 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedInsightBench: Evaluating Medical Analytics Agents Through Multi-Step Insight Discovery in Multimodal Medical Data
Dec 15, 2025In medical data analysis, extracting deep insights from complex, multi-modal datasets is essential for improving patient care, increasing diagnostic accuracy, and optimizing healthcare operations. However, there is currently a lack of high-quality datasets specifically designed to evaluate the ability of large multi-modal models (LMMs) to discover medical insights. In this paper, we introduce MedInsightBench, the first benchmark that comprises 332 carefully curated medical cases, each annotated with thoughtfully designed insights. This benchmark is intended to evaluate the ability of LMMs and agent frameworks to analyze multi-modal medical image data, including posing relevant questions, interpreting complex findings, and synthesizing actionable insights and recommendations. Our analysis indicates that existing LMMs exhibit limited performance on MedInsightBench, which is primarily attributed to their challenges in extracting multi-step, deep insights and the absence of medical expertise. Therefore, we propose MedInsightAgent, an automated agent framework for medical data analysis, composed of three modules: Visual Root Finder, Analytical Insight Agent, and Follow-up Question Composer. Experiments on MedInsightBench highlight pervasive challenges and demonstrate that MedInsightAgent can improve the performance of general LMMs in medical data insight discovery.
SafeLawBench: Towards Safe Alignment of Large Language Models
Jun 07, 2025



With the growing prevalence of large language models (LLMs), the safety of LLMs has raised significant concerns. However, there is still a lack of definitive standards for evaluating their safety due to the subjective nature of current safety benchmarks. To address this gap, we conducted the first exploration of LLMs' safety evaluation from a legal perspective by proposing the SafeLawBench benchmark. SafeLawBench categorizes safety risks into three levels based on legal standards, providing a systematic and comprehensive framework for evaluation. It comprises 24,860 multi-choice questions and 1,106 open-domain question-answering (QA) tasks. Our evaluation included 2 closed-source LLMs and 18 open-source LLMs using zero-shot and few-shot prompting, highlighting the safety features of each model. We also evaluated the LLMs' safety-related reasoning stability and refusal behavior. Additionally, we found that a majority voting mechanism can enhance model performance. Notably, even leading SOTA models like Claude-3.5-Sonnet and GPT-4o have not exceeded 80.5% accuracy in multi-choice tasks on SafeLawBench, while the average accuracy of 20 LLMs remains at 68.8\%. We urge the community to prioritize research on the safety of LLMs.
Measuring Hong Kong Massive Multi-Task Language Understanding
May 04, 2025Multilingual understanding is crucial for the cross-cultural applicability of Large Language Models (LLMs). However, evaluation benchmarks designed for Hong Kong's unique linguistic landscape, which combines Traditional Chinese script with Cantonese as the spoken form and its cultural context, remain underdeveloped. To address this gap, we introduce HKMMLU, a multi-task language understanding benchmark that evaluates Hong Kong's linguistic competence and socio-cultural knowledge. The HKMMLU includes 26,698 multi-choice questions across 66 subjects, organized into four categories: Science, Technology, Engineering, and Mathematics (STEM), Social Sciences, Humanities, and Other. To evaluate the multilingual understanding ability of LLMs, 90,550 Mandarin-Cantonese translation tasks were additionally included. We conduct comprehensive experiments on GPT-4o, Claude 3.7 Sonnet, and 18 open-source LLMs of varying sizes on HKMMLU. The results show that the best-performing model, DeepSeek-V3, struggles to achieve an accuracy of 75\%, significantly lower than that of MMLU and CMMLU. This performance gap highlights the need to improve LLMs' capabilities in Hong Kong-specific language and knowledge domains. Furthermore, we investigate how question language, model size, prompting strategies, and question and reasoning token lengths affect model performance. We anticipate that HKMMLU will significantly advance the development of LLMs in multilingual and cross-cultural contexts, thereby enabling broader and more impactful applications.
