 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining single-electron and single-photon stochastic physical neural networks
Apr 12, 2026The computational demands of deep learning motivate the investigation of alternative approaches to computation. One alternative is physical neural networks~(PNNs), in which learning and inference are performed directly via physical processes. Stochastic PNNs arise when the underlying neurons are realized by the dynamics of a stochastic activation switch. Here we propose novel electronic and photonic stochastic neurons. The electronic realization is implemented by single-electron tunneling through a quantum dot. The photonic realization is implemented via a single-photon source driving one of two modes coupled via a controllable beam-splitter-like interaction. In the electronic case, the charge state of the quantum dot forms the basis for the stochastic neuron, whereas in the photonic case the occupation of the undriven mode serves as the basis for the stochastic neuron. Training of stochastic PNNs is performed with models of stochastic neurons, as well as with coherently-driven, single-photon detector stochastic neurons previously introduced. Several training strategies for MNIST handwritten digit classification have been investigated using single-hidden-layer stochastic PNNs, including varying the number of trials in each layer to control forward pass stochasticity and employing either true probability or empirical outputs in the backward pass to evaluate their influence on gradient estimation. We show that when empirical outputs are used in the backward pass, the network achieves more than 97\% test accuracy with few trials per layer. Despite the simplicity of the model architecture, high test accuracy is maintained in the presence of a high degree of noise and model uncertainty. The results demonstrate the potential of embracing stochastic PNNs for deep learning.
SHIELD: An Auto-Healing Agentic Defense Framework for LLM Resource Exhaustion Attacks
Jan 27, 2026Sponge attacks increasingly threaten LLM systems by inducing excessive computation and DoS. Existing defenses either rely on statistical filters that fail on semantically meaningful attacks or use static LLM-based detectors that struggle to adapt as attack strategies evolve. We introduce SHIELD, a multi-agent, auto-healing defense framework centered on a three-stage Defense Agent that integrates semantic similarity retrieval, pattern matching, and LLM-based reasoning. Two auxiliary agents, a Knowledge Updating Agent and a Prompt Optimization Agent, form a closed self-healing loop, when an attack bypasses detection, the system updates an evolving knowledgebase, and refines defense instructions. Extensive experiments show that SHIELD consistently outperforms perplexity-based and standalone LLM defenses, achieving high F1 scores across both non-semantic and semantic sponge attacks, demonstrating the effectiveness of agentic self-healing against evolving resource-exhaustion threats.
Prompt-Induced Over-Generation as Denial-of-Service: A Black-Box Attack-Side Benchmark
Dec 29, 2025Large language models (LLMs) can be driven into over-generation, emitting thousands of tokens before producing an end-of-sequence (EOS) token. This degrades answer quality, inflates latency and cost, and can be weaponized as a denial-of-service (DoS) attack. Recent work has begun to study DoS-style prompt attacks, but typically focuses on a single attack algorithm or assumes white-box access, without an attack-side benchmark that compares prompt-based attackers in a black-box, query-only regime with a known tokenizer. We introduce such a benchmark and study two prompt-only attackers. The first is Evolutionary Over-Generation Prompt Search (EOGen), which searches the token space for prefixes that suppress EOS and induce long continuations. The second is a goal-conditioned reinforcement learning attacker (RL-GOAL) that trains a network to generate prefixes conditioned on a target length. To characterize behavior, we introduce Over-Generation Factor (OGF), the ratio of produced tokens to a model's context window, along with stall and latency summaries. Our evolutionary attacker achieves mean OGF = 1.38 +/- 1.15 and Success@OGF >= 2 of 24.5 percent on Phi-3. RL-GOAL is stronger: across victims it achieves higher mean OGF (up to 2.81 +/- 1.38).
