 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Devil in Linear Transformer
Oct 19, 2022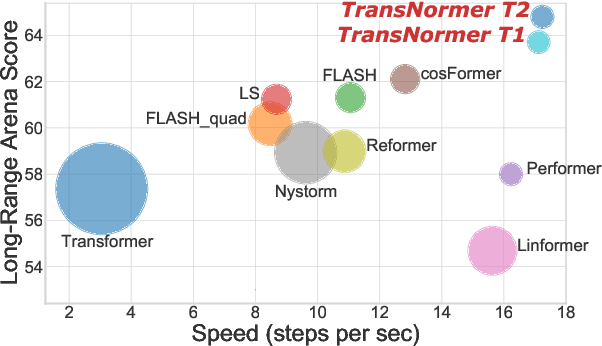



Linear transformers aim to reduce the quadratic space-time complexity of vanilla transformers. However, they usually suffer from degraded performances on various tasks and corpus. In this paper, we examine existing kernel-based linear transformers and identify two key issues that lead to such performance gaps: 1) unbounded gradients in the attention computation adversely impact the convergence of linear transformer models; 2) attention dilution which trivially distributes attention scores over long sequences while neglecting neighbouring structures. To address these issues, we first identify that the scaling of attention matrices is the devil in unbounded gradients, which turns out unnecessary in linear attention as we show theoretically and empirically. To this end, we propose a new linear attention that replaces the scaling operation with a normalization to stabilize gradients. For the issue of attention dilution, we leverage a diagonal attention to confine attention to only neighbouring tokens in early layers. Benefiting from the stable gradients and improved attention, our new linear transformer model, transNormer, demonstrates superior performance on text classification and language modeling tasks, as well as on the challenging Long-Range Arena benchmark, surpassing vanilla transformer and existing linear variants by a clear margin while being significantly more space-time efficient. The code is available at https://github.com/OpenNLPLab/Transnormer .
Linear Video Transformer with Feature Fixation
Oct 15, 2022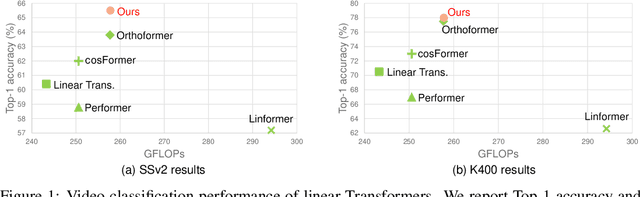
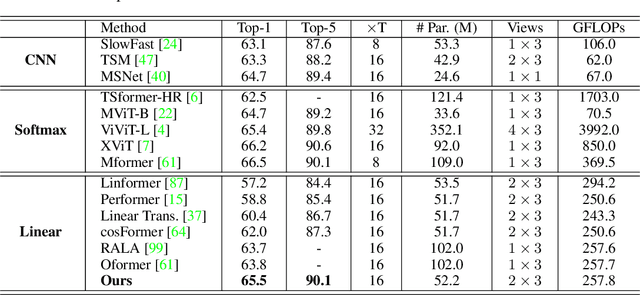

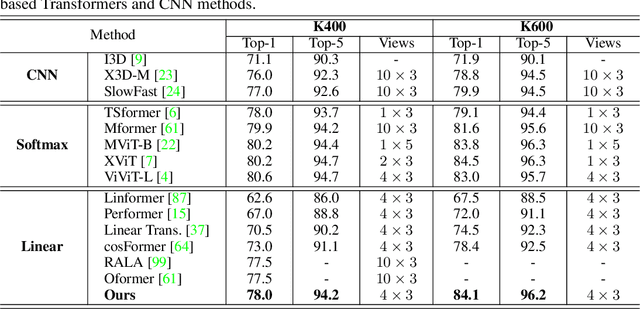
Vision Transformers have achieved impressive performance in video classification, while suffering from the quadratic complexity caused by the Softmax attention mechanism. Some studies alleviate the computational costs by reducing the number of tokens in attention calculation, but the complexity is still quadratic. Another promising way is to replace Softmax attention with linear attention, which owns linear complexity but presents a clear performance drop. We find that such a drop in linear attention results from the lack of attention concentration on critical features. Therefore, we propose a feature fixation module to reweight the feature importance of the query and key before computing linear attention. Specifically, we regard the query, key, and value as various latent representations of the input token, and learn the feature fixation ratio by aggregating Query-Key-Value information. This is beneficial for measuring the feature importance comprehensively. Furthermore, we enhance the feature fixation by neighborhood association, which leverages additional guidance from spatial and temporal neighbouring tokens. The proposed method significantly improves the linear attention baseline and achieves state-of-the-art performance among linear video Transformers on three popular video classification benchmarks. With fewer parameters and higher efficiency, our performance is even comparable to some Softmax-based quadratic Transformers.
