 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Relational Triple Extraction Method Based on Feature Reasoning for Technological Patents
Oct 07, 2022



The relation triples extraction method based on table filling can address the issues of relation overlap and bias propagation. However, most of them only establish separate table features for each relationship, which ignores the implicit relationship between different entity pairs and different relationship features. Therefore, a feature reasoning relational triple extraction method based on table filling for technological patents is proposed to explore the integration of entity recognition and entity relationship, and to extract entity relationship triples from multi-source scientific and technological patents data. Compared with the previous methods, the method we proposed for relational triple extraction has the following advantages: 1) The table filling method that saves more running space enhances the speed and efficiency of the model. 2) Based on the features of existing token pairs and table relations, reasoning the implicit relationship features, and improve the accuracy of triple extraction. On five benchmark datasets, we evaluated the model we suggested. The result suggest that our model is advanced and effective, and it performed well on most of these datasets.
Diffusion Models: A Comprehensive Survey of Methods and Applications
Sep 15, 2022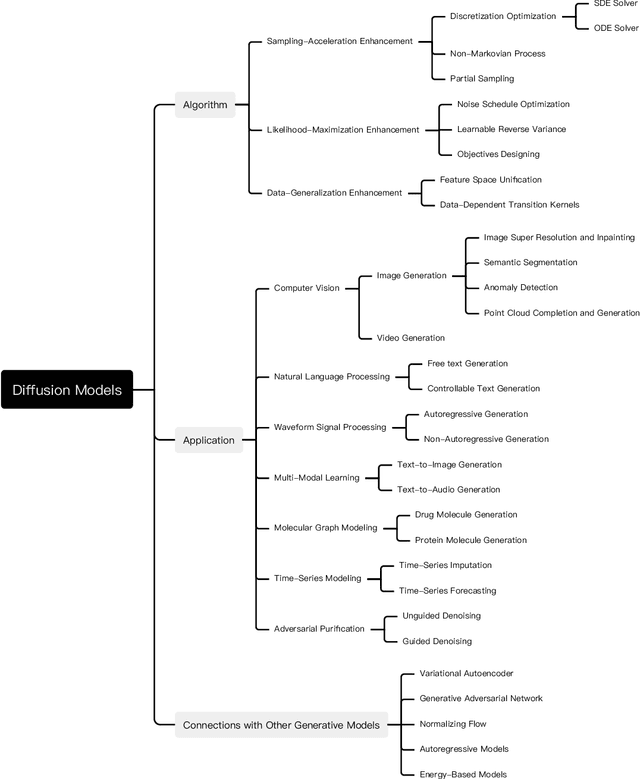
