 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetoxification for LLM: From Dataset Itself
Apr 21, 2026Existing detoxification methods for large language models mainly focus on post-training stage or inference time, while few tackle the source of toxicity, namely, the dataset itself. Such training-based or controllable decoding approaches cannot completely suppress the model's inherent toxicity, whereas detoxifying the pretraining dataset can fundamentally reduce the toxicity that the model learns during training. Hence, we attempt to detoxify directly on raw corpora with SoCD (Soft Contrastive Decoding), which guides an LLM to localize and rewrite toxic spans in raw data while preserving semantics, in our proposed HSPD (Hierarchical Semantic-Preserving Detoxification) pipeline, yielding a detoxified corpus that can drop-in replace the original for fine-tuning or other training. On GPT2-XL, HSPD attains state-of-the-art detoxification, reducing Toxicity Probability (TP) from 0.42 to 0.18 and Expected Maximum Toxicity (EMT) from 0.43 to 0.20. We further validate consistent best-in-class results on LLaMA2-7B, OPT-6.7B, and Falcon-7B. These findings show that semantics-preserving, corpus-level rewriting with HSPD effectively suppresses downstream toxicity while retaining data utility and allowing seamless source-level mitigation, thereby reducing the cost of later model behavior adjustment. (Code is available at: https://github.com/