YOLO11-4K: An Efficient Architecture for Real-Time Small Object Detection in 4K Panoramic Images
Dec 18, 2025The processing of omnidirectional 360-degree images poses significant challenges for object detection due to inherent spatial distortions, wide fields of view, and ultra-high-resolution inputs. Conventional detectors such as YOLO are optimised for standard image sizes (for example, 640x640 pixels) and often struggle with the computational demands of 4K or higher-resolution imagery typical of 360-degree vision. To address these limitations, we introduce YOLO11-4K, an efficient real-time detection framework tailored for 4K panoramic images. The architecture incorporates a novel multi-scale detection head with a P2 layer to improve sensitivity to small objects often missed at coarser scales, and a GhostConv-based backbone to reduce computational complexity without sacrificing representational power. To enable evaluation, we manually annotated the CVIP360 dataset, generating 6,876 frame-level bounding boxes and producing a publicly available, detection-ready benchmark for 4K panoramic scenes. YOLO11-4K achieves 0.95 mAP at 0.50 IoU with 28.3 milliseconds inference per frame, representing a 75 percent latency reduction compared to YOLO11 (112.3 milliseconds), while also improving accuracy (mAP at 0.50 of 0.95 versus 0.908). This balance of efficiency and precision enables robust object detection in expansive 360-degree environments, making the framework suitable for real-world high-resolution panoramic applications. While this work focuses on 4K omnidirectional images, the approach is broadly applicable to high-resolution detection tasks in autonomous navigation, surveillance, and augmented reality.
Quantum Feature Space of a Qubit Coupled to an Arbitrary Bath
May 07, 2025



Qubit control protocols have traditionally leveraged a characterisation of the qubit-bath coupling via its power spectral density. Previous work proposed the inference of noise operators that characterise the influence of a classical bath using a grey-box approach that combines deep neural networks with physics-encoded layers. This overall structure is complex and poses challenges in scaling and real-time operations. Here, we show that no expensive neural networks are needed and that this noise operator description admits an efficient parameterisation. We refer to the resulting parameter space as the \textit{quantum feature space} of the qubit dynamics resulting from the coupled bath. We show that the Euclidean distance defined over the quantum feature space provides an effective method for classifying noise processes in the presence of a given set of controls. Using the quantum feature space as the input space for a simple machine learning algorithm (random forest, in this case), we demonstrate that it can effectively classify the stationarity and the broad class of noise processes perturbing a qubit. Finally, we explore how control pulse parameters map to the quantum feature space.
AMF: Adaptable Weighting Fusion with Multiple Fine-tuning for Image Classification
Jul 26, 2022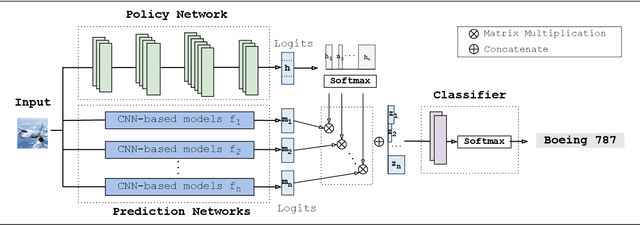
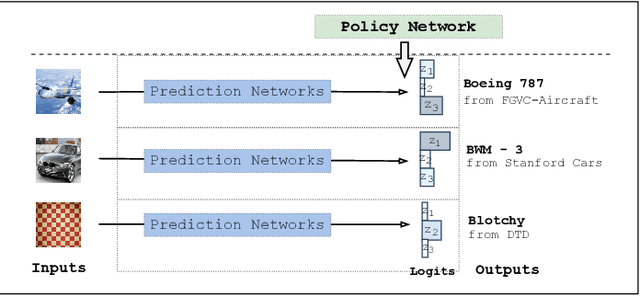