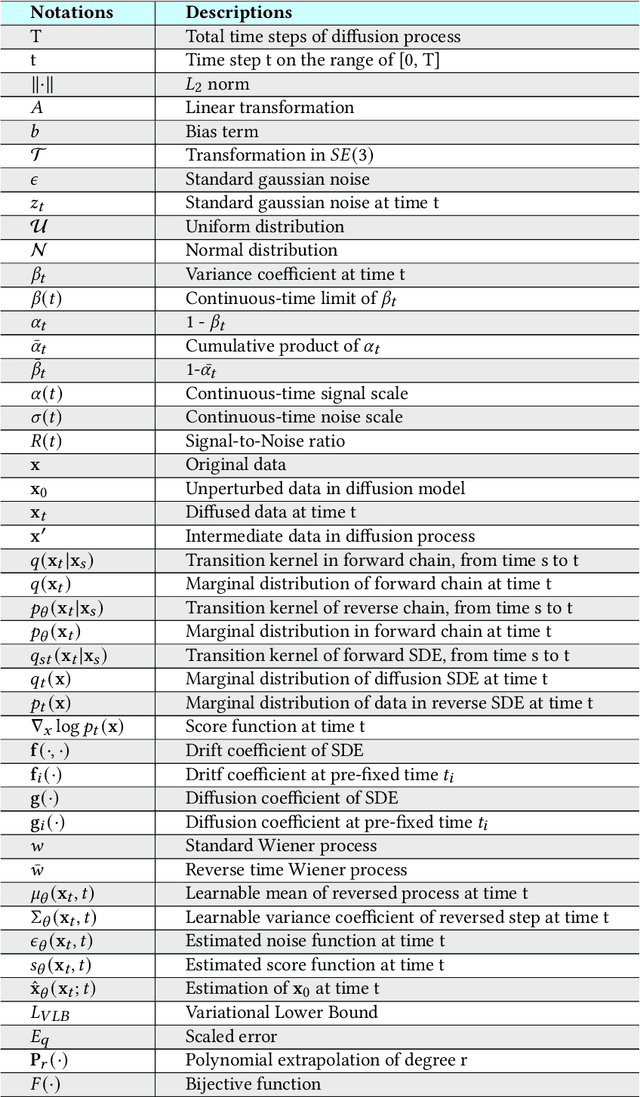
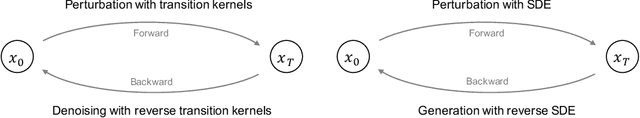
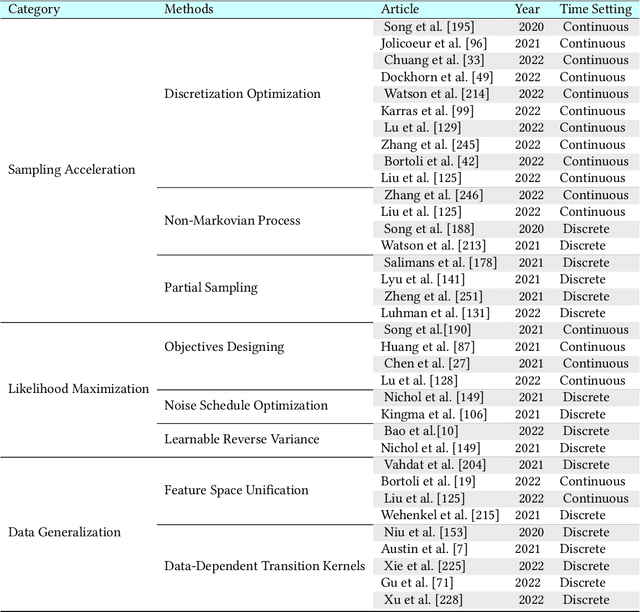
Diffusion models are a class of deep generative models that have shown impressive results on various tasks with a solid theoretical foundation. Despite demonstrated success than state-of-the-art approaches, diffusion models often entail costly sampling procedures and sub-optimal likelihood estimation. Significant efforts have been made to improve the performance of diffusion models in various aspects. In this article, we present a comprehensive review of existing variants of diffusion models. Specifically, we provide the taxonomy of diffusion models and categorize them into three types: sampling-acceleration enhancement, likelihood-maximization enhancement, and data-generalization enhancement. We also introduce the other generative models (i.e., variational autoencoders, generative adversarial networks, normalizing flow, autoregressive models, and energy-based models) and discuss the connections between diffusion models and these generative models. Then we review the applications of diffusion models, including computer vision, natural language processing, waveform signal processing, multi-modal modeling, molecular graph generation, time series modeling, and adversarial purification. Furthermore, we propose new perspectives pertaining to the development of generative models. Github: https://github.com/YangLing0818/Diffusion-Models-Papers-Survey-Taxonomy.
