 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetoxification for LLM: From Dataset Itself
Apr 21, 2026Existing detoxification methods for large language models mainly focus on post-training stage or inference time, while few tackle the source of toxicity, namely, the dataset itself. Such training-based or controllable decoding approaches cannot completely suppress the model's inherent toxicity, whereas detoxifying the pretraining dataset can fundamentally reduce the toxicity that the model learns during training. Hence, we attempt to detoxify directly on raw corpora with SoCD (Soft Contrastive Decoding), which guides an LLM to localize and rewrite toxic spans in raw data while preserving semantics, in our proposed HSPD (Hierarchical Semantic-Preserving Detoxification) pipeline, yielding a detoxified corpus that can drop-in replace the original for fine-tuning or other training. On GPT2-XL, HSPD attains state-of-the-art detoxification, reducing Toxicity Probability (TP) from 0.42 to 0.18 and Expected Maximum Toxicity (EMT) from 0.43 to 0.20. We further validate consistent best-in-class results on LLaMA2-7B, OPT-6.7B, and Falcon-7B. These findings show that semantics-preserving, corpus-level rewriting with HSPD effectively suppresses downstream toxicity while retaining data utility and allowing seamless source-level mitigation, thereby reducing the cost of later model behavior adjustment. (Code is available at: https://github.com/ntsw2001/data_detox_for_llm)
Unlocking the Value of Text: Event-Driven Reasoning and Multi-Level Alignment for Time Series Forecasting
Mar 16, 2026Existing time series forecasting methods primarily rely on the numerical data itself. However, real-world time series exhibit complex patterns associated with multimodal information, making them difficult to predict with numerical data alone. While several multimodal time series forecasting methods have emerged, they either utilize text with limited supplementary information or focus merely on representation extraction, extracting minimal textual information for forecasting. To unlock the Value of Text, we propose VoT, a method with Event-driven Reasoning and Multi-level Alignment. Event-driven Reasoning combines the rich information in exogenous text with the powerful reasoning capabilities of LLMs for time series forecasting. To guide the LLMs in effective reasoning, we propose the Historical In-context Learning that retrieves and applies historical examples as in-context guidance. To maximize the utilization of text, we propose Multi-level Alignment. At the representation level, we utilize the Endogenous Text Alignment to integrate the endogenous text information with the time series. At the prediction level, we design the Adaptive Frequency Fusion to fuse the frequency components of event-driven prediction and numerical prediction to achieve complementary advantages. Experiments on real-world datasets across 10 domains demonstrate significant improvements over existing methods, validating the effectiveness of our approach in the utilization of text. The code is made available at https://github.com/decisionintelligence/VoT.
Multimodal Peer Review Simulation with Actionable To-Do Recommendations for Community-Aware Manuscript Revisions
Nov 14, 2025



While large language models (LLMs) offer promising capabilities for automating academic workflows, existing systems for academic peer review remain constrained by text-only inputs, limited contextual grounding, and a lack of actionable feedback. In this work, we present an interactive web-based system for multimodal, community-aware peer review simulation to enable effective manuscript revisions before paper submission. Our framework integrates textual and visual information through multimodal LLMs, enhances review quality via retrieval-augmented generation (RAG) grounded in web-scale OpenReview data, and converts generated reviews into actionable to-do lists using the proposed Action:Objective[\#] format, providing structured and traceable guidance. The system integrates seamlessly into existing academic writing platforms, providing interactive interfaces for real-time feedback and revision tracking. Experimental results highlight the effectiveness of the proposed system in generating more comprehensive and useful reviews aligned with expert standards, surpassing ablated baselines and advancing transparent, human-centered scholarly assistance.
CC-Time: Cross-Model and Cross-Modality Time Series Forecasting
Aug 17, 2025



