 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterMT: Multi-Turn Interleaved Preference Alignment with Human Feedback
May 29, 2025As multimodal large models (MLLMs) continue to advance across challenging tasks, a key question emerges: What essential capabilities are still missing? A critical aspect of human learning is continuous interaction with the environment -- not limited to language, but also involving multimodal understanding and generation. To move closer to human-level intelligence, models must similarly support multi-turn, multimodal interaction. In particular, they should comprehend interleaved multimodal contexts and respond coherently in ongoing exchanges. In this work, we present an initial exploration through the InterMT -- the first preference dataset for multi-turn multimodal interaction, grounded in real human feedback. In this exploration, we particularly emphasize the importance of human oversight, introducing expert annotations to guide the process, motivated by the fact that current MLLMs lack such complex interactive capabilities. InterMT captures human preferences at both global and local levels into nine sub-dimensions, consists of 15.6k prompts, 52.6k multi-turn dialogue instances, and 32.4k human-labeled preference pairs. To compensate for the lack of capability for multi-modal understanding and generation, we introduce an agentic workflow that leverages tool-augmented MLLMs to construct multi-turn QA instances. To further this goal, we introduce InterMT-Bench to assess the ability of MLLMs in assisting judges with multi-turn, multimodal tasks. We demonstrate the utility of \InterMT through applications such as judge moderation and further reveal the multi-turn scaling law of judge model. We hope the open-source of our data can help facilitate further research on aligning current MLLMs to the next step. Our project website can be found at https://pku-intermt.github.io .
Graceful Forgetting in Generative Language Models
May 26, 2025Recently, the pretrain-finetune paradigm has become a cornerstone in various deep learning areas. While in general the pre-trained model would promote both effectiveness and efficiency of downstream tasks fine-tuning, studies have shown that not all knowledge acquired during pre-training is beneficial. Some of the knowledge may actually bring detrimental effects to the fine-tuning tasks, which is also known as negative transfer. To address this problem, graceful forgetting has emerged as a promising approach. The core principle of graceful forgetting is to enhance the learning plasticity of the target task by selectively discarding irrelevant knowledge. However, this approach remains underexplored in the context of generative language models, and it is often challenging to migrate existing forgetting algorithms to these models due to architecture incompatibility. To bridge this gap, in this paper we propose a novel framework, Learning With Forgetting (LWF), to achieve graceful forgetting in generative language models. With Fisher Information Matrix weighting the intended parameter updates, LWF computes forgetting confidence to evaluate self-generated knowledge regarding the forgetting task, and consequently, knowledge with high confidence is periodically unlearned during fine-tuning. Our experiments demonstrate that, although thoroughly uncovering the mechanisms of knowledge interaction remains challenging in pre-trained language models, applying graceful forgetting can contribute to enhanced fine-tuning performance.
The Mirage of Multimodality: Where Truth is Tested and Honesty Unravels
May 26, 2025Reasoning models have recently attracted significant attention, especially for tasks that involve complex inference. Their strengths exemplify the System II paradigm (slow, structured thinking), contrasting with the System I (rapid, heuristic-driven). Yet, does slower reasoning necessarily lead to greater truthfulness? Our findings suggest otherwise. In this study, we present the first systematic investigation of distortions associated with System I and System II reasoning in multimodal contexts. We demonstrate that slower reasoning models, when presented with incomplete or misleading visual inputs, are more likely to fabricate plausible yet false details to support flawed reasoning -- a phenomenon we term the "Mirage of Multimodality". To examine this, we constructed a 5,000-sample hierarchical prompt dataset annotated by 50 human participants. These prompts gradually increase in complexity, revealing a consistent pattern: slower reasoning models tend to employ depth-first thinking (delving deeper into incorrect premises), whereas faster chat models favor breadth-first inference, exhibiting greater caution under uncertainty. Our results highlight a critical vulnerability of slower reasoning models: although highly effective in structured domains such as mathematics, it becomes brittle when confronted with ambiguous multimodal inputs.
