 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnlineHMR: Video-based Online World-Grounded Human Mesh Recovery
Mar 18, 2026Human mesh recovery (HMR) models 3D human body from monocular videos, with recent works extending it to world-coordinate human trajectory and motion reconstruction. However, most existing methods remain offline, relying on future frames or global optimization, which limits their applicability in interactive feedback and perception-action loop scenarios such as AR/VR and telepresence. To address this, we propose OnlineHMR, a fully online framework that jointly satisfies four essential criteria of online processing, including system-level causality, faithfulness, temporal consistency, and efficiency. Built upon a two-branch architecture, OnlineHMR enables streaming inference via a causal key-value cache design and a curated sliding-window learning strategy. Meanwhile, a human-centric incremental SLAM provides online world-grounded alignment under physically plausible trajectory correction. Experimental results show that our method achieves performance comparable to existing chunk-based approaches on the standard EMDB benchmark and highly dynamic custom videos, while uniquely supporting online processing. Page and code are available at https://tsukasane.github.io/Video-OnlineHMR/.
Behavioral Consistency Validation for LLM Agents: An Analysis of Trading-Style Switching through Stock-Market Simulation
Feb 02, 2026Recent works have increasingly applied Large Language Models (LLMs) as agents in financial stock market simulations to test if micro-level behaviors aggregate into macro-level phenomena. However, a crucial question arises: Do LLM agents' behaviors align with real market participants? This alignment is key to the validity of simulation results. To explore this, we select a financial stock market scenario to test behavioral consistency. Investors are typically classified as fundamental or technical traders, but most simulations fix strategies at initialization, failing to reflect real-world trading dynamics. In this work, we assess whether agents' strategy switching aligns with financial theory, providing a framework for this evaluation. We operationalize four behavioral-finance drivers-loss aversion, herding, wealth differentiation, and price misalignment-as personality traits set via prompting and stored long-term. In year-long simulations, agents process daily price-volume data, trade under a designated style, and reassess their strategy every 10 trading days. We introduce four alignment metrics and use Mann-Whitney U tests to compare agents' style-switching behavior with financial theory. Our results show that recent LLMs' switching behavior is only partially consistent with behavioral-finance theories, highlighting the need for further refinement in aligning agent behavior with financial theory.
Rethinking the Role of Entropy in Optimizing Tool-Use Behaviors for Large Language Model Agents
Feb 02, 2026Tool-using agents based on Large Language Models (LLMs) excel in tasks such as mathematical reasoning and multi-hop question answering. However, in long trajectories, agents often trigger excessive and low-quality tool calls, increasing latency and degrading inference performance, making managing tool-use behavior challenging. In this work, we conduct entropy-based pilot experiments and observe a strong positive correlation between entropy reduction and high-quality tool calls. Building on this finding, we propose using entropy reduction as a supervisory signal and design two reward strategies to address the differing needs of optimizing tool-use behavior. Sparse outcome rewards provide coarse, trajectory-level guidance to improve efficiency, while dense process rewards offer fine-grained supervision to enhance performance. Experiments across diverse domains show that both reward designs improve tool-use behavior: the former reduces tool calls by 72.07% compared to the average of baselines, while the latter improves performance by 22.27%. These results position entropy reduction as a key mechanism for enhancing tool-use behavior, enabling agents to be more adaptive in real-world applications.
CRISP: Contact-Guided Real2Sim from Monocular Video with Planar Scene Primitives
Dec 21, 2025We introduce CRISP, a method that recovers simulatable human motion and scene geometry from monocular video. Prior work on joint human-scene reconstruction relies on data-driven priors and joint optimization with no physics in the loop, or recovers noisy geometry with artifacts that cause motion tracking policies with scene interactions to fail. In contrast, our key insight is to recover convex, clean, and simulation-ready geometry by fitting planar primitives to a point cloud reconstruction of the scene, via a simple clustering pipeline over depth, normals, and flow. To reconstruct scene geometry that might be occluded during interactions, we make use of human-scene contact modeling (e.g., we use human posture to reconstruct the occluded seat of a chair). Finally, we ensure that human and scene reconstructions are physically-plausible by using them to drive a humanoid controller via reinforcement learning. Our approach reduces motion tracking failure rates from 55.2\% to 6.9\% on human-centric video benchmarks (EMDB, PROX), while delivering a 43\% faster RL simulation throughput. We further validate it on in-the-wild videos including casually-captured videos, Internet videos, and even Sora-generated videos. This demonstrates CRISP's ability to generate physically-valid human motion and interaction environments at scale, greatly advancing real-to-sim applications for robotics and AR/VR.
SingMOS-Pro: An Comprehensive Benchmark for Singing Quality Assessment
Oct 02, 2025