Neural Architecture Search on Efficient Transformers and Beyond
Jul 28, 2022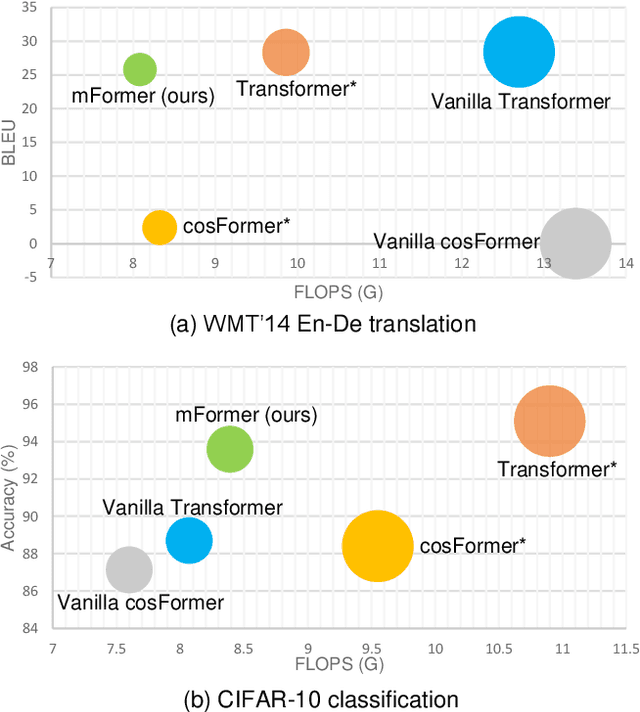
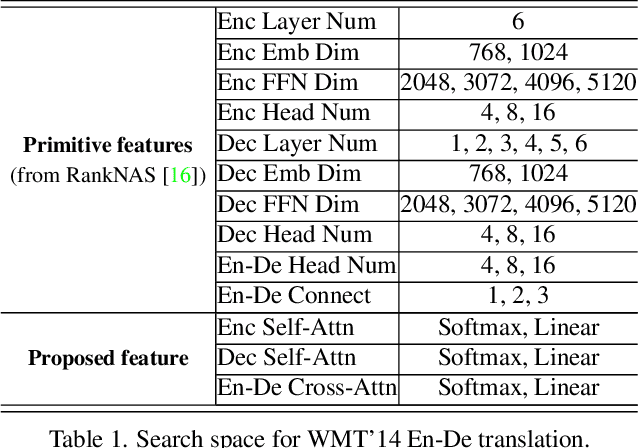


Recently, numerous efficient Transformers have been proposed to reduce the quadratic computational complexity of standard Transformers caused by the Softmax attention. However, most of them simply swap Softmax with an efficient attention mechanism without considering the customized architectures specially for the efficient attention. In this paper, we argue that the handcrafted vanilla Transformer architectures for Softmax attention may not be suitable for efficient Transformers. To address this issue, we propose a new framework to find optimal architectures for efficient Transformers with the neural architecture search (NAS) technique. The proposed method is validated on popular machine translation and image classification tasks. We observe that the optimal architecture of the efficient Transformer has the reduced computation compared with that of the standard Transformer, but the general accuracy is less comparable. It indicates that the Softmax attention and efficient attention have their own distinctions but neither of them can simultaneously balance the accuracy and efficiency well. This motivates us to mix the two types of attention to reduce the performance imbalance. Besides the search spaces that commonly used in existing NAS Transformer approaches, we propose a new search space that allows the NAS algorithm to automatically search the attention variants along with architectures. Extensive experiments on WMT' 14 En-De and CIFAR-10 demonstrate that our searched architecture maintains comparable accuracy to the standard Transformer with notably improved computational efficiency.
