 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFish Audio S2 Technical Report
Mar 11, 2026We introduce Fish Audio S2, an open-sourced text-to-speech system featuring multi-speaker, multi-turn generation, and, most importantly, instruction-following control via natural-language descriptions. To scale training, we develop a multi-stage training recipe together with a staged data pipeline covering video captioning and speech captioning, voice-quality assessment, and reward modeling. To push the frontier of open-source TTS, we release our model weights, fine-tuning code, and an SGLang-based inference engine. The inference engine is production-ready for streaming, achieving an RTF of 0.195 and a time-to-first-audio below 100 ms.Our code and weights are available on GitHub (https://github.com/fishaudio/fish-speech) and Hugging Face (https://huggingface.co/fishaudio/s2-pro). We highly encourage readers to visit https://fish.audio to try custom voices.
MOL: Joint Estimation of Micro-Expression, Optical Flow, and Landmark via Transformer-Graph-Style Convolution
Jun 17, 2025
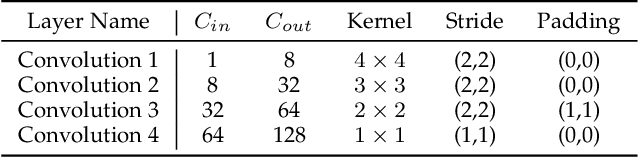


Facial micro-expression recognition (MER) is a challenging problem, due to transient and subtle micro-expression (ME) actions. Most existing methods depend on hand-crafted features, key frames like onset, apex, and offset frames, or deep networks limited by small-scale and low-diversity datasets. In this paper, we propose an end-to-end micro-action-aware deep learning framework with advantages from transformer, graph convolution, and vanilla convolution. In particular, we propose a novel F5C block composed of fully-connected convolution and channel correspondence convolution to directly extract local-global features from a sequence of raw frames, without the prior knowledge of key frames. The transformer-style fully-connected convolution is proposed to extract local features while maintaining global receptive fields, and the graph-style channel correspondence convolution is introduced to model the correlations among feature patterns. Moreover, MER, optical flow estimation, and facial landmark detection are jointly trained by sharing the local-global features. The two latter tasks contribute to capturing facial subtle action information for MER, which can alleviate the impact of insufficient training data. Extensive experiments demonstrate that our framework (i) outperforms the state-of-the-art MER methods on CASME II, SAMM, and SMIC benchmarks, (ii) works well for optical flow estimation and facial landmark detection, and (iii) can capture facial subtle muscle actions in local regions associated with MEs. The code is available at https://github.com/CYF-cuber/MOL.
ARECHO: Autoregressive Evaluation via Chain-Based Hypothesis Optimization for Speech Multi-Metric Estimation
May 30, 2025Speech signal analysis poses significant challenges, particularly in tasks such as speech quality evaluation and profiling, where the goal is to predict multiple perceptual and objective metrics. For instance, metrics like PESQ (Perceptual Evaluation of Speech Quality), STOI (Short-Time Objective Intelligibility), and MOS (Mean Opinion Score) each capture different aspects of speech quality. However, these metrics often have different scales, assumptions, and dependencies, making joint estimation non-trivial. To address these issues, we introduce ARECHO (Autoregressive Evaluation via Chain-based Hypothesis Optimization), a chain-based, versatile evaluation system for speech assessment grounded in autoregressive dependency modeling. ARECHO is distinguished by three key innovations: (1) a comprehensive speech information tokenization pipeline; (2) a dynamic classifier chain that explicitly captures inter-metric dependencies; and (3) a two-step confidence-oriented decoding algorithm that enhances inference reliability. Experiments demonstrate that ARECHO significantly outperforms the baseline framework across diverse evaluation scenarios, including enhanced speech analysis, speech generation evaluation, and noisy speech evaluation. Furthermore, its dynamic dependency modeling improves interpretability by capturing inter-metric relationships.
Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis
Nov 02, 2024



Text-to-Speech (TTS) systems face ongoing challenges in processing complex linguistic features, handling polyphonic expressions, and producing natural-sounding multilingual speech - capabilities that are crucial for future AI applications. In this paper, we present Fish-Speech, a novel framework that implements a serial fast-slow Dual Autoregressive (Dual-AR) architecture to enhance the stability of Grouped Finite Scalar Vector Quantization (GFSQ) in sequence generation tasks. This architecture improves codebook processing efficiency while maintaining high-fidelity outputs, making it particularly effective for AI interactions and voice cloning. Fish-Speech leverages Large Language Models (LLMs) for linguistic feature extraction, eliminating the need for traditional grapheme-to-phoneme (G2P) conversion and thereby streamlining the synthesis pipeline and enhancing multilingual support. Additionally, we developed FF-GAN through GFSQ to achieve superior compression ratios and near 100\% codebook utilization. Our approach addresses key limitations of current TTS systems while providing a foundation for more sophisticated, context-aware speech synthesis. Experimental results show that Fish-Speech significantly outperforms baseline models in handling complex linguistic scenarios and voice cloning tasks, demonstrating its potential to advance TTS technology in AI applications. The implementation is open source at \href{https://github.com/fishaudio/fish-speech}{https://github.com/fishaudio/fish-speech}.