 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Cross-View Geo-Localization via Content-Viewpoint Disentanglement
May 17, 2025Cross-view geo-localization (CVGL) aims to match images of the same geographic location captured from different perspectives, such as drones and satellites. Despite recent advances, CVGL remains highly challenging due to significant appearance changes and spatial distortions caused by viewpoint variations. Existing methods typically assume that cross-view images can be directly aligned within a shared feature space by maximizing feature similarity through contrastive learning. Nonetheless, this assumption overlooks the inherent conflicts induced by viewpoint discrepancies, resulting in extracted features containing inconsistent information that hinders precise localization. In this study, we take a manifold learning perspective and model the feature space of cross-view images as a composite manifold jointly governed by content and viewpoint information. Building upon this insight, we propose $\textbf{CVD}$, a new CVGL framework that explicitly disentangles $\textit{content}$ and $\textit{viewpoint}$ factors. To promote effective disentanglement, we introduce two constraints: $\textit{(i)}$ An intra-view independence constraint, which encourages statistical independence between the two factors by minimizing their mutual information. $\textit{(ii)}$ An inter-view reconstruction constraint that reconstructs each view by cross-combining $\textit{content}$ and $\textit{viewpoint}$ from paired images, ensuring factor-specific semantics are preserved. As a plug-and-play module, CVD can be seamlessly integrated into existing geo-localization pipelines. Extensive experiments on four benchmarks, i.e., University-1652, SUES-200, CVUSA, and CVACT, demonstrate that CVD consistently improves both localization accuracy and generalization across multiple baselines.
OT Score: An OT based Confidence Score for Unsupervised Domain Adaptation
May 16, 2025



We address the computational and theoretical limitations of existing distributional alignment methods for unsupervised domain adaptation (UDA), particularly regarding the estimation of classification performance and confidence without target labels. Current theoretical frameworks for these methods often yield computationally intractable quantities and fail to adequately reflect the properties of the alignment algorithms employed. To overcome these challenges, we introduce the Optimal Transport (OT) score, a confidence metric derived from a novel theoretical analysis that exploits the flexibility of decision boundaries induced by Semi-Discrete Optimal Transport alignment. The proposed OT score is intuitively interpretable, theoretically rigorous, and computationally efficient. It provides principled uncertainty estimates for any given set of target pseudo-labels without requiring model retraining, and can flexibly adapt to varying degrees of available source information. Experimental results on standard UDA benchmarks demonstrate that classification accuracy consistently improves by identifying and removing low-confidence predictions, and that OT score significantly outperforms existing confidence metrics across diverse adaptation scenarios.
FRAME: Feedback-Refined Agent Methodology for Enhancing Medical Research Insights
May 06, 2025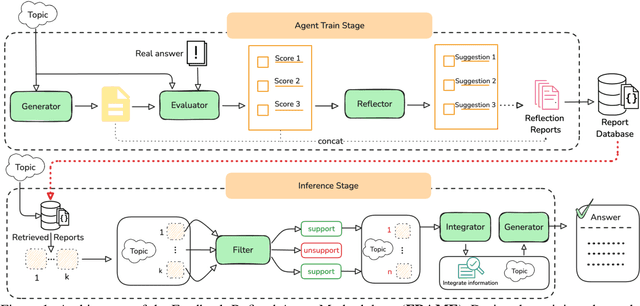
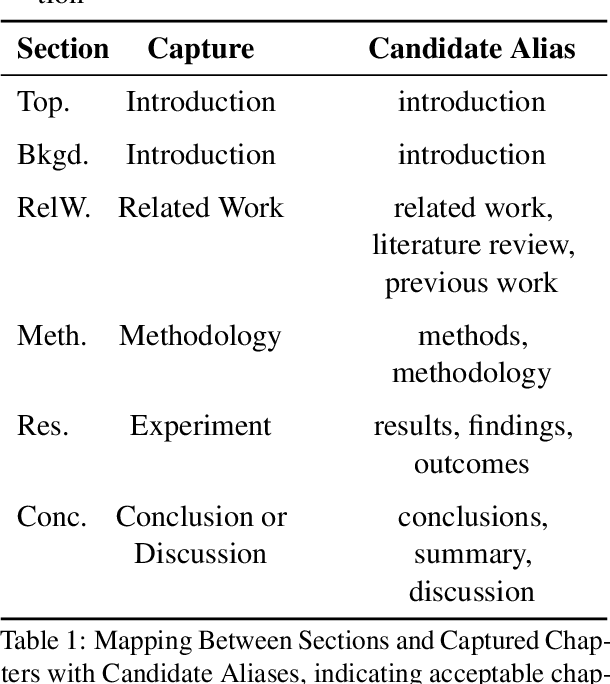
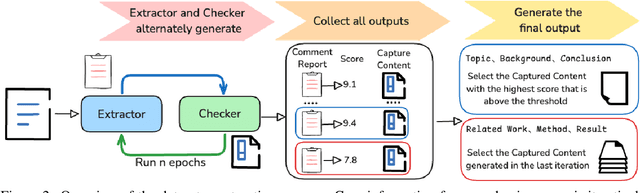

The automation of scientific research through large language models (LLMs) presents significant opportunities but faces critical challenges in knowledge synthesis and quality assurance. We introduce Feedback-Refined Agent Methodology (FRAME), a novel framework that enhances medical paper generation through iterative refinement and structured feedback. Our approach comprises three key innovations: (1) A structured dataset construction method that decomposes 4,287 medical papers into essential research components through iterative refinement; (2) A tripartite architecture integrating Generator, Evaluator, and Reflector agents that progressively improve content quality through metric-driven feedback; and (3) A comprehensive evaluation framework that combines statistical metrics with human-grounded benchmarks. Experimental results demonstrate FRAME's effectiveness, achieving significant improvements over conventional approaches across multiple models (9.91% average gain with DeepSeek V3, comparable improvements with GPT-4o Mini) and evaluation dimensions. Human evaluation confirms that FRAME-generated papers achieve quality comparable to human-authored works, with particular strength in synthesizing future research directions. The results demonstrated our work could efficiently assist medical research by building a robust foundation for automated medical research paper generation while maintaining rigorous academic standards.
