 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models: Datasets, Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models. This challenge utilizes a new short-form UGC (S-UGC) video restoration benchmark, termed KwaiVIR, which is contributed by USTC and Kuaishou Technology. It contains both synthetically distorted videos and real-world short-form UGC videos in the wild. For this edition, the released data include 200 synthetic training videos, 48 wild training videos, 11 validation videos, and 20 testing videos. The primary goal of this challenge is to establish a strong and practical benchmark for restoring short-form UGC videos under complex real-world degradations, especially in the emerging paradigm of generative-model-based S-UGC video restoration. This challenge has two tracks: (i) the primary track is a subjective track, where the evaluation is based on a user study; (ii) the second track is an objective track. These two tracks enable a comprehensive assessment of restoration quality. In total, 95 teams have registered for this competition. And 12 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the KwaiVIR benchmark, demonstrating encouraging progress in short-form UGC video restoration in the wild.
MixRI: Mixing Features of Reference Images for Novel Object Pose Estimation
Jan 11, 2026We present MixRI, a lightweight network that solves the CAD-based novel object pose estimation problem in RGB images. It can be instantly applied to a novel object at test time without finetuning. We design our network to meet the demands of real-world applications, emphasizing reduced memory requirements and fast inference time. Unlike existing works that utilize many reference images and have large network parameters, we directly match points based on the multi-view information between the query and reference images with a lightweight network. Thanks to our reference image fusion strategy, we significantly decrease the number of reference images, thus decreasing the time needed to process these images and the memory required to store them. Furthermore, with our lightweight network, our method requires less inference time. Though with fewer reference images, experiments on seven core datasets in the BOP challenge show that our method achieves comparable results with other methods that require more reference images and larger network parameters.
* Accepted by ICCV 2025
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
A Generative Victim Model for Segmentation
Dec 10, 2024We find that the well-trained victim models (VMs), against which the attacks are generated, serve as fundamental prerequisites for adversarial attacks, i.e. a segmentation VM is needed to generate attacks for segmentation. In this context, the victim model is assumed to be robust to achieve effective adversarial perturbation generation. Instead of focusing on improving the robustness of the task-specific victim models, we shift our attention to image generation. From an image generation perspective, we derive a novel VM for segmentation, aiming to generate adversarial perturbations for segmentation tasks without requiring models explicitly designed for image segmentation. Our approach to adversarial attack generation diverges from conventional white-box or black-box attacks, offering a fresh outlook on adversarial attack strategies. Experiments show that our attack method is able to generate effective adversarial attacks with good transferability.
Non-rigid Structure-from-Motion: Temporally-smooth Procrustean Alignment and Spatially-variant Deformation Modeling
May 07, 2024



Even though Non-rigid Structure-from-Motion (NRSfM) has been extensively studied and great progress has been made, there are still key challenges that hinder their broad real-world applications: 1) the inherent motion/rotation ambiguity requires either explicit camera motion recovery with extra constraint or complex Procrustean Alignment; 2) existing low-rank modeling of the global shape can over-penalize drastic deformations in the 3D shape sequence. This paper proposes to resolve the above issues from a spatial-temporal modeling perspective. First, we propose a novel Temporally-smooth Procrustean Alignment module that estimates 3D deforming shapes and adjusts the camera motion by aligning the 3D shape sequence consecutively. Our new alignment module remedies the requirement of complex reference 3D shape during alignment, which is more conductive to non-isotropic deformation modeling. Second, we propose a spatial-weighted approach to enforce the low-rank constraint adaptively at different locations to accommodate drastic spatially-variant deformation reconstruction better. Our modeling outperform existing low-rank based methods, and extensive experiments across different datasets validate the effectiveness of our method.