AMF: Adaptable Weighting Fusion with Multiple Fine-tuning for Image Classification
Jul 26, 2022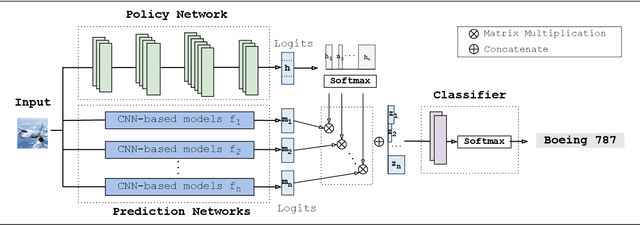
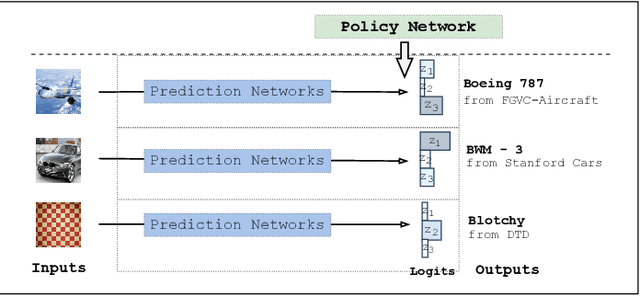
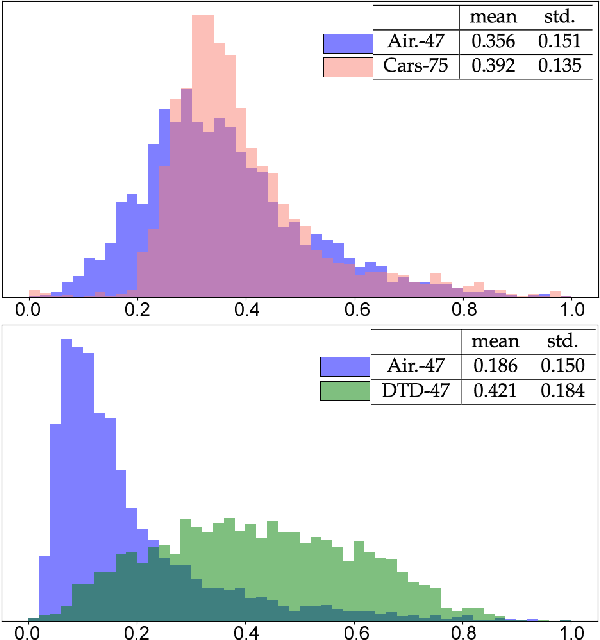
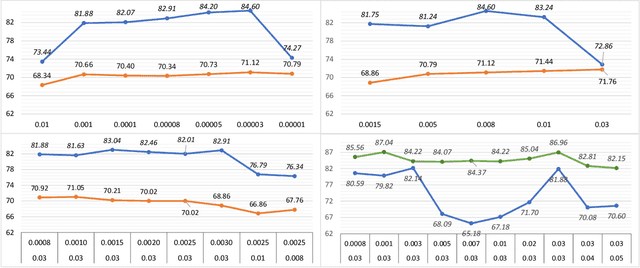
Fine-tuning is widely applied in image classification tasks as a transfer learning approach. It re-uses the knowledge from a source task to learn and obtain a high performance in target tasks. Fine-tuning is able to alleviate the challenge of insufficient training data and expensive labelling of new data. However, standard fine-tuning has limited performance in complex data distributions. To address this issue, we propose the Adaptable Multi-tuning method, which adaptively determines each data sample's fine-tuning strategy. In this framework, multiple fine-tuning settings and one policy network are defined. The policy network in Adaptable Multi-tuning can dynamically adjust to an optimal weighting to feed different samples into models that are trained using different fine-tuning strategies. Our method outperforms the standard fine-tuning approach by 1.69%, 2.79% on the datasets FGVC-Aircraft, and Describable Texture, yielding comparable performance on the datasets Stanford Cars, CIFAR-10, and Fashion-MNIST.