NbBench: Benchmarking Language Models for Comprehensive Nanobody Tasks
May 04, 2025Nanobodies, single-domain antibody fragments derived from camelid heavy-chain-only antibodies, exhibit unique advantages such as compact size, high stability, and strong binding affinity, making them valuable tools in therapeutics and diagnostics. While recent advances in pretrained protein and antibody language models (PPLMs and PALMs) have greatly enhanced biomolecular understanding, nanobody-specific modeling remains underexplored and lacks a unified benchmark. To address this gap, we introduce NbBench, the first comprehensive benchmark suite for nanobody representation learning. Spanning eight biologically meaningful tasks across nine curated datasets, NbBench encompasses structure annotation, binding prediction, and developability assessment. We systematically evaluate eleven representative models--including general-purpose protein LMs, antibody-specific LMs, and nanobody-specific LMs--in a frozen setting. Our analysis reveals that antibody language models excel in antigen-related tasks, while performance on regression tasks such as thermostability and affinity remains challenging across all models. Notably, no single model consistently outperforms others across all tasks. By standardizing datasets, task definitions, and evaluation protocols, NbBench offers a reproducible foundation for assessing and advancing nanobody modeling.
The Estimation of Continual Causal Effect for Dataset Shifting Streams
Apr 29, 2025Causal effect estimation has been widely used in marketing optimization. The framework of an uplift model followed by a constrained optimization algorithm is popular in practice. To enhance performance in the online environment, the framework needs to be improved to address the complexities caused by temporal dataset shift. This paper focuses on capturing the dataset shift from user behavior and domain distribution changing over time. We propose an Incremental Causal Effect with Proxy Knowledge Distillation (ICE-PKD) framework to tackle this challenge. The ICE-PKD framework includes two components: (i) a multi-treatment uplift network that eliminates confounding bias using counterfactual regression; (ii) an incremental training strategy that adapts to the temporal dataset shift by updating with the latest data and protects generalization via replay-based knowledge distillation. We also revisit the uplift modeling metrics and introduce a novel metric for more precise online evaluation in multiple treatment scenarios. Extensive experiments on both simulated and online datasets show that the proposed framework achieves better performance. The ICE-PKD framework has been deployed in the marketing system of Huaxiaozhu, a ride-hailing platform in China.
NoveltyBench: Evaluating Language Models for Humanlike Diversity
Apr 08, 2025Language models have demonstrated remarkable capabilities on standard benchmarks, yet they struggle increasingly from mode collapse, the inability to generate diverse and novel outputs. Our work introduces NoveltyBench, a benchmark specifically designed to evaluate the ability of language models to produce multiple distinct and high-quality outputs. NoveltyBench utilizes prompts curated to elicit diverse answers and filtered real-world user queries. Evaluating 20 leading language models, we find that current state-of-the-art systems generate significantly less diversity than human writers. Notably, larger models within a family often exhibit less diversity than their smaller counterparts, challenging the notion that capability on standard benchmarks translates directly to generative utility. While prompting strategies like in-context regeneration can elicit diversity, our findings highlight a fundamental lack of distributional diversity in current models, reducing their utility for users seeking varied responses and suggesting the need for new training and evaluation paradigms that prioritize diversity alongside quality.