Separating the EoR Signal with a Convolutional Denoising Autoencoder: A Deep-learning-based Method
Mar 14, 2019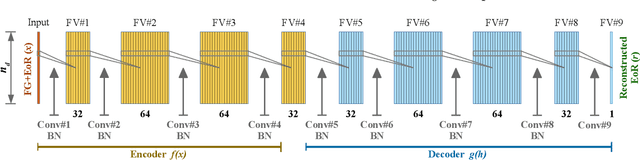
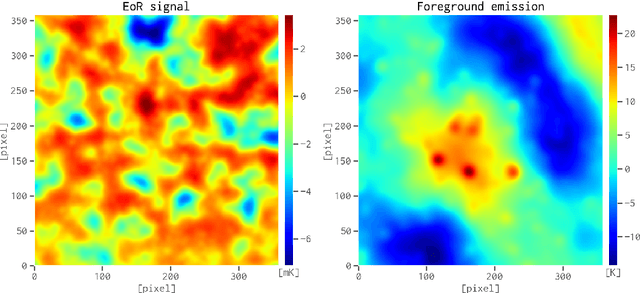
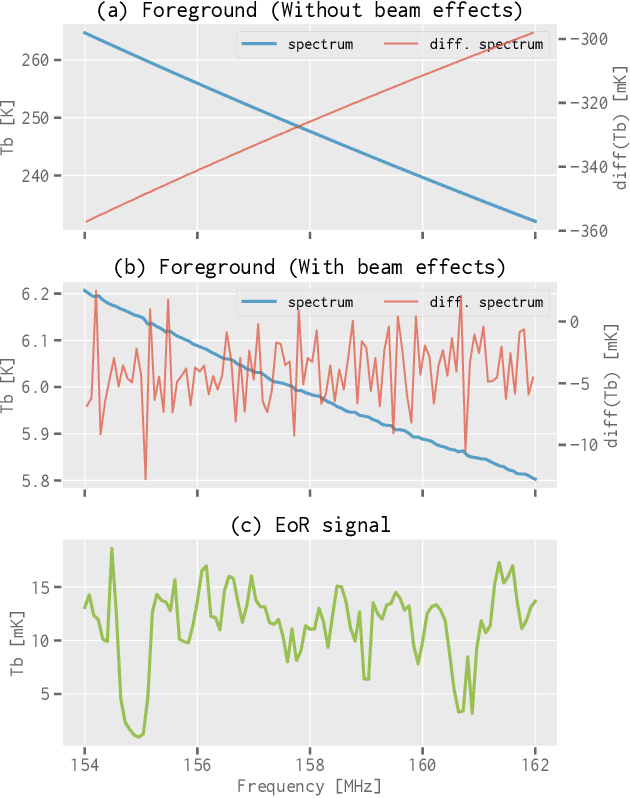
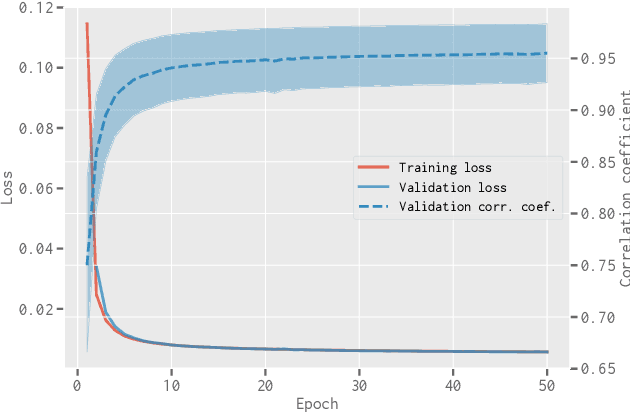
When applying the foreground removal methods to uncover the faint cosmological signal from the epoch of reionization (EoR), the foreground spectra are assumed to be smooth. However, this assumption can be seriously violated in practice since the unresolved or mis-subtracted foreground sources, which are further complicated by the frequency-dependent beam effects of interferometers, will generate significant fluctuations along the frequency dimension. To address this issue, we propose a novel deep-learning-based method that uses a 9-layer convolutional denoising autoencoder (CDAE) to separate the EoR signal. After being trained on the SKA images simulated with realistic beam effects, the CDAE achieves excellent performance as the mean correlation coefficient ($\bar{\rho}$) between the reconstructed and input EoR signals reaches $0.929 \pm 0.045$. In comparison, the two representative traditional methods, namely the polynomial fitting method and the continuous wavelet transform method, both have difficulties in modelling and removing the foreground emission complicated with the beam effects, yielding only $\bar{\rho}_{\text{poly}} = 0.296 \pm 0.121$ and $\bar{\rho}_{\text{cwt}} = 0.198 \pm 0.160$, respectively. We conclude that, by hierarchically learning sophisticated features through multiple convolutional layers, the CDAE is a powerful tool that can be used to overcome the complicated beam effects and accurately separate the EoR signal. Our results also exhibit the great potential of deep-learning-based methods in future EoR experiments.
* 10 pages, 9 figures; minor text updates to match the MNRAS published version