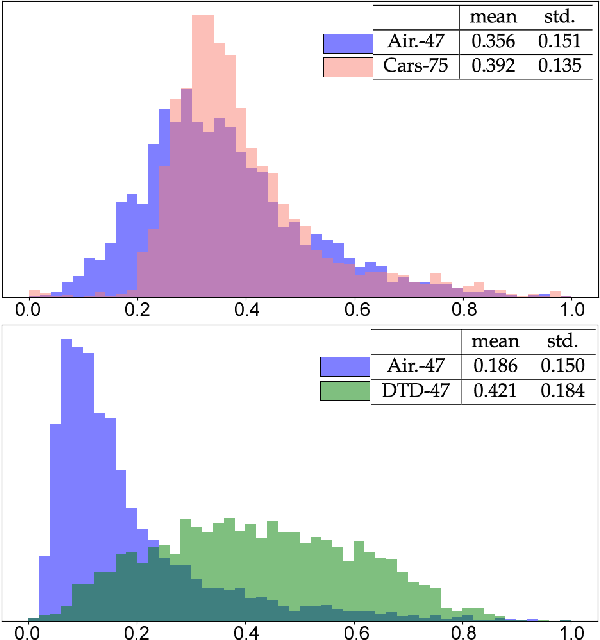
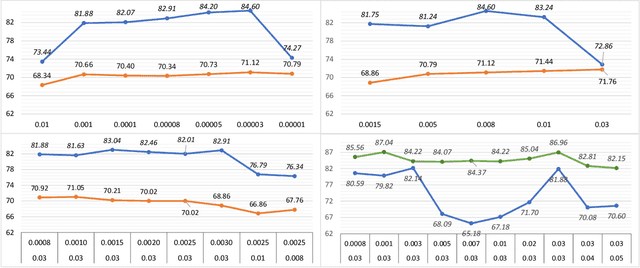
Fine-tuning is widely applied in image classification tasks as a transfer learning approach. It re-uses the knowledge from a source task to learn and obtain a high performance in target tasks. Fine-tuning is able to alleviate the challenge of insufficient training data and expensive labelling of new data. However, standard fine-tuning has limited performance in complex data distributions. To address this issue, we propose the Adaptable Multi-tuning method, which adaptively determines each data sample's fine-tuning strategy. In this framework, multiple fine-tuning settings and one policy network are defined. The policy network in Adaptable Multi-tuning can dynamically adjust to an optimal weighting to feed different samples into models that are trained using different fine-tuning strategies. Our method outperforms the standard fine-tuning approach by 1.69%, 2.79% on the datasets FGVC-Aircraft, and Describable Texture, yielding comparable performance on the datasets Stanford Cars, CIFAR-10, and Fashion-MNIST.
Deep transfer learning for image classification: a survey
May 20, 2022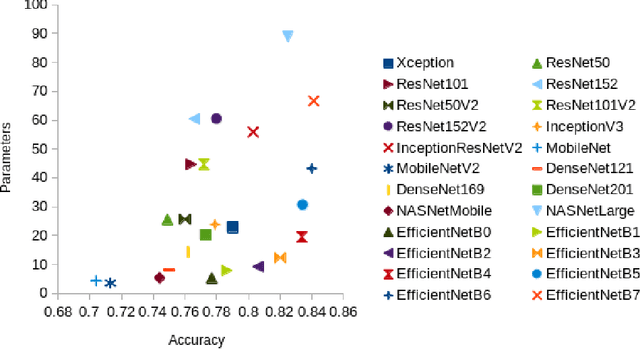

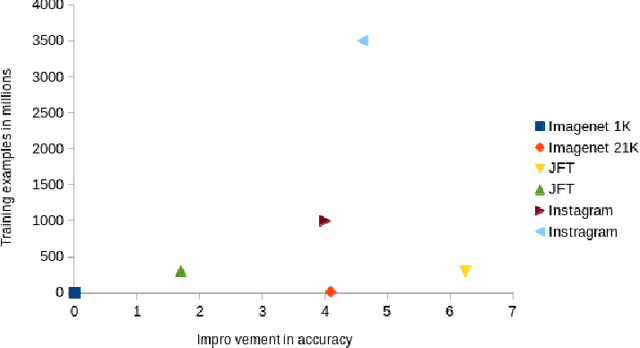
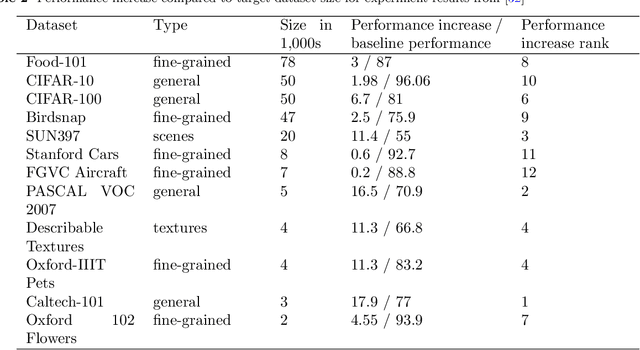
Deep neural networks such as convolutional neural networks (CNNs) and transformers have achieved many successes in image classification in recent years. It has been consistently demonstrated that best practice for image classification is when large deep models can be trained on abundant labelled data. However there are many real world scenarios where the requirement for large amounts of training data to get the best performance cannot be met. In these scenarios transfer learning can help improve performance. To date there have been no surveys that comprehensively review deep transfer learning as it relates to image classification overall. However, several recent general surveys of deep transfer learning and ones that relate to particular specialised target image classification tasks have been published. We believe it is important for the future progress in the field that all current knowledge is collated and the overarching patterns analysed and discussed. In this survey we formally define deep transfer learning and the problem it attempts to solve in relation to image classification. We survey the current state of the field and identify where recent progress has been made. We show where the gaps in current knowledge are and make suggestions for how to progress the field to fill in these knowledge gaps. We present a new taxonomy of the applications of transfer learning for image classification. This taxonomy makes it easier to see overarching patterns of where transfer learning has been effective and, where it has failed to fulfill its potential. This also allows us to suggest where the problems lie and how it could be used more effectively. We show that under this new taxonomy, many of the applications where transfer learning has been shown to be ineffective or even hinder performance are to be expected when taking into account the source and target datasets and the techniques used.