A Rare Topic Discovery Model for Short Texts Based on Co-occurrence word Network
Jun 30, 2022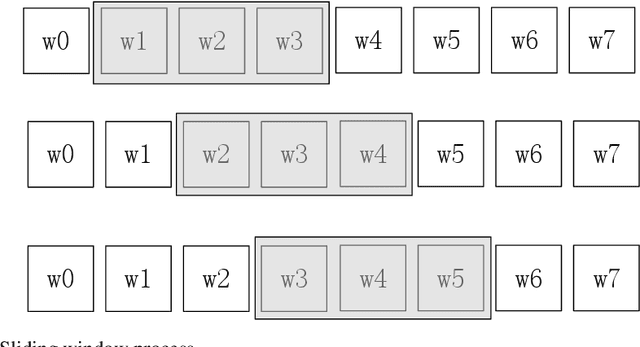

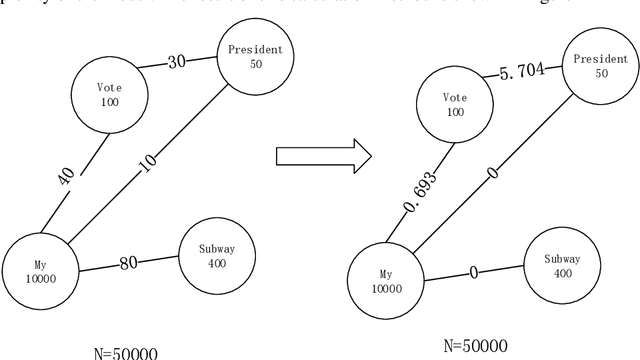

We provide a simple and general solution for the discovery of scarce topics in unbalanced short-text datasets, namely, a word co-occurrence network-based model CWIBTD, which can simultaneously address the sparsity and unbalance of short-text topics and attenuate the effect of occasional pairwise occurrences of words, allowing the model to focus more on the discovery of scarce topics. Unlike previous approaches, CWIBTD uses co-occurrence word networks to model the topic distribution of each word, which improves the semantic density of the data space and ensures its sensitivity in identify-ing rare topics by improving the way node activity is calculated and normal-izing scarce topics and large topics to some extent. In addition, using the same Gibbs sampling as LDA makes CWIBTD easy to be extended to vari-ous application scenarios. Extensive experimental validation in the unbal-anced short text dataset confirms the superiority of CWIBTD over the base-line approach in discovering rare topics. Our model can be used for early and accurate discovery of emerging topics or unexpected events on social platforms.