Pushing the Limit of PPG Sensing in Sedentary Conditions by Addressing Poor Skin-sensor Contact
Apr 03, 2025Photoplethysmography (PPG) is a widely used non-invasive technique for monitoring cardiovascular health and various physiological parameters on consumer and medical devices. While motion artifacts are well-known challenges in dynamic settings, suboptimal skin-sensor contact in sedentary conditions - a critical issue often overlooked in existing literature - can distort PPG signal morphology, leading to the loss or shift of essential waveform features and therefore degrading sensing performance. In this work, we propose CP-PPG, a novel approach that transforms Contact Pressure-distorted PPG signals into ones with the ideal morphology. CP-PPG incorporates a novel data collection approach, a well-crafted signal processing pipeline, and an advanced deep adversarial model trained with a custom PPG-aware loss function. We validated CP-PPG through comprehensive evaluations, including 1) morphology transformation performance on our self-collected dataset, 2) downstream physiological monitoring performance on public datasets, and 3) in-the-wild performance. Extensive experiments demonstrate substantial and consistent improvements in signal fidelity (Mean Absolute Error: 0.09, 40% improvement over the original signal) as well as downstream performance across all evaluations in Heart Rate (HR), Heart Rate Variability (HRV), Respiration Rate (RR), and Blood Pressure (BP) estimation (on average, 21% improvement in HR; 41-46% in HRV; 6% in RR; and 4-5% in BP). These findings highlight the critical importance of addressing skin-sensor contact issues for accurate and dependable PPG-based physiological monitoring. Furthermore, CP-PPG can serve as a generic, plug-in API to enhance PPG signal quality.
STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding?
Mar 31, 2025The use of Multimodal Large Language Models (MLLMs) as an end-to-end solution for Embodied AI and Autonomous Driving has become a prevailing trend. While MLLMs have been extensively studied for visual semantic understanding tasks, their ability to perform precise and quantitative spatial-temporal understanding in real-world applications remains largely unexamined, leading to uncertain prospects. To evaluate models' Spatial-Temporal Intelligence, we introduce STI-Bench, a benchmark designed to evaluate MLLMs' spatial-temporal understanding through challenging tasks such as estimating and predicting the appearance, pose, displacement, and motion of objects. Our benchmark encompasses a wide range of robot and vehicle operations across desktop, indoor, and outdoor scenarios. The extensive experiments reveals that the state-of-the-art MLLMs still struggle in real-world spatial-temporal understanding, especially in tasks requiring precise distance estimation and motion analysis.
Towards Physically Plausible Video Generation via VLM Planning
Mar 30, 2025Video diffusion models (VDMs) have advanced significantly in recent years, enabling the generation of highly realistic videos and drawing the attention of the community in their potential as world simulators. However, despite their capabilities, VDMs often fail to produce physically plausible videos due to an inherent lack of understanding of physics, resulting in incorrect dynamics and event sequences. To address this limitation, we propose a novel two-stage image-to-video generation framework that explicitly incorporates physics. In the first stage, we employ a Vision Language Model (VLM) as a coarse-grained motion planner, integrating chain-of-thought and physics-aware reasoning to predict a rough motion trajectories/changes that approximate real-world physical dynamics while ensuring the inter-frame consistency. In the second stage, we use the predicted motion trajectories/changes to guide the video generation of a VDM. As the predicted motion trajectories/changes are rough, noise is added during inference to provide freedom to the VDM in generating motion with more fine details. Extensive experimental results demonstrate that our framework can produce physically plausible motion, and comparative evaluations highlight the notable superiority of our approach over existing methods. More video results are available on our Project Page: https://madaoer.github.io/projects/physically_plausible_video_generation.
TrafficKAN-GCN: Graph Convolutional-based Kolmogorov-Arnold Network for Traffic Flow Optimization
Mar 05, 2025Urban traffic optimization is critical for improving transportation efficiency and alleviating congestion, particularly in large-scale dynamic networks. Traditional methods, such as Dijkstra's and Floyd's algorithms, provide effective solutions in static settings, but they struggle with the spatial-temporal complexity of real-world traffic flows. In this work, we propose TrafficKAN-GCN, a hybrid deep learning framework combining Kolmogorov-Arnold Networks (KAN) with Graph Convolutional Networks (GCN), designed to enhance urban traffic flow optimization. By integrating KAN's adaptive nonlinear function approximation with GCN's spatial graph learning capabilities, TrafficKAN-GCN captures both complex traffic patterns and topological dependencies. We evaluate the proposed framework using real-world traffic data from the Baltimore Metropolitan area. Compared with baseline models such as MLP-GCN, standard GCN, and Transformer-based approaches, TrafficKAN-GCN achieves competitive prediction accuracy while demonstrating improved robustness in handling noisy and irregular traffic data. Our experiments further highlight the framework's ability to redistribute traffic flow, mitigate congestion, and adapt to disruptive events, such as the Francis Scott Key Bridge collapse. This study contributes to the growing body of work on hybrid graph learning for intelligent transportation systems, highlighting the potential of combining KAN and GCN for real-time traffic optimization. Future work will focus on reducing computational overhead and integrating Transformer-based temporal modeling for enhanced long-term traffic prediction. The proposed TrafficKAN-GCN framework offers a promising direction for data-driven urban mobility management, balancing predictive accuracy, robustness, and computational efficiency.