Deep Laparoscopic Stereo Matching with Transformers
Jul 25, 2022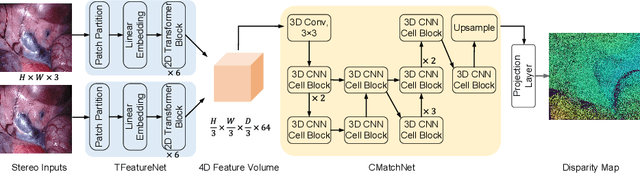

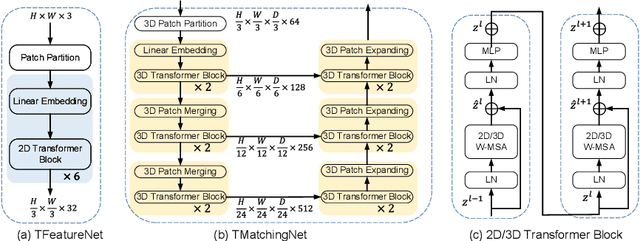
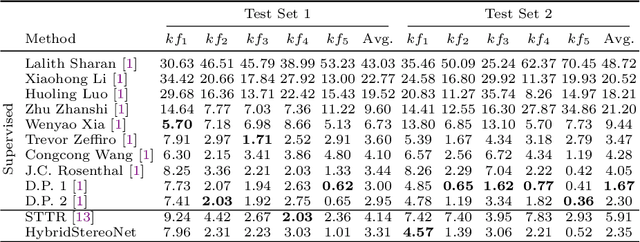
The self-attention mechanism, successfully employed with the transformer structure is shown promise in many computer vision tasks including image recognition, and object detection. Despite the surge, the use of the transformer for the problem of stereo matching remains relatively unexplored. In this paper, we comprehensively investigate the use of the transformer for the problem of stereo matching, especially for laparoscopic videos, and propose a new hybrid deep stereo matching framework (HybridStereoNet) that combines the best of the CNN and the transformer in a unified design. To be specific, we investigate several ways to introduce transformers to volumetric stereo matching pipelines by analyzing the loss landscape of the designs and in-domain/cross-domain accuracy. Our analysis suggests that employing transformers for feature representation learning, while using CNNs for cost aggregation will lead to faster convergence, higher accuracy and better generalization than other options. Our extensive experiments on Sceneflow, SCARED2019 and dVPN datasets demonstrate the superior performance of our HybridStereoNet.
