 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval of Scientific and Technological Resources for Experts and Scholars
Apr 13, 2022Institutions of higher learning, research institutes and other scientific research units have abundant scientific and technological resources of experts and scholars, and these talents with great scientific and technological innovation ability are an important force to promote industrial upgrading. The scientific and technological resources of experts and scholars are mainly composed of basic attributes and scientific research achievements. The basic attributes include information such as research interests, institutions, and educational work experience. However, due to information asymmetry and other reasons, the scientific and technological resources of experts and scholars cannot be connected with the society in a timely manner, and social needs cannot be accurately matched with experts and scholars. Therefore, it is very necessary to build an expert and scholar information database and provide relevant expert and scholar retrieval services. This paper sorts out the related research work in this field from four aspects: text relation extraction, text knowledge representation learning, text vector retrieval and visualization system.
Scientific and Technological Text Knowledge Extraction Method of based on Word Mixing and GRU
Mar 31, 2022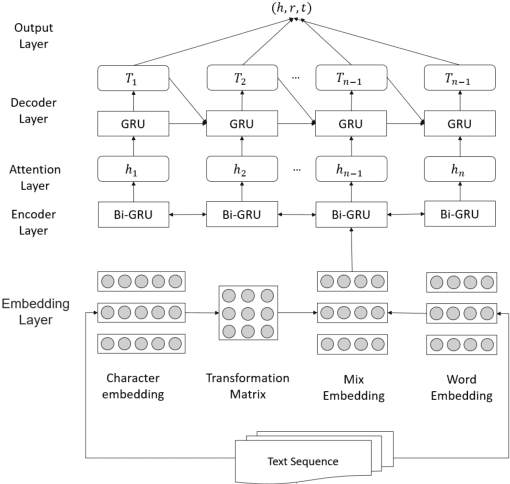
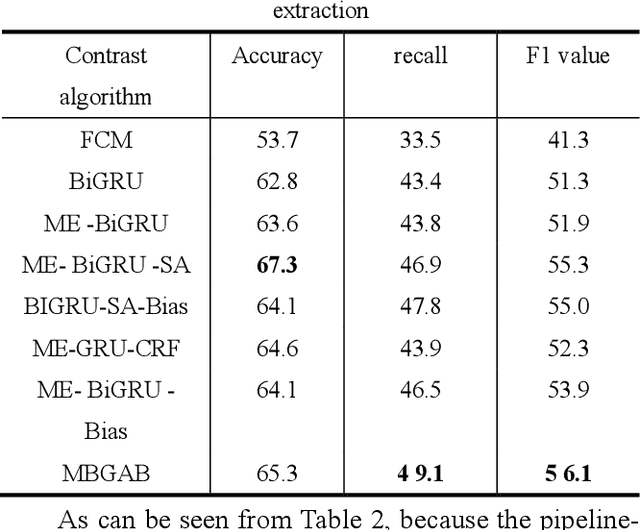
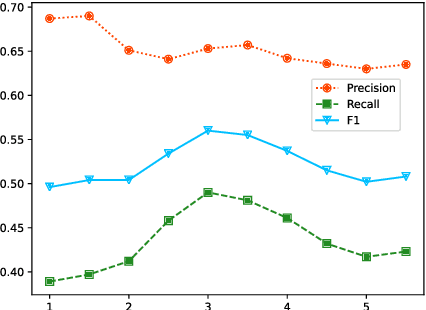

The knowledge extraction task is to extract triple relations (head entity-relation-tail entity) from unstructured text data. The existing knowledge extraction methods are divided into "pipeline" method and joint extraction method. The "pipeline" method is to separate named entity recognition and entity relationship extraction and use their own modules to extract them. Although this method has better flexibility, the training speed is slow. The learning model of joint extraction is an end-to-end model implemented by neural network to realize entity recognition and relationship extraction at the same time, which can well preserve the association between entities and relationships, and convert the joint extraction of entities and relationships into a sequence annotation problem. In this paper, we propose a knowledge extraction method for scientific and technological resources based on word mixture and GRU, combined with word mixture vector mapping method and self-attention mechanism, to effectively improve the effect of text relationship extraction for Chinese scientific and technological resources.