A sentiment analysis model for car review texts based on adversarial training and whole word mask BERT
Jun 06, 2022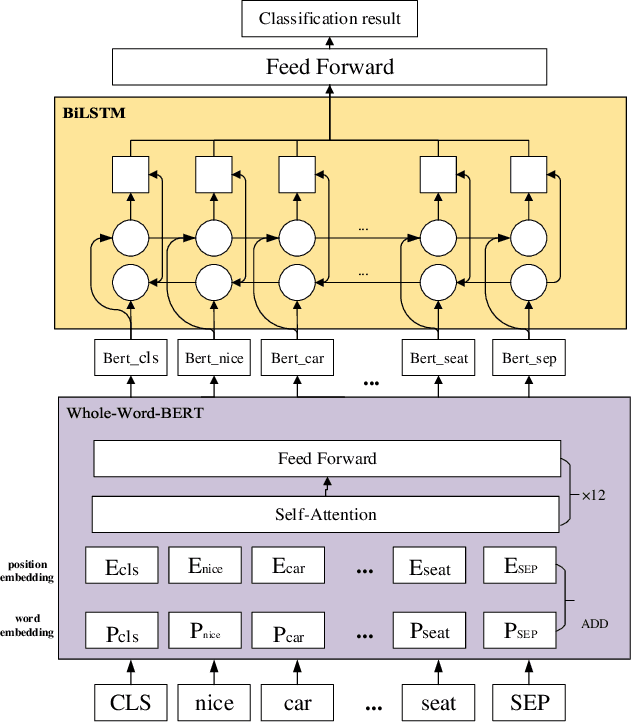
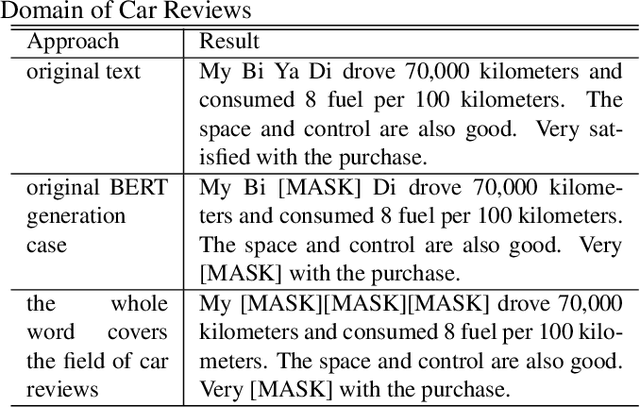
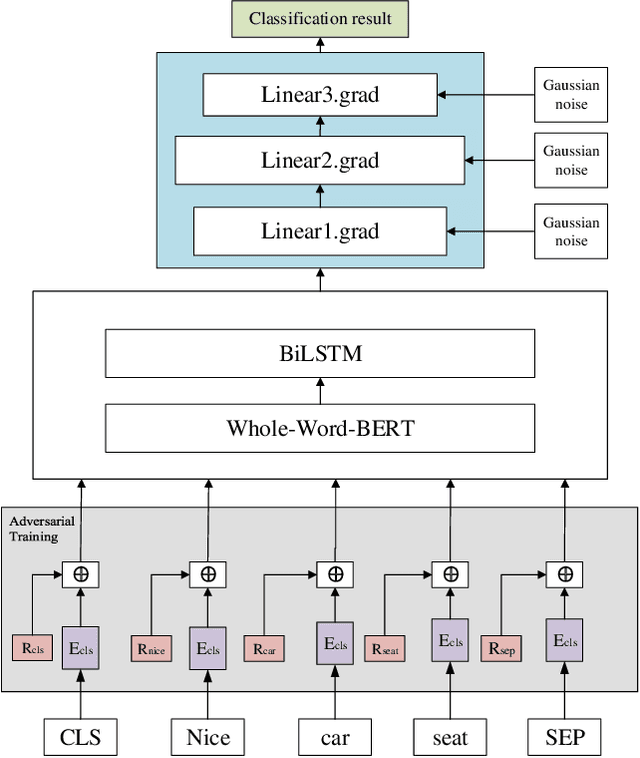
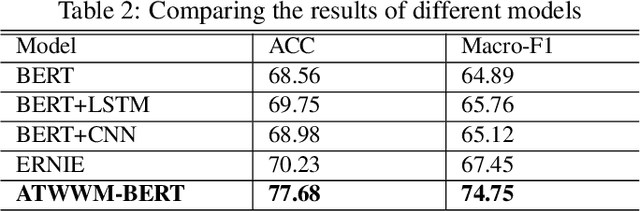
In the field of car evaluation, more and more netizens choose to express their opinions on the Internet platform, and these comments will affect the decision-making of buyers and the trend of car word-of-mouth. As an important branch of natural language processing (NLP), sentiment analysis provides an effective research method for analyzing the sentiment types of massive car review texts. However, due to the lexical professionalism and large text noise of review texts in the automotive field, when a general sentiment analysis model is applied to car reviews, the accuracy of the model will be poor. To overcome these above challenges, we aim at the sentiment analysis task of car review texts. From the perspective of word vectors, pre-training is carried out by means of whole word mask of proprietary vocabulary in the automotive field, and then training data is carried out through the strategy of an adversarial training set. Based on this, we propose a car review text sentiment analysis model based on adversarial training and whole word mask BERT(ATWWM-BERT).