Deep Non-rigid Structure-from-Motion: A Sequence-to-Sequence Translation Perspective
Apr 10, 2022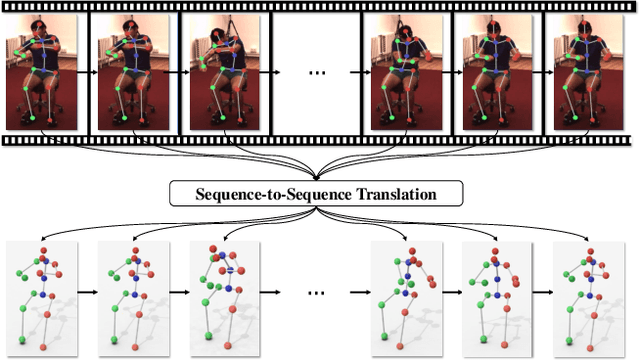
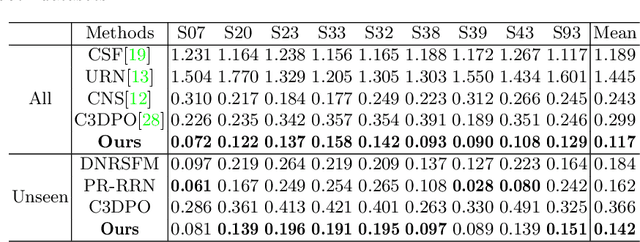
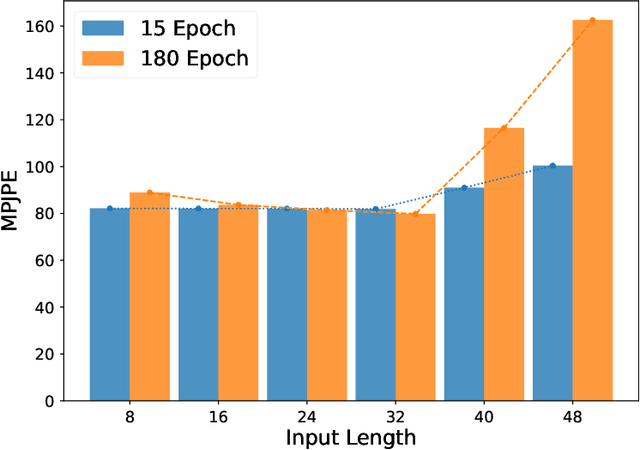
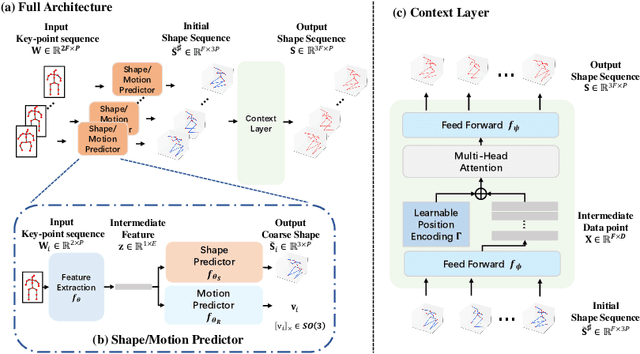
Directly regressing the non-rigid shape and camera pose from the individual 2D frame is ill-suited to the Non-Rigid Structure-from-Motion (NRSfM) problem. This frame-by-frame 3D reconstruction pipeline overlooks the inherent spatial-temporal nature of NRSfM, i.e., reconstructing the whole 3D sequence from the input 2D sequence. In this paper, we propose to model deep NRSfM from a sequence-to-sequence translation perspective, where the input 2D frame sequence is taken as a whole to reconstruct the deforming 3D non-rigid shape sequence. First, we apply a shape-motion predictor to estimate the initial non-rigid shape and camera motion from a single frame. Then we propose a context modeling module to model camera motions and complex non-rigid shapes. To tackle the difficulty in enforcing the global structure constraint within the deep framework, we propose to impose the union-of-subspace structure by replacing the self-expressiveness layer with multi-head attention and delayed regularizers, which enables end-to-end batch-wise training. Experimental results across different datasets such as Human3.6M, CMU Mocap and InterHand prove the superiority of our framework. The code will be made publicly available
Learning to Amend Facial Expression Representation via De-albino and Affinity
Mar 18, 2021


Facial Expression Recognition (FER) is a classification task that points to face variants. Hence, there are certain intimate relationships between facial expressions. We call them affinity features, which are barely taken into account by current FER algorithms. Besides, to capture the edge information of the image, Convolutional Neural Networks (CNNs) generally utilize a host of edge paddings. Although they are desirable, the feature map is deeply eroded after multi-layer convolution. We name what has formed in this process the albino features, which definitely weaken the representation of the expression. To tackle these challenges, we propose a novel architecture named Amend Representation Module (ARM). ARM is a substitute for the pooling layer. Theoretically, it could be embedded in any CNN with a pooling layer. ARM efficiently enhances facial expression representation from two different directions: 1) reducing the weight of eroded features to offset the side effect of padding, and 2) sharing affinity features over mini-batch to strengthen the representation learning. In terms of data imbalance, we designed a minimal random resampling (MRR) scheme to suppress network overfitting. Experiments on public benchmarks prove that our ARM boosts the performance of FER remarkably. The validation accuracies are respectively 90.55% on RAF-DB, 64.49% on Affect-Net, and 71.38% on FER2013, exceeding current state-of-the-art methods.