Mitigating Deceptive Alignment via Self-Monitoring
May 24, 2025Modern large language models rely on chain-of-thought (CoT) reasoning to achieve impressive performance, yet the same mechanism can amplify deceptive alignment, situations in which a model appears aligned while covertly pursuing misaligned goals. Existing safety pipelines treat deception as a black-box output to be filtered post-hoc, leaving the model free to scheme during its internal reasoning. We ask: Can deception be intercepted while the model is thinking? We answer this question, the first framework that embeds a Self-Monitor inside the CoT process itself, named CoT Monitor+. During generation, the model produces (i) ordinary reasoning steps and (ii) an internal self-evaluation signal trained to flag and suppress misaligned strategies. The signal is used as an auxiliary reward in reinforcement learning, creating a feedback loop that rewards honest reasoning and discourages hidden goals. To study deceptive alignment systematically, we introduce DeceptionBench, a five-category benchmark that probes covert alignment-faking, sycophancy, etc. We evaluate various LLMs and show that unrestricted CoT roughly aggravates the deceptive tendency. In contrast, CoT Monitor+ cuts deceptive behaviors by 43.8% on average while preserving task accuracy. Further, when the self-monitor signal replaces an external weak judge in RL fine-tuning, models exhibit substantially fewer obfuscated thoughts and retain transparency. Our project website can be found at cot-monitor-plus.github.io
Generative RLHF-V: Learning Principles from Multi-modal Human Preference
May 24, 2025Training multi-modal large language models (MLLMs) that align with human intentions is a long-term challenge. Traditional score-only reward models for alignment suffer from low accuracy, weak generalization, and poor interpretability, blocking the progress of alignment methods, e.g., reinforcement learning from human feedback (RLHF). Generative reward models (GRMs) leverage MLLMs' intrinsic reasoning capabilities to discriminate pair-wise responses, but their pair-wise paradigm makes it hard to generalize to learnable rewards. We introduce Generative RLHF-V, a novel alignment framework that integrates GRMs with multi-modal RLHF. We propose a two-stage pipeline: $\textbf{multi-modal generative reward modeling from RL}$, where RL guides GRMs to actively capture human intention, then predict the correct pair-wise scores; and $\textbf{RL optimization from grouped comparison}$, which enhances multi-modal RL scoring precision by grouped responses comparison. Experimental results demonstrate that, besides out-of-distribution generalization of RM discrimination, our framework improves 4 MLLMs' performance across 7 benchmarks by $18.1\%$, while the baseline RLHF is only $5.3\%$. We further validate that Generative RLHF-V achieves a near-linear improvement with an increasing number of candidate responses. Our code and models can be found at https://generative-rlhf-v.github.io.
J1: Exploring Simple Test-Time Scaling for LLM-as-a-Judge
May 17, 2025



The current focus of AI research is shifting from emphasizing model training towards enhancing evaluation quality, a transition that is crucial for driving further advancements in AI systems. Traditional evaluation methods typically rely on reward models assigning scalar preference scores to outputs. Although effective, such approaches lack interpretability, leaving users often uncertain about why a reward model rates a particular response as high or low. The advent of LLM-as-a-Judge provides a more scalable and interpretable method of supervision, offering insights into the decision-making process. Moreover, with the emergence of large reasoning models, which consume more tokens for deeper thinking and answer refinement, scaling test-time computation in the LLM-as-a-Judge paradigm presents an avenue for further boosting performance and providing more interpretability through reasoning traces. In this paper, we introduce $\textbf{J1-7B}$, which is first supervised fine-tuned on reflection-enhanced datasets collected via rejection-sampling and subsequently trained using Reinforcement Learning (RL) with verifiable rewards. At inference time, we apply Simple Test-Time Scaling (STTS) strategies for additional performance improvement. Experimental results demonstrate that $\textbf{J1-7B}$ surpasses the previous state-of-the-art LLM-as-a-Judge by $ \textbf{4.8}$\% and exhibits a $ \textbf{5.1}$\% stronger scaling trend under STTS. Additionally, we present three key findings: (1) Existing LLM-as-a-Judge does not inherently exhibit such scaling trend. (2) Model simply fine-tuned on reflection-enhanced datasets continues to demonstrate similarly weak scaling behavior. (3) Significant scaling trend emerges primarily during the RL phase, suggesting that effective STTS capability is acquired predominantly through RL training.
CMD: Controllable Multiview Diffusion for 3D Editing and Progressive Generation
May 11, 2025Recently, 3D generation methods have shown their powerful ability to automate 3D model creation. However, most 3D generation methods only rely on an input image or a text prompt to generate a 3D model, which lacks the control of each component of the generated 3D model. Any modifications of the input image lead to an entire regeneration of the 3D models. In this paper, we introduce a new method called CMD that generates a 3D model from an input image while enabling flexible local editing of each component of the 3D model. In CMD, we formulate the 3D generation as a conditional multiview diffusion model, which takes the existing or known parts as conditions and generates the edited or added components. This conditional multiview diffusion model not only allows the generation of 3D models part by part but also enables local editing of 3D models according to the local revision of the input image without changing other 3D parts. Extensive experiments are conducted to demonstrate that CMD decomposes a complex 3D generation task into multiple components, improving the generation quality. Meanwhile, CMD enables efficient and flexible local editing of a 3D model by just editing one rendered image.
