 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Laziness, Decoding Suboptimality, and Context Degradation in Large Language Models
Dec 19, 2025Large Language Models (LLMs) often exhibit behavioral artifacts such as laziness (premature truncation of responses or partial compliance with multi-part requests), decoding suboptimality (failure to select higher-quality sequences due to myopic decoding), and context degradation (forgetting or ignoring core instructions over long conversations). We conducted three controlled experiments (A, B, and C) to quantify these phenomena across several advanced LLMs (OpenAI GPT-4 variant, DeepSeek). Our results indicate widespread laziness in satisfying complex multi-part instructions: models frequently omitted required sections or failed to meet length requirements despite explicit prompting. However, we found limited evidence of decoding suboptimality in a simple reasoning task (the models' greedy answers appeared to align with their highest-confidence solution), and we observed surprising robustness against context degradation in a 200-turn chaotic conversation test - the models maintained key facts and instructions far better than expected. These findings suggest that while compliance with detailed instructions remains an open challenge, modern LLMs may internally mitigate some hypothesized failure modes (such as context forgetting) in straightforward retrieval scenarios. We discuss implications for reliability, relate our findings to prior work on instruction-following and long-context processing, and recommend strategies (such as self-refinement and dynamic prompting) to reduce laziness and bolster multi-instruction compliance.
Automatic Configuration for Optimal Communication Scheduling in DNN Training
Dec 27, 2021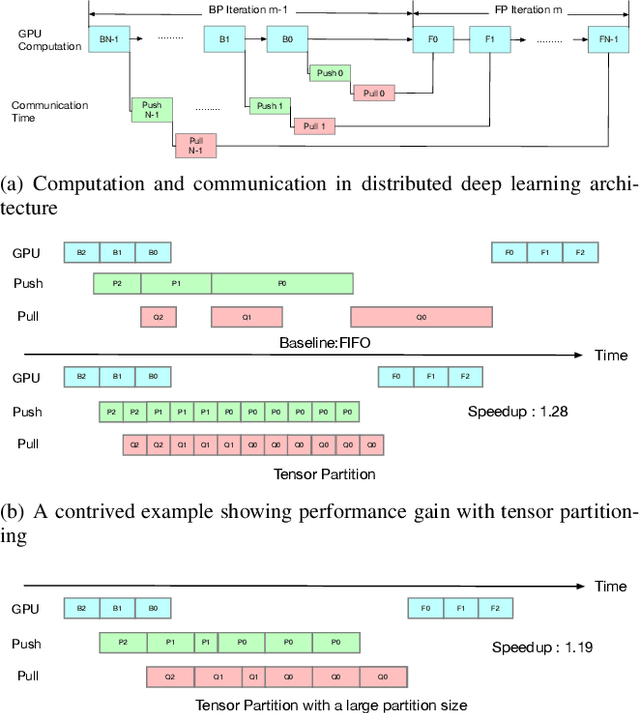
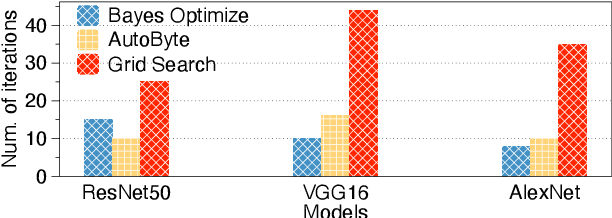
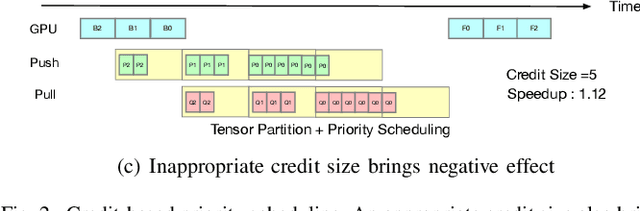
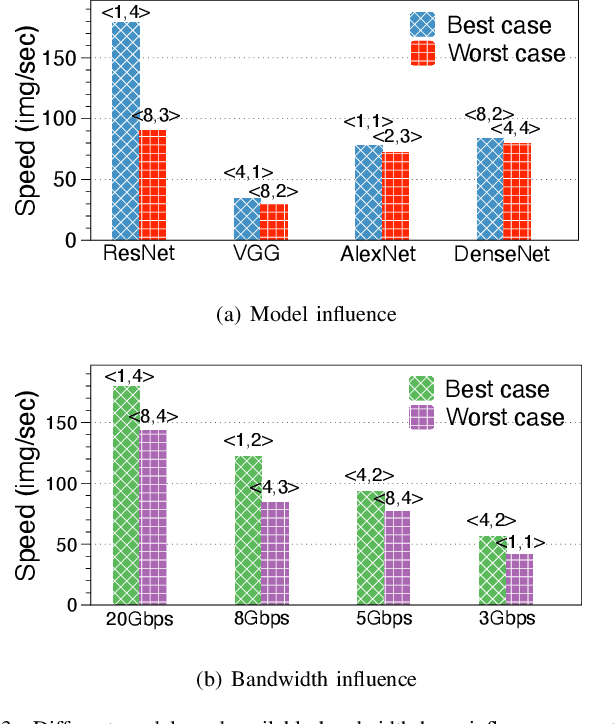
ByteScheduler partitions and rearranges tensor transmissions to improve the communication efficiency of distributed Deep Neural Network (DNN) training. The configuration of hyper-parameters (i.e., the partition size and the credit size) is critical to the effectiveness of partitioning and rearrangement. Currently, ByteScheduler adopts Bayesian Optimization (BO) to find the optimal configuration for the hyper-parameters beforehand. In practice, however, various runtime factors (e.g., worker node status and network conditions) change over time, making the statically-determined one-shot configuration result suboptimal for real-world DNN training. To address this problem, we present a real-time configuration method (called AutoByte) that automatically and timely searches the optimal hyper-parameters as the training systems dynamically change. AutoByte extends the ByteScheduler framework with a meta-network, which takes the system's runtime statistics as its input and outputs predictions for speedups under specific configurations. Evaluation results on various DNN models show that AutoByte can dynamically tune the hyper-parameters with low resource usage, and deliver up to 33.2\% higher performance than the best static configuration in ByteScheduler.