 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADEPT: RL-Aligned Agentic Decoding of Emotion via Evidence Probing Tools -- From Consensus Learning to Ambiguity-Driven Emotion Reasoning
Feb 13, 2026Speech Large Language Models (SLLMs) enable high-level emotion reasoning but often produce ungrounded, text-biased judgments without verifiable acoustic evidence. In contrast, self-supervised speech encoders such as WavLM provide strong acoustic representations yet remain opaque discriminative models with limited interpretability. To bridge this gap, we introduce ADEPT (Agentic Decoding of Emotion via Evidence Probing Tools), a framework that reframes emotion recognition as a multi-turn inquiry process rather than a single-pass prediction. ADEPT transforms an SLLM into an agent that maintains an evolving candidate emotion set and adaptively invokes dedicated semantic and acoustic probing tools within a structured pipeline of candidate generation, evidence collection, and adjudication. Crucially, ADEPT enables a paradigm shift from consensus learning to ambiguity-driven emotion reasoning. Since human affect exhibits inherent complexity and frequent co-occurrence of emotions, we treat minority annotations as informative perceptual signals rather than discarding them as noise. Finally, we integrate Group Relative Policy Optimization (GRPO) with an Evidence Trust Gate to explicitly couple tool-usage behaviors with prediction quality and enforce evidence-grounded reasoning. Experiments show that ADEPT improves primary emotion accuracy in most settings while substantially improving minor emotion characterization, producing explanations grounded in auditable acoustic and semantic evidence.
RE-LLM: Refining Empathetic Speech-LLM Responses by Integrating Emotion Nuance
Feb 11, 2026With generative AI advancing, empathy in human-AI interaction is essential. While prior work focuses on emotional reflection, emotional exploration, key to deeper engagement, remains overlooked. Existing LLMs rely on text which captures limited emotion nuances. To address this, we propose RE-LLM, a speech-LLM integrating dimensional emotion embeddings and auxiliary learning. Experiments show statistically significant gains in empathy metrics across three datasets. RE-LLM relatively improves the Emotional Reaction score by 14.79% and 6.76% compared to text-only and speech-LLM baselines on ESD. Notably, it raises the Exploration score by 35.42% and 3.91% on IEMOCAP, 139.28% and 9.83% on ESD, and 60.95% and 22.64% on MSP-PODCAST. It also boosts unweighted accuracy by 5.4% on IEMOCAP, 2.3% on ESD, and 6.9% on MSP-PODCAST in speech emotion recognition. These results highlight the enriched emotional understanding and improved empathetic response generation of RE-LLM.
Bagpiper: Solving Open-Ended Audio Tasks via Rich Captions
Feb 05, 2026Current audio foundation models typically rely on rigid, task-specific supervision, addressing isolated factors of audio rather than the whole. In contrast, human intelligence processes audio holistically, seamlessly bridging physical signals with abstract cognitive concepts to execute complex tasks. Grounded in this philosophy, we introduce Bagpiper, an 8B audio foundation model that interprets physical audio via rich captions, i.e., comprehensive natural language descriptions that encapsulate the critical cognitive concepts inherent in the signal (e.g., transcription, audio events). By pre-training on a massive corpus of 600B tokens, the model establishes a robust bidirectional mapping between raw audio and this high-level conceptual space. During fine-tuning, Bagpiper adopts a caption-then-process workflow, simulating an intermediate cognitive reasoning step to solve diverse tasks without task-specific priors. Experimentally, Bagpiper outperforms Qwen-2.5-Omni on MMAU and AIRBench for audio understanding and surpasses CosyVoice3 and TangoFlux in generation quality, capable of synthesizing arbitrary compositions of speech, music, and sound effects. To the best of our knowledge, Bagpiper is among the first works that achieve unified understanding generation for general audio. Model, data, and code are available at Bagpiper Home Page.
