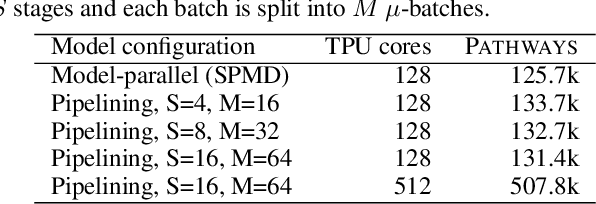
We present the design of a new large scale orchestration layer for accelerators. Our system, Pathways, is explicitly designed to enable exploration of new systems and ML research ideas, while retaining state of the art performance for current models. Pathways uses a sharded dataflow graph of asynchronous operators that consume and produce futures, and efficiently gang-schedules heterogeneous parallel computations on thousands of accelerators while coordinating data transfers over their dedicated interconnects. Pathways makes use of a novel asynchronous distributed dataflow design that lets the control plane execute in parallel despite dependencies in the data plane. This design, with careful engineering, allows Pathways to adopt a single-controller model that makes it easier to express complex new parallelism patterns. We demonstrate that Pathways can achieve performance parity (~100% accelerator utilization) with state-of-the-art systems when running SPMD computations over 2048 TPUs, while also delivering throughput comparable to the SPMD case for Transformer models that are pipelined across 16 stages, or sharded across two islands of accelerators connected over a data center network.
Self-supervised Learning with Random-projection Quantizer for Speech Recognition
Feb 03, 2022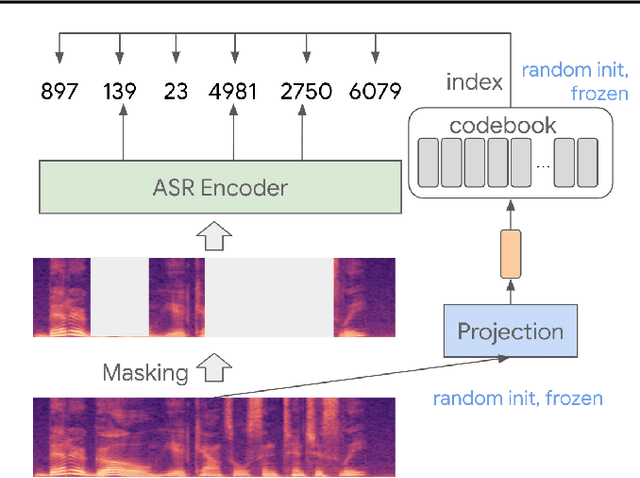

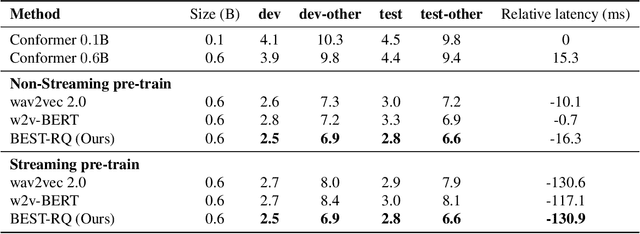
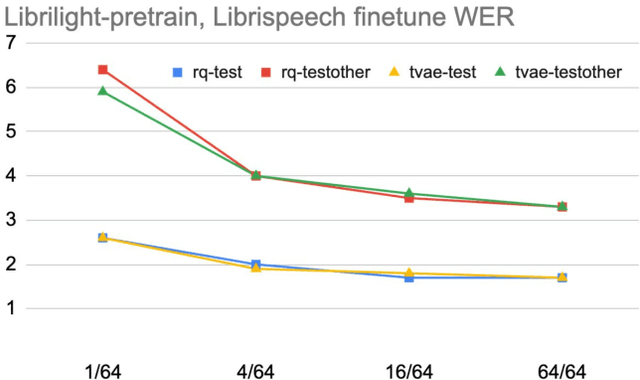
We present a simple and effective self-supervised learning approach for speech recognition. The approach learns a model to predict the masked speech signals, in the form of discrete labels generated with a random-projection quantizer. In particular the quantizer projects speech inputs with a randomly initialized matrix, and does a nearest-neighbor lookup in a randomly-initialized codebook. Neither the matrix nor the codebook is updated during self-supervised learning. Since the random-projection quantizer is not trained and is separated from the speech recognition model, the design makes the approach flexible and is compatible with universal speech recognition architecture. On LibriSpeech our approach achieves similar word-error-rates as previous work using self-supervised learning with non-streaming models, and provides lower word-error-rates and latency than wav2vec 2.0 and w2v-BERT with streaming models. On multilingual tasks the approach also provides significant improvement over wav2vec 2.0 and w2v-BERT.