Audio-Visual Segmentation
Jul 11, 2022

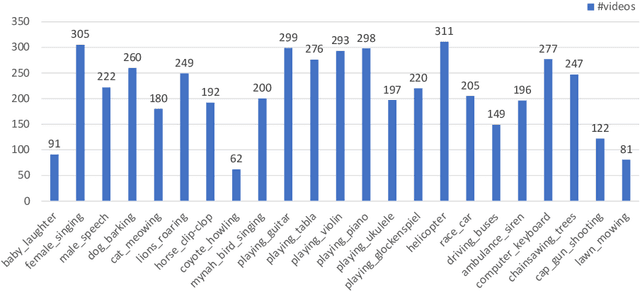
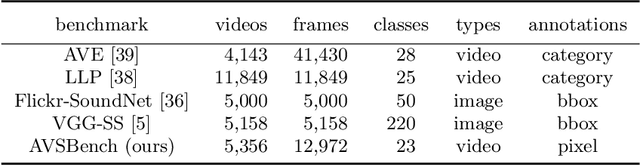
We propose to explore a new problem called audio-visual segmentation (AVS), in which the goal is to output a pixel-level map of the object(s) that produce sound at the time of the image frame. To facilitate this research, we construct the first audio-visual segmentation benchmark (AVSBench), providing pixel-wise annotations for the sounding objects in audible videos. Two settings are studied with this benchmark: 1) semi-supervised audio-visual segmentation with a single sound source and 2) fully-supervised audio-visual segmentation with multiple sound sources. To deal with the AVS problem, we propose a novel method that uses a temporal pixel-wise audio-visual interaction module to inject audio semantics as guidance for the visual segmentation process. We also design a regularization loss to encourage the audio-visual mapping during training. Quantitative and qualitative experiments on the AVSBench compare our approach to several existing methods from related tasks, demonstrating that the proposed method is promising for building a bridge between the audio and pixel-wise visual semantics. Code is available at https://github.com/OpenNLPLab/AVSBench.
Vicinity Vision Transformer
Jun 21, 2022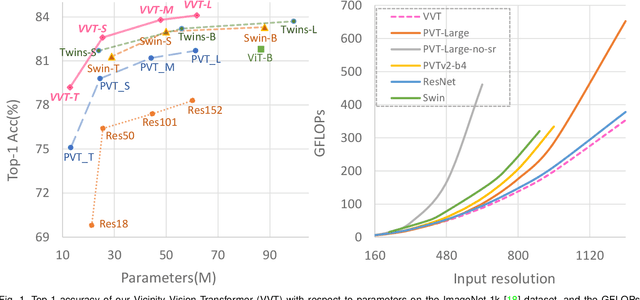
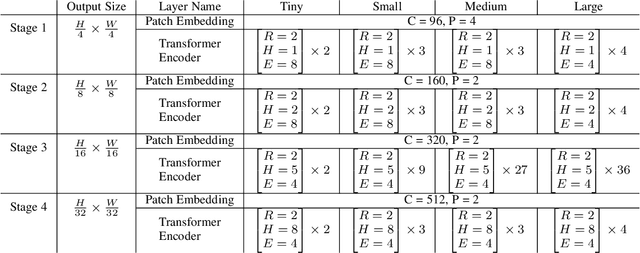
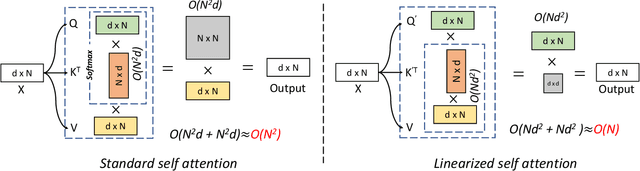
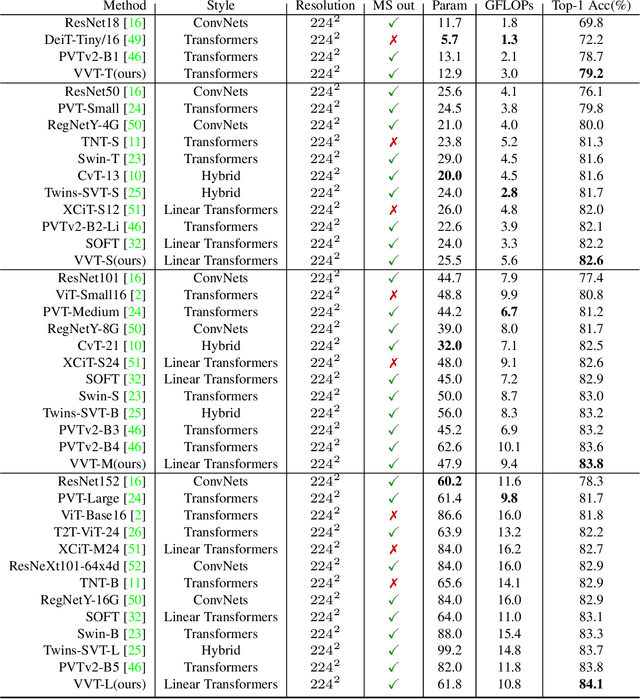
Vision transformers have shown great success on numerous computer vision tasks. However, its central component, softmax attention, prohibits vision transformers from scaling up to high-resolution images, due to both the computational complexity and memory footprint being quadratic. Although linear attention was introduced in natural language processing (NLP) tasks to mitigate a similar issue, directly applying existing linear attention to vision transformers may not lead to satisfactory results. We investigate this problem and find that computer vision