Sentiment Analysis of Online Travel Reviews Based on Capsule Network and Sentiment Lexicon
Jun 05, 2022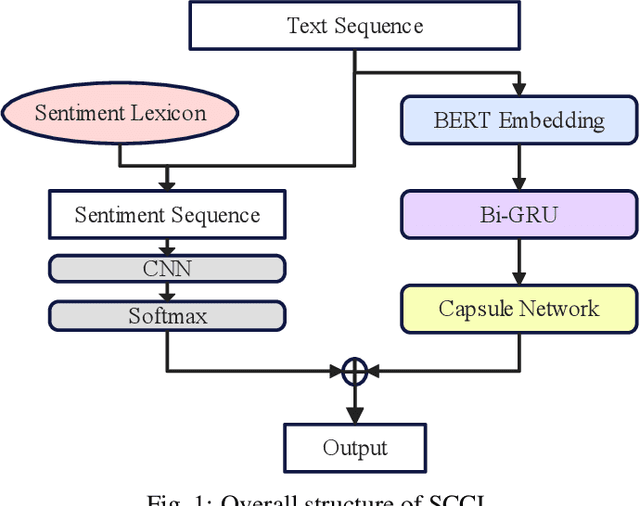
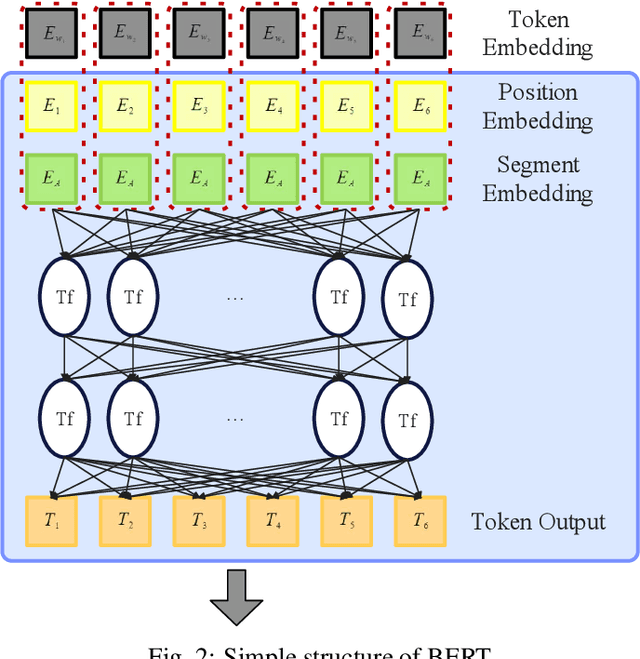
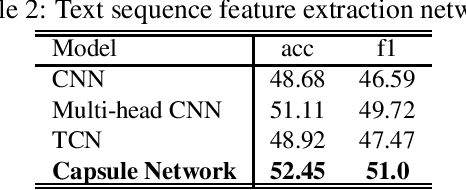
With the development of online travel services, it has great application prospects to timely mine users' evaluation emotions for travel services and use them as indicators to guide the improvement of online travel service quality. In this paper, we study the text sentiment classification of online travel reviews based on social media online comments and propose the SCCL model based on capsule network and sentiment lexicon. SCCL model aims at the lack of consideration of local features and emotional semantic features of the text in the language model that can efficiently extract text context features like BERT and GRU. Then make the following improvements to their shortcomings. On the one hand, based on BERT-BiGRU, the capsule network is introduced to extract local features while retaining good context features. On the other hand, the sentiment lexicon is introduced to extract the emotional sequence of the text to provide richer emotional semantic features for the model. To enhance the universality of the sentiment lexicon, the improved SO-PMI algorithm based on TF-IDF is used to expand the lexicon, so that the lexicon can also perform well in the field of online travel reviews.