Lessons Learnt: Revisit Key Training Strategies for Effective Speech Emotion Recognition in the Wild
Aug 10, 2025In this study, we revisit key training strategies in machine learning often overlooked in favor of deeper architectures. Specifically, we explore balancing strategies, activation functions, and fine-tuning techniques to enhance speech emotion recognition (SER) in naturalistic conditions. Our findings show that simple modifications improve generalization with minimal architectural changes. Our multi-modal fusion model, integrating these optimizations, achieves a valence CCC of 0.6953, the best valence score in Task 2: Emotional Attribute Regression. Notably, fine-tuning RoBERTa and WavLM separately in a single-modality setting, followed by feature fusion without training the backbone extractor, yields the highest valence performance. Additionally, focal loss and activation functions significantly enhance performance without increasing complexity. These results suggest that refining core components, rather than deepening models, leads to more robust SER in-the-wild.
ARECHO: Autoregressive Evaluation via Chain-Based Hypothesis Optimization for Speech Multi-Metric Estimation
May 30, 2025Speech signal analysis poses significant challenges, particularly in tasks such as speech quality evaluation and profiling, where the goal is to predict multiple perceptual and objective metrics. For instance, metrics like PESQ (Perceptual Evaluation of Speech Quality), STOI (Short-Time Objective Intelligibility), and MOS (Mean Opinion Score) each capture different aspects of speech quality. However, these metrics often have different scales, assumptions, and dependencies, making joint estimation non-trivial. To address these issues, we introduce ARECHO (Autoregressive Evaluation via Chain-based Hypothesis Optimization), a chain-based, versatile evaluation system for speech assessment grounded in autoregressive dependency modeling. ARECHO is distinguished by three key innovations: (1) a comprehensive speech information tokenization pipeline; (2) a dynamic classifier chain that explicitly captures inter-metric dependencies; and (3) a two-step confidence-oriented decoding algorithm that enhances inference reliability. Experiments demonstrate that ARECHO significantly outperforms the baseline framework across diverse evaluation scenarios, including enhanced speech analysis, speech generation evaluation, and noisy speech evaluation. Furthermore, its dynamic dependency modeling improves interpretability by capturing inter-metric relationships.
An Attribute-Aligned Strategy for Learning Speech Representation
Jun 05, 2021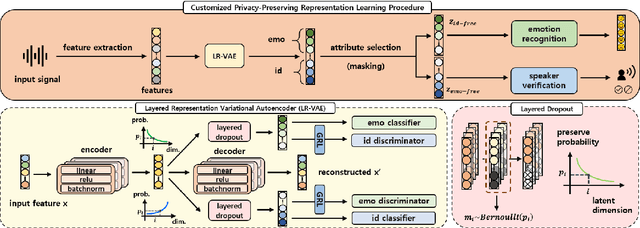
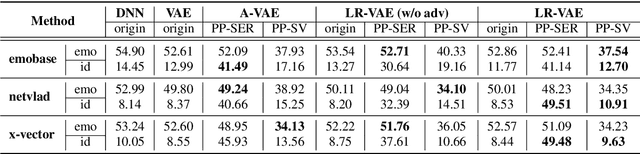
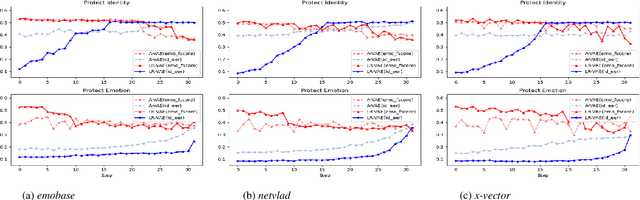
Advancement in speech technology has brought convenience to our life. However, the concern is on the rise as speech signal contains multiple personal attributes, which would lead to either sensitive information leakage or bias toward decision. In this work, we propose an attribute-aligned learning strategy to derive speech representation that can flexibly address these issues by attribute-selection mechanism. Specifically, we propose a layered-representation variational autoencoder (LR-VAE), which factorizes speech representation into attribute-sensitive nodes, to derive an identity-free representation for speech emotion recognition (SER), and an emotionless representation for speaker verification (SV). Our proposed method achieves competitive performances on identity-free SER and a better performance on emotionless SV, comparing to the current state-of-the-art method of using adversarial learning applied on a large emotion corpora, the MSP-Podcast. Also, our proposed learning strategy reduces the model and training process needed to achieve multiple privacy-preserving tasks.