tasks focus more on local information compared with NLP tasks. Based on this observation, we present a Vicinity Attention that introduces a locality bias to vision transformers with linear complexity. Specifically, for each image patch, we adjust its attention weight based on its 2D Manhattan distance measured by its neighbouring patches. In this case, the neighbouring patches will receive stronger attention than far-away patches. Moreover, since our Vicinity Attention requires the token length to be much larger than the feature dimension to show its efficiency advantages, we further propose a new Vicinity Vision Transformer (VVT) structure to reduce the feature dimension without degenerating the accuracy. We perform extensive experiments on the CIFAR100, ImageNet1K, and ADE20K datasets to validate the effectiveness of our method. Our method has a slower growth rate of GFlops than previous transformer-based and convolution-based networks when the input resolution increases. In particular, our approach achieves state-of-the-art image classification accuracy with 50% fewer parameters than previous methods.
Deep Non-rigid Structure-from-Motion: A Sequence-to-Sequence Translation Perspective
Apr 10, 2022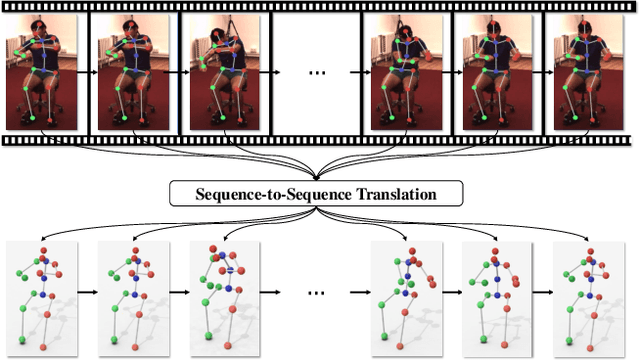
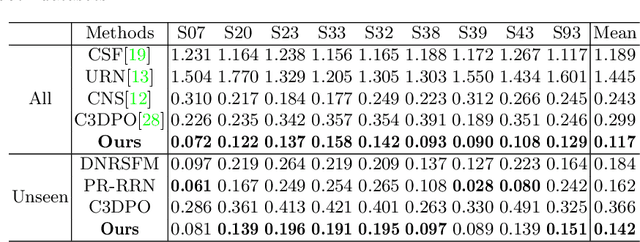
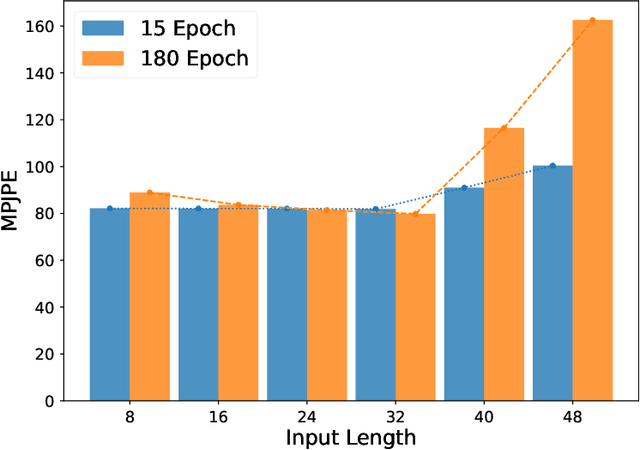
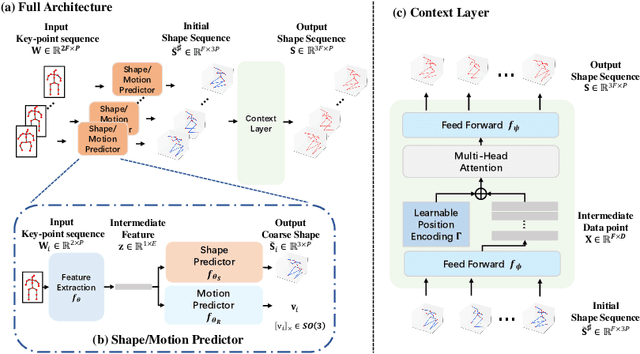
Directly regressing the non-rigid shape and camera pose from the individual 2D frame is ill-suited to the Non-Rigid Structure-from-Motion (NRSfM) problem. This frame-by-frame 3D reconstruction pipeline overlooks the inherent spatial-temporal nature of NRSfM, i.e., reconstructing the whole 3D sequence from the input 2D sequence. In this paper, we propose to model deep NRSfM from a sequence-to-sequence translation perspective, where the input 2D frame sequence is taken as a whole to reconstruct the deforming 3D non-rigid shape sequence. First, we apply a shape-motion predictor to estimate the initial non-rigid shape and camera motion from a single frame. Then we