RetroMAE: Pre-training Retrieval-oriented Transformers via Masked Auto-Encoder
May 24, 2022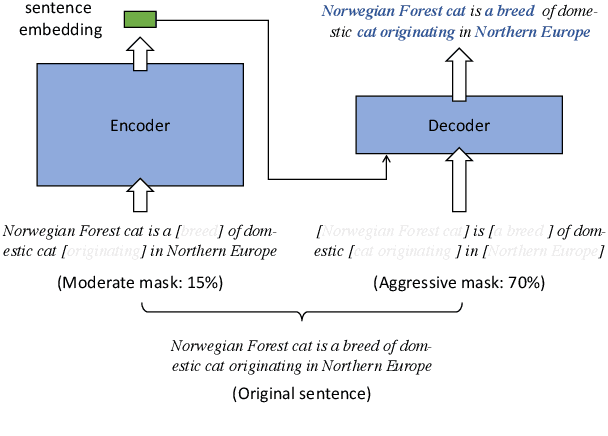
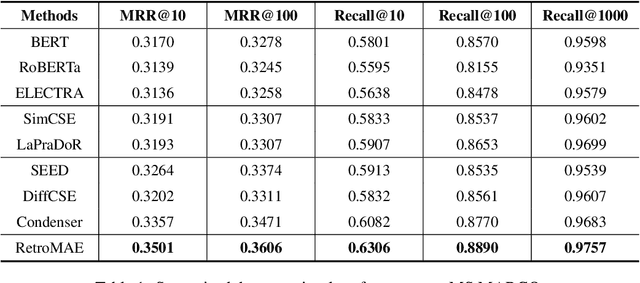
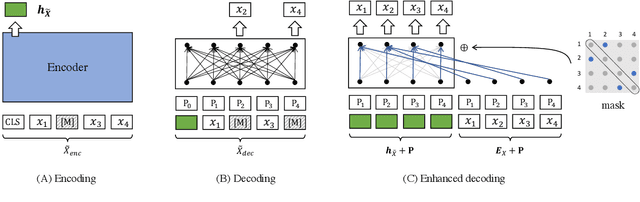
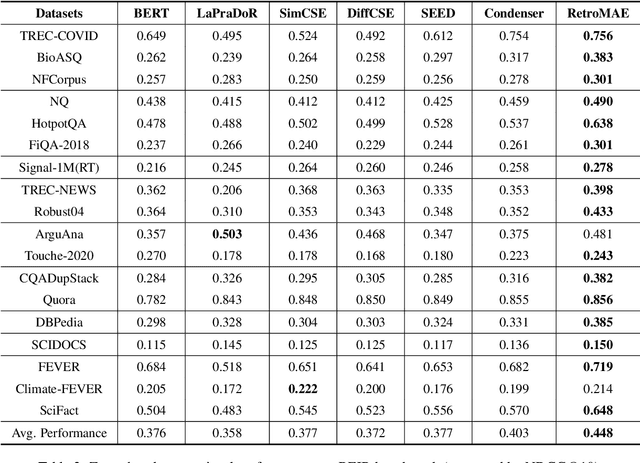
Pre-trained models have demonstrated superior power on many important tasks. However, it is still an open problem of designing effective pre-training strategies so as to promote the models' usability on dense retrieval. In this paper, we propose a novel pre-training framework for dense retrieval based on the Masked Auto-Encoder, known as RetroMAE. Our proposed framework is highlighted for the following critical designs: 1) a MAE based pre-training workflow, where the input sentence is polluted on both encoder and decoder side with different masks, and original sentence is reconstructed based on both sentence embedding and masked sentence; 2) asymmetric model architectures, with a large-scale expressive transformer for sentence encoding and a extremely simplified transformer for sentence reconstruction; 3) asymmetric masking ratios, with a moderate masking on the encoder side (15%) and an aggressive masking ratio on the decoder side (50~90%). We pre-train a BERT like encoder on English Wikipedia and BookCorpus, where it notably outperforms the existing pre-trained models on a wide range of dense retrieval benchmarks, like MS MARCO, Open-domain Question Answering, and BEIR.
Profiling and Evolution of Intellectual Property
Apr 20, 2022In recent years, with the rapid growth of Internet data, the number and types of scientific and technological resources are also rapidly expanding. However, the increase in the number and category of information data will also increase the cost of information acquisition. For technology-based enterprises or users, in addition to general papers, patents, etc., policies related to technology or the development of their industries should also belong to a type of scientific and technological resources. The cost and difficulty of acquiring users. Extracting valuable science and technology policy resources from a huge amount of data with mixed contents and providing accurate and fast retrieval will help to break down information barriers and reduce the cost of information acquisition, which has profound social significance and social utility. This article focuses on the difficulties and problems in the field of science and technology policy, and introduces related technologies and developments.
Research on Intellectual Property Resource Profile and Evolution Law
Apr 13, 2022In the era of big data, intellectual property-oriented scientific and technological resources show the trend of large data scale, high information density and low value density, which brings severe challenges to the effective use of intellectual property resources, and the demand for mining hidden information in intellectual property is increasing. This makes intellectual property-oriented science and technology resource portraits and analysis of evolution become the current research hotspot. This paper sorts out the construction method of intellectual property resource intellectual portrait and its pre-work property entity extraction and entity completion from the aspects of algorithm classification and general process, and directions for improvement of future methods.