With the success of pre-trained language models (PLMs) in various application fields beyond natural language processing, language models have raised emerging attention in the field of time series forecasting (TSF) and have shown great prospects. However, current PLM-based TSF methods still fail to achieve satisfactory prediction accuracy matching the strong sequential modeling power of language models. To address this issue, we propose Cross-Model and Cross-Modality Learning with PLMs for time series forecasting (CC-Time). We explore the potential of PLMs for time series forecasting from two aspects: 1) what time series features could be modeled by PLMs, and 2) whether relying solely on PLMs is sufficient for building time series models. In the first aspect, CC-Time incorporates cross-modality learning to model temporal dependency and channel correlations in the language model from both time series sequences and their corresponding text descriptions. In the second aspect, CC-Time further proposes the cross-model fusion block to adaptively integrate knowledge from the PLMs and time series model to form a more comprehensive modeling of time series patterns. Extensive experiments on nine real-world datasets demonstrate that CC-Time achieves state-of-the-art prediction accuracy in both full-data training and few-shot learning situations.
LightGTS: A Lightweight General Time Series Forecasting Model
Jun 06, 2025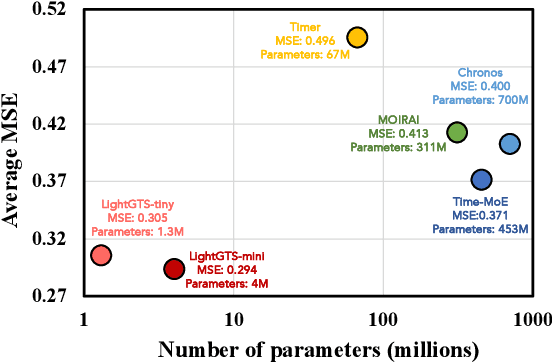
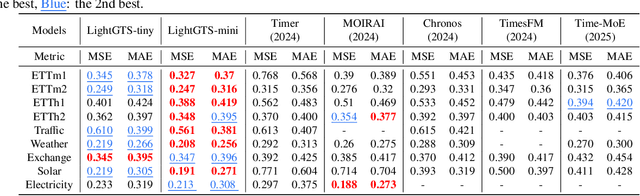
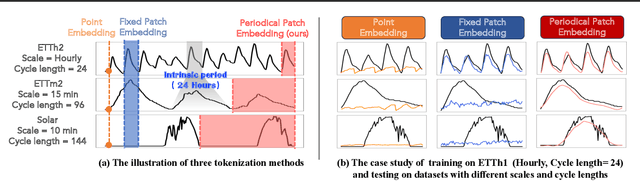
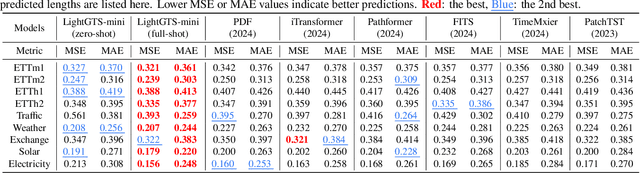
Existing works on general time series forecasting build foundation models with heavy model parameters through large-scale multi-source pre-training. These models achieve superior generalization ability across various datasets at the cost of significant computational burdens and limitations in resource-constrained scenarios. This paper introduces LightGTS, a lightweight general time series forecasting model designed from the perspective of consistent periodical modeling. To handle diverse scales and intrinsic periods in multi-source pre-training, we introduce Periodical Tokenization, which extracts consistent periodic patterns across different datasets with varying scales. To better utilize the periodicity in the decoding process, we further introduce Periodical Parallel Decoding, which leverages historical tokens to improve forecasting. Based on the two techniques above which fully leverage the inductive bias of periods inherent in time series, LightGTS uses a lightweight model to achieve outstanding performance on general time series forecasting. It achieves state-of-the-art forecasting performance on 9 real-world benchmarks in both zero-shot and full-shot settings with much better efficiency compared with existing time series foundation models.
Mitigating mode collapse in normalizing flows by annealing with an adaptive schedule: Application to parameter estimation
May 06, 2025Normalizing flows (NFs) provide uncorrelated samples from complex distributions, making them an appealing tool for parameter estimation. However, the practical utility of NFs remains limited by their tendency to collapse to a single mode of a multimodal distribution. In this study, we show that annealing with an adaptive schedule based on the effective sample size (ESS) can mitigate mode collapse. We demonstrate that our approach can converge the marginal likelihood for a biochemical oscillator model fit to time-series data in ten-fold less computation time than a widely used ensemble Markov chain Monte Carlo (MCMC) method. We show that the ESS can also be used to reduce variance by pruning the samples. We expect these developments to be of general use for sampling with NFs and discuss potential opportunities for further improvements.
Graph Foundation Models for Recommendation: A Comprehensive Survey
Feb 12, 2025