propose a context modeling module to model camera motions and complex non-rigid shapes. To tackle the difficulty in enforcing the global structure constraint within the deep framework, we propose to impose the union-of-subspace structure by replacing the self-expressiveness layer with multi-head attention and delayed regularizers, which enables end-to-end batch-wise training. Experimental results across different datasets such as Human3.6M, CMU Mocap and InterHand prove the superiority of our framework. The code will be made publicly available
Locality Matters: A Locality-Biased Linear Attention for Automatic Speech Recognition
Mar 29, 2022
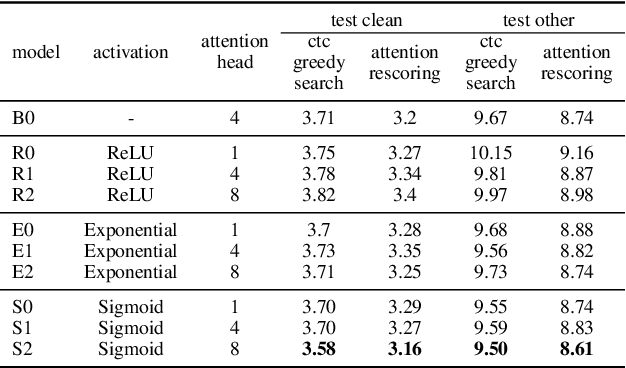
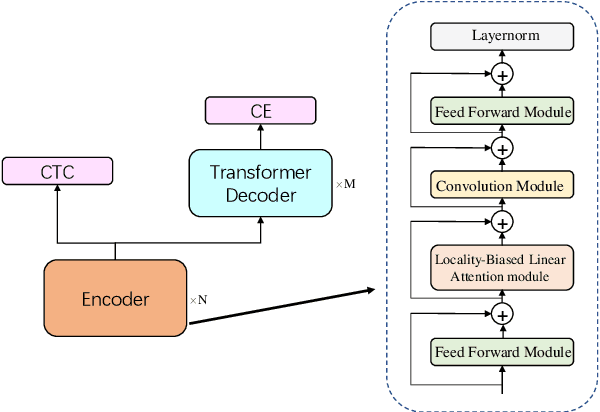
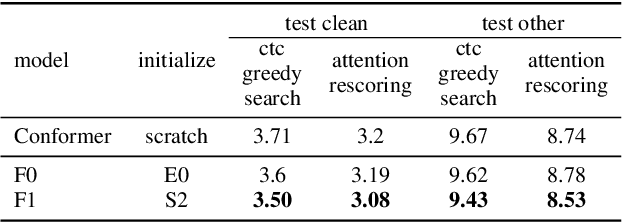
Conformer has shown a great success in automatic speech recognition (ASR) on many public benchmarks. One of its crucial drawbacks is the quadratic time-space complexity with respect to the input sequence length, which prohibits the model to scale-up as well as process longer input audio sequences. To solve this issue, numerous linear attention methods have been proposed. However, these methods often have limited performance on ASR as they treat tokens equally in modeling, neglecting the fact that the neighbouring tokens are often more connected than the distanced tokens. In this paper, we take this fact into account and propose a new locality-biased linear attention for Conformer. It not only achieves higher accuracy than the vanilla Conformer, but also enjoys linear space-time computational complexity. To be specific, we replace the softmax attention with a locality-biased linear attention (LBLA) mechanism in Conformer blocks. The LBLA contains a kernel function to ensure the linear complexities and a cosine reweighing matrix to impose more weights on neighbouring tokens. Extensive experiments on the LibriSpeech corpus show that by introducing this locality bias to the Conformer, our method achieves a lower word error rate with more than 22% inference speed.