Retrieval of Scientific and Technological Resources for Experts and Scholars
Apr 13, 2022Institutions of higher learning, research institutes and other scientific research units have abundant scientific and technological resources of experts and scholars, and these talents with great scientific and technological innovation ability are an important force to promote industrial upgrading. The scientific and technological resources of experts and scholars are mainly composed of basic attributes and scientific research achievements. The basic attributes include information such as research interests, institutions, and educational work experience. However, due to information asymmetry and other reasons, the scientific and technological resources of experts and scholars cannot be connected with the society in a timely manner, and social needs cannot be accurately matched with experts and scholars. Therefore, it is very necessary to build an expert and scholar information database and provide relevant expert and scholar retrieval services. This paper sorts out the related research work in this field from four aspects: text relation extraction, text knowledge representation learning, text vector retrieval and visualization system.
Distill-VQ: Learning Retrieval Oriented Vector Quantization By Distilling Knowledge from Dense Embeddings
Apr 01, 2022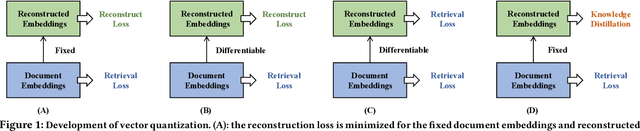
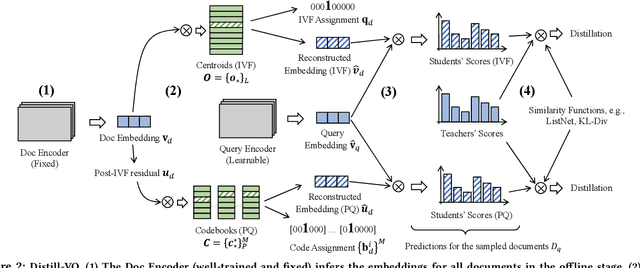
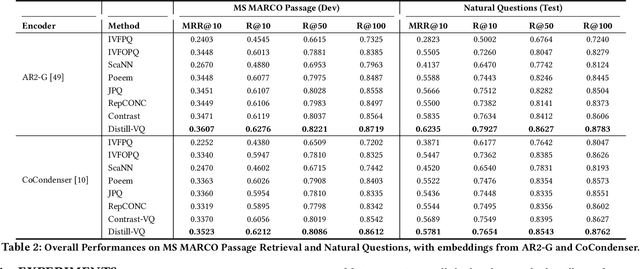
Vector quantization (VQ) based ANN indexes, such as Inverted File System (IVF) and Product Quantization (PQ), have been widely applied to embedding based document retrieval thanks to the competitive time and memory efficiency. Originally, VQ is learned to minimize the reconstruction loss, i.e., the distortions between the original dense embeddings and the reconstructed embeddings after quantization. Unfortunately, such an objective is inconsistent with the goal of selecting ground-truth documents for the input query, which may cause severe loss of retrieval quality. Recent works identify such a defect, and propose to minimize the retrieval loss through contrastive learning. However, these methods intensively rely on queries with ground-truth documents, whose performance is limited by the insufficiency of labeled data. In this paper, we propose Distill-VQ, which unifies the learning of IVF and PQ within a knowledge distillation framework. In Distill-VQ, the dense embeddings are leveraged as "teachers", which predict the query's relevance to the sampled documents. The VQ modules are treated as the "students", which are learned to reproduce the predicted relevance, such that the reconstructed embeddings may fully preserve the retrieval result of the dense embeddings. By doing so, Distill-VQ is able to derive substantial training signals from the massive unlabeled data, which significantly contributes to the retrieval quality. We perform comprehensive explorations for the optimal conduct of knowledge distillation, which may provide useful insights for the learning of VQ based ANN index. We also experimentally show that the labeled data is no longer a necessity for high-quality vector quantization, which indicates Distill-VQ's strong applicability in practice.