Singing voice generation progresses rapidly, yet evaluating singing quality remains a critical challenge. Human subjective assessment, typically in the form of listening tests, is costly and time consuming, while existing objective metrics capture only limited perceptual aspects. In this work, we introduce SingMOS-Pro, a dataset for automatic singing quality assessment. Building on our preview version SingMOS, which provides only overall ratings, SingMOS-Pro expands annotations of the additional part to include lyrics, melody, and overall quality, offering broader coverage and greater diversity. The dataset contains 7,981 singing clips generated by 41 models across 12 datasets, spanning from early systems to recent advances. Each clip receives at least five ratings from professional annotators, ensuring reliability and consistency. Furthermore, we explore how to effectively utilize MOS data annotated under different standards and benchmark several widely used evaluation methods from related tasks on SingMOS-Pro, establishing strong baselines and practical references for future research. The dataset can be accessed at https://huggingface.co/datasets/TangRain/SingMOS-Pro.
ARECHO: Autoregressive Evaluation via Chain-Based Hypothesis Optimization for Speech Multi-Metric Estimation
May 30, 2025Speech signal analysis poses significant challenges, particularly in tasks such as speech quality evaluation and profiling, where the goal is to predict multiple perceptual and objective metrics. For instance, metrics like PESQ (Perceptual Evaluation of Speech Quality), STOI (Short-Time Objective Intelligibility), and MOS (Mean Opinion Score) each capture different aspects of speech quality. However, these metrics often have different scales, assumptions, and dependencies, making joint estimation non-trivial. To address these issues, we introduce ARECHO (Autoregressive Evaluation via Chain-based Hypothesis Optimization), a chain-based, versatile evaluation system for speech assessment grounded in autoregressive dependency modeling. ARECHO is distinguished by three key innovations: (1) a comprehensive speech information tokenization pipeline; (2) a dynamic classifier chain that explicitly captures inter-metric dependencies; and (3) a two-step confidence-oriented decoding algorithm that enhances inference reliability. Experiments demonstrate that ARECHO significantly outperforms the baseline framework across diverse evaluation scenarios, including enhanced speech analysis, speech generation evaluation, and noisy speech evaluation. Furthermore, its dynamic dependency modeling improves interpretability by capturing inter-metric relationships.
ESPnet-SpeechLM: An Open Speech Language Model Toolkit
Feb 21, 2025



We present ESPnet-SpeechLM, an open toolkit designed to democratize the development of speech language models (SpeechLMs) and voice-driven agentic applications. The toolkit standardizes speech processing tasks by framing them as universal sequential modeling problems, encompassing a cohesive workflow of data preprocessing, pre-training, inference, and task evaluation. With ESPnet-SpeechLM, users can easily define task templates and configure key settings, enabling seamless and streamlined SpeechLM development. The toolkit ensures flexibility, efficiency, and scalability by offering highly configurable modules for every stage of the workflow. To illustrate its capabilities, we provide multiple use cases demonstrating how competitive SpeechLMs can be constructed with ESPnet-SpeechLM, including a 1.7B-parameter model pre-trained on both text and speech tasks, across diverse benchmarks. The toolkit and its recipes are fully transparent and reproducible at: https://github.com/espnet/espnet/tree/speechlm.
VERSA: A Versatile Evaluation Toolkit for Speech, Audio, and Music
Dec 23, 2024



In this work, we introduce VERSA, a unified and standardized evaluation toolkit designed for various speech, audio, and music signals. The toolkit features a Pythonic interface with flexible configuration and dependency control, making it user-friendly and efficient. With full installation, VERSA offers 63 metrics with 711 metric variations based on different configurations. These metrics encompass evaluations utilizing diverse external resources, including matching and non-matching reference audio, text transcriptions, and text captions. As a lightweight yet comprehensive toolkit, VERSA is versatile to support the evaluation of a wide range of downstream scenarios. To demonstrate its capabilities, this work highlights example use cases for VERSA, including audio coding, speech synthesis, speech enhancement, singing synthesis, and music generation. The toolkit is available at https://github.com/shinjiwlab/versa.
Guided Time-optimal Model Predictive Control of a Multi-rotor
Jan 08, 2024



Time-optimal control of a multi-rotor remains an open problem due to the under-actuation and nonlinearity of its dynamics, which make it difficult to solve this problem directly. In this paper, the time-optimal control problem of the multi-rotor is studied. Firstly, a thrust limit optimal decomposition method is proposed, which can reasonably decompose the limited thrust into three directions according to the current state and the target state. As a result, the thrust limit constraint is decomposed as a linear constraint. With the linear constraint and decoupled dynamics, a time-optimal guidance trajectory can be obtained. Then, a cost function is defined based on the time-optimal guidance trajectory, which has a quadratic form and can be used to evaluate the time-optimal performance of the system outputs. Finally, based on the cost function, the time-optimal control problem is reformulated as an MPC (Model Predictive Control) problem. The experimental results demonstrate the feasibility and validity of the proposed methods.
* 6 pages, 5 figures
Robot Composite Learning and the Nunchaku Flipping Challenge
Sep 11, 2017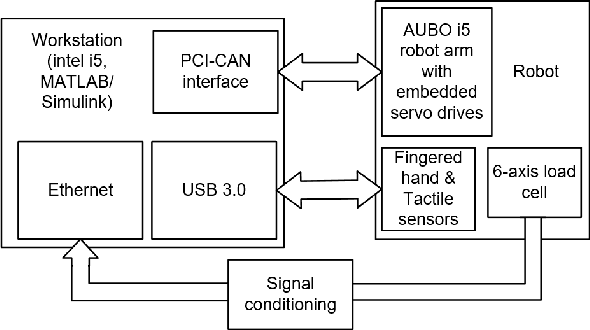



Advanced motor skills are essential for robots to physically coexist with humans. Much research on robot dynamics and control has achieved success on hyper robot motor capabilities, but mostly through heavily case-specific engineering. Meanwhile, in terms of robot acquiring skills in a ubiquitous manner, robot learning from human demonstration (LfD) has achieved great progress, but still has limitations handling dynamic skills and compound actions. In this paper, we present a composite learning scheme which goes beyond LfD and integrates robot learning from human definition, demonstration, and evaluation. The method tackles advanced motor skills that require dynamic time-critical maneuver, complex contact control, and handling partly soft partly rigid objects. We also introduce the "nunchaku flipping challenge", an extreme test that puts hard requirements to all these three aspects. Continued from our previous presentations, this paper introduces the latest update of the composite learning scheme and the physical success of the nunchaku flipping challenge.