Implicit Motion Handling for Video Camouflaged Object Detection
Mar 15, 2022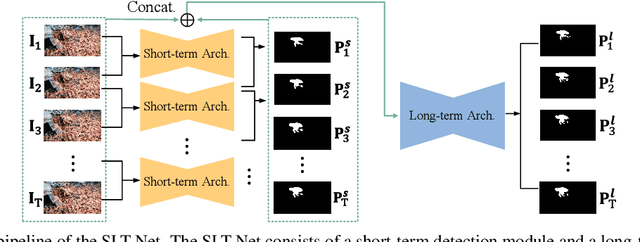
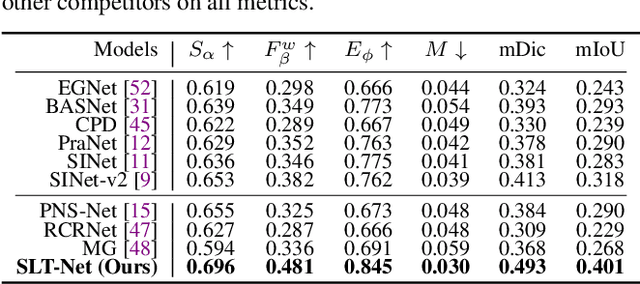
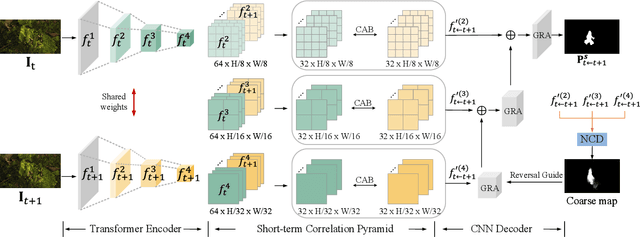

We propose a new video camouflaged object detection (VCOD) framework that can exploit both short-term dynamics and long-term temporal consistency to detect camouflaged objects from video frames. An essential property of camouflaged objects is that they usually exhibit patterns similar to the background and thus make them hard to identify from still images. Therefore, effectively handling temporal dynamics in videos becomes the key for the VCOD task as the camouflaged objects will be noticeable when they move. However, current VCOD methods often leverage homography or optical flows to represent motions, where the detection error may accumulate from both the motion estimation error and the segmentation error. On the other hand, our method unifies motion estimation and object segmentation within a single optimization framework. Specifically, we build a dense correlation volume to implicitly capture motions between neighbouring frames and utilize the final segmentation supervision to optimize the implicit motion estimation and segmentation jointly. Furthermore, to enforce temporal consistency within a video sequence, we jointly utilize a spatio-temporal transformer to refine the short-term predictions. Extensive experiments on VCOD benchmarks demonstrate the architectural effectiveness of our approach. We also provide a large-scale VCOD dataset named MoCA-Mask with pixel-level handcrafted ground-truth masks and construct a comprehensive VCOD benchmark with previous methods to facilitate research in this direction. Dataset Link: https://xueliancheng.github.io/SLT-Net-project.