Recommender systems (RS) serve as a fundamental tool for navigating the vast expanse of online information, with deep learning advancements playing an increasingly important role in improving ranking accuracy. Among these, graph neural networks (GNNs) excel at extracting higher-order structural information, while large language models (LLMs) are designed to process and comprehend natural language, making both approaches highly effective and widely adopted. Recent research has focused on graph foundation models (GFMs), which integrate the strengths of GNNs and LLMs to model complex RS problems more efficiently by leveraging the graph-based structure of user-item relationships alongside textual understanding. In this survey, we provide a comprehensive overview of GFM-based RS technologies by introducing a clear taxonomy of current approaches, diving into methodological details, and highlighting key challenges and future directions. By synthesizing recent advancements, we aim to offer valuable insights into the evolving landscape of GFM-based recommender systems.
CATCH: Channel-Aware multivariate Time Series Anomaly Detection via Frequency Patching
Oct 16, 2024



Anomaly detection in multivariate time series is challenging as heterogeneous subsequence anomalies may occur. Reconstruction-based methods, which focus on learning nomral patterns in the frequency domain to detect diverse abnormal subsequences, achieve promising resutls, while still falling short on capturing fine-grained frequency characteristics and channel correlations. To contend with the limitations, we introduce CATCH, a framework based on frequency patching. We propose to patchify the frequency domain into frequency bands, which enhances its ability to capture fine-grained frequency characteristics. To perceive appropriate channel correlations, we propose a Channel Fusion Module (CFM), which features a patch-wise mask generator and a masked-attention mechanism. Driven by a bi-level multi-objective optimization algorithm, the CFM is encouraged to iteratively discover appropriate patch-wise channel correlations, and to cluster relevant channels while isolating adverse effects from irrelevant channels. Extensive experiments on 9 real-world datasets and 12 synthetic datasets demonstrate that CATCH achieves state-of-the-art performance.
FoundTS: Comprehensive and Unified Benchmarking of Foundation Models for Time Series Forecasting
Oct 15, 2024



Time Series Forecasting (TSF) is key functionality in numerous fields, including in finance, weather services, and energy management. While TSF methods are emerging these days, many of them require domain-specific data collection and model training and struggle with poor generalization performance on new domains. Foundation models aim to overcome this limitation. Pre-trained on large-scale language or time series data, they exhibit promising inferencing capabilities in new or unseen data. This has spurred a surge in new TSF foundation models. We propose a new benchmark, FoundTS, to enable thorough and fair evaluation and comparison of such models. FoundTS covers a variety of TSF foundation models, including those based on large language models and those pretrained on time series. Next, FoundTS supports different forecasting strategies, including zero-shot, few-shot, and full-shot, thereby facilitating more thorough evaluations. Finally, FoundTS offers a pipeline that standardizes evaluation processes such as dataset splitting, loading, normalization, and few-shot sampling, thereby facilitating fair evaluations. Building on this, we report on an extensive evaluation of TSF foundation models on a broad range of datasets from diverse domains and with different statistical characteristics. Specifically, we identify pros and cons and inherent limitations of existing foundation models, and we identify directions for future model design. We make our code and datasets available at https://anonymous.4open.science/r/FoundTS-C2B0.
QUITO-X: An Information Bottleneck-based Compression Algorithm with Cross-Attention
Aug 20, 2024Generative LLM have achieved significant success in various industrial tasks and can effectively adapt to vertical domains and downstream tasks through ICL. However, with tasks becoming increasingly complex, the context length required by ICL is also getting longer, and two significant issues arise: (i) The excessively long context leads to high costs and inference delays. (ii) A substantial amount of task-irrelevant information introduced by long contexts exacerbates the "lost in the middle" problem. Recently, compressing prompts by removing tokens according to some metric obtained from some causal language models, such as llama-7b, has emerged as an effective approach to mitigate these issues. However, the metric used by prior method such as self-information or PPL do not fully align with the objective of distinuishing the most important tokens when conditioning on query. In this work, we introduce information bottleneck theory to carefully examine the properties required by the metric. Inspired by this, we use cross-attention in encoder-decoder architecture as a new metric. Our simple method leads to significantly better performance in smaller models with lower latency. We evaluate our method on four datasets: DROP, CoQA, SQuAD, and Quoref. The experimental results show that, while maintaining the same performance, our compression rate can improve by nearly 25% over previous SOTA. Remarkably, in experiments where 25% of the tokens are removed, our model's EM score for answers sometimes even exceeds that of the control group using uncompressed text as context.