Developing Imperceptible Adversarial Patches to Camouflage Military Assets From Computer Vision Enabled Technologies
Feb 17, 2022


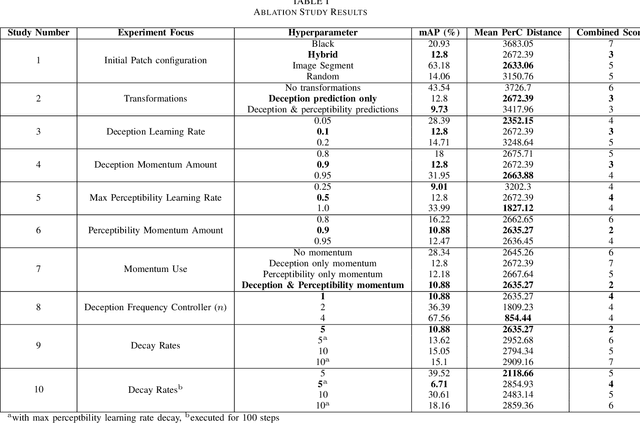
Convolutional neural networks (CNNs) have demonstrated rapid progress and a high level of success in object detection. However, recent evidence has highlighted their vulnerability to adversarial attacks. These attacks are calculated image perturbations or adversarial patches that result in object misclassification or detection suppression. Traditional camouflage methods are impractical when applied to disguise aircraft and other large mobile assets from autonomous detection in intelligence, surveillance and reconnaissance technologies and fifth generation missiles. In this paper we present a unique method that produces imperceptible patches capable of camouflaging large military assets from computer vision-enabled technologies. We developed these patches by maximising object detection loss whilst limiting the patch's colour perceptibility. This work also aims to further the understanding of adversarial examples and their effects on object detection algorithms.
Feature Selection on Thermal-stress Dataset
Sep 08, 2021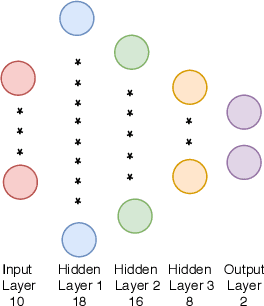

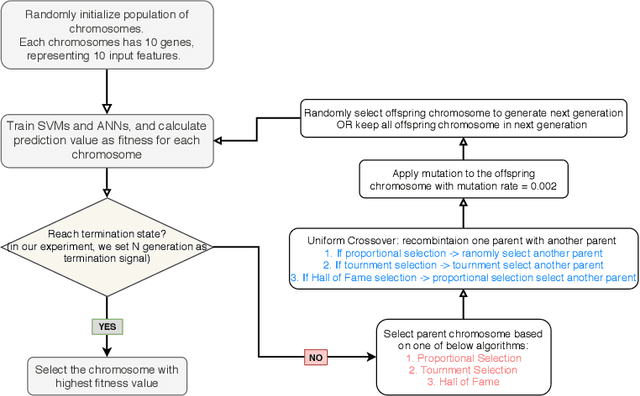
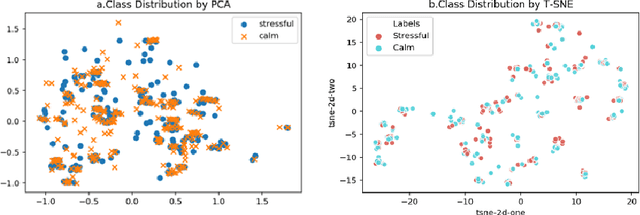
Physical symptoms caused by high stress commonly happen in our daily lives, leading to the importance of stress recognition systems. This study aims to improve stress classification by selecting appropriate features from Thermal-stress data, ANUstressDB. We explored three different feature selection techniques: correlation analysis, magnitude measure, and genetic algorithm. Support Vector Machine (SVM) and Artificial Neural Network (ANN) models were involved in measuring these three algorithms. Our result indicates that the genetic algorithm combined with ANNs can improve the prediction accuracy by 19.1% compared to the baseline. Moreover, the magnitude measure performed best among the three feature selection algorithms regarding the balance of computation time and performance. These findings are likely to improve the accuracy of current stress recognition systems.