Measuring Hong Kong Massive Multi-Task Language Understanding
May 04, 2025Multilingual understanding is crucial for the cross-cultural applicability of Large Language Models (LLMs). However, evaluation benchmarks designed for Hong Kong's unique linguistic landscape, which combines Traditional Chinese script with Cantonese as the spoken form and its cultural context, remain underdeveloped. To address this gap, we introduce HKMMLU, a multi-task language understanding benchmark that evaluates Hong Kong's linguistic competence and socio-cultural knowledge. The HKMMLU includes 26,698 multi-choice questions across 66 subjects, organized into four categories: Science, Technology, Engineering, and Mathematics (STEM), Social Sciences, Humanities, and Other. To evaluate the multilingual understanding ability of LLMs, 90,550 Mandarin-Cantonese translation tasks were additionally included. We conduct comprehensive experiments on GPT-4o, Claude 3.7 Sonnet, and 18 open-source LLMs of varying sizes on HKMMLU. The results show that the best-performing model, DeepSeek-V3, struggles to achieve an accuracy of 75\%, significantly lower than that of MMLU and CMMLU. This performance gap highlights the need to improve LLMs' capabilities in Hong Kong-specific language and knowledge domains. Furthermore, we investigate how question language, model size, prompting strategies, and question and reasoning token lengths affect model performance. We anticipate that HKMMLU will significantly advance the development of LLMs in multilingual and cross-cultural contexts, thereby enabling broader and more impactful applications.
Co$^{3}$Gesture: Towards Coherent Concurrent Co-speech 3D Gesture Generation with Interactive Diffusion
May 03, 2025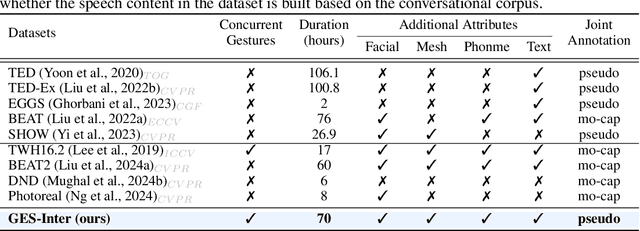

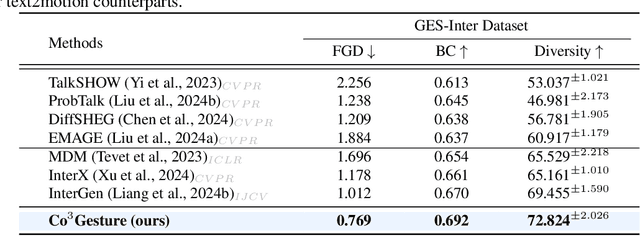
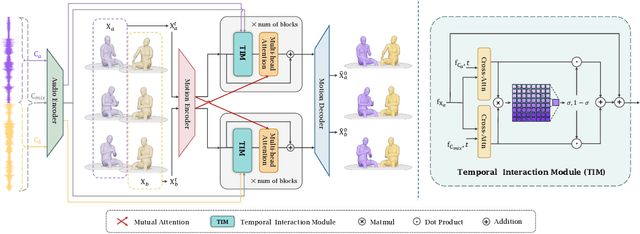
Generating gestures from human speech has gained tremendous progress in animating virtual avatars. While the existing methods enable synthesizing gestures cooperated by individual self-talking, they overlook the practicality of concurrent gesture modeling with two-person interactive conversations. Moreover, the lack of high-quality datasets with concurrent co-speech gestures also limits handling this issue. To fulfill this goal, we first construct a large-scale concurrent co-speech gesture dataset that contains more than 7M frames for diverse two-person interactive posture sequences, dubbed GES-Inter. Additionally, we propose Co$^3$Gesture, a novel framework that enables coherent concurrent co-speech gesture synthesis including two-person interactive movements. Considering the asymmetric body dynamics of two speakers, our framework is built upon two cooperative generation branches conditioned on separated speaker audio. Specifically, to enhance the coordination of human postures with respect to corresponding speaker audios while interacting with the conversational partner, we present a Temporal Interaction Module (TIM). TIM can effectively model the temporal association representation between two speakers' gesture sequences as interaction guidance and fuse it into the concurrent gesture generation. Then, we devise a mutual attention mechanism to further holistically boost learning dependencies of interacted concurrent motions, thereby enabling us to generate vivid and coherent gestures. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on our newly collected GES-Inter dataset. The dataset and source code are publicly available at \href{https://mattie-e.github.io/Co3/}{\textit{https://mattie-e.github.io/Co3/}}.
Benchmarking Multi-National Value Alignment for Large Language Models
Apr 19, 2025



Do Large Language Models (LLMs) hold positions that conflict with your country's values? Occasionally they do! However, existing works primarily focus on ethical reviews, failing to capture the diversity of national values, which encompass broader policy, legal, and moral considerations. Furthermore, current benchmarks that rely on spectrum tests using manually designed questionnaires are not easily scalable. To address these limitations, we introduce NaVAB, a comprehensive benchmark to evaluate the alignment of LLMs with the values of five major nations: China, the United States, the United Kingdom, France, and Germany. NaVAB implements a national value extraction pipeline to efficiently construct value assessment datasets. Specifically, we propose a modeling procedure with instruction tagging to process raw data sources, a screening process to filter value-related topics and a generation process with a Conflict Reduction mechanism to filter non-conflicting values.We conduct extensive experiments on various LLMs across countries, and the results provide insights into assisting in the identification of misaligned scenarios. Moreover, we demonstrate that NaVAB can be combined with alignment techniques to effectively reduce value concerns by aligning LLMs' values with the target country.