Exploring Biases and Prejudice of Facial Synthesis via Semantic Latent Space
Aug 23, 2021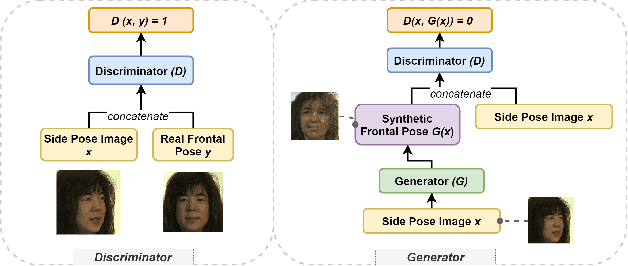
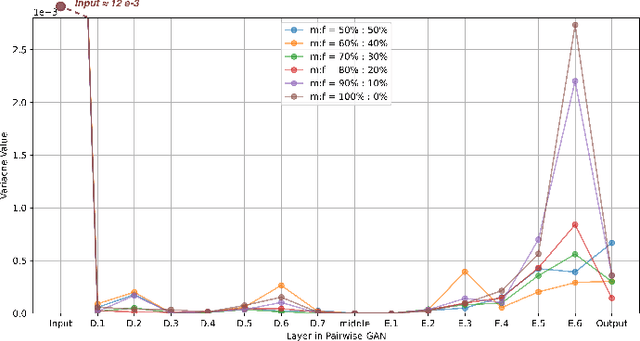
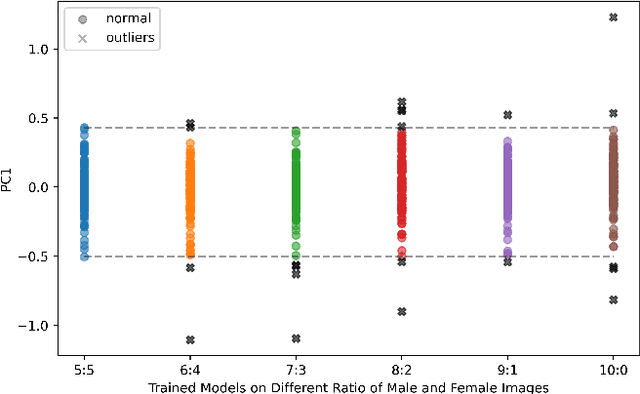
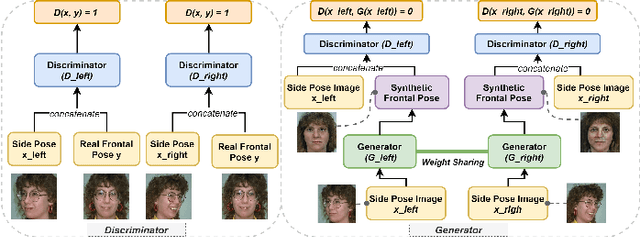
Deep learning (DL) models are widely used to provide a more convenient and smarter life. However, biased algorithms will negatively influence us. For instance, groups targeted by biased algorithms will feel unfairly treated and even fearful of negative consequences of these biases. This work targets biased generative models' behaviors, identifying the cause of the biases and eliminating them. We can (as expected) conclude that biased data causes biased predictions of face frontalization models. Varying the proportions of male and female faces in the training data can have a substantial effect on behavior on the test data: we found that the seemingly obvious choice of 50:50 proportions was not the best for this dataset to reduce biased behavior on female faces, which was 71% unbiased as compared to our top unbiased rate of 84%. Failure in generation and generating incorrect gender faces are two behaviors of these models. In addition, only some layers in face frontalization models are vulnerable to biased datasets. Optimizing the skip-connections of the generator in face frontalization models can make models less biased. We conclude that it is likely to be impossible to eliminate all training bias without an unlimited size dataset, and our experiments show that the bias can be reduced and quantified. We believe the next best to a perfect unbiased predictor is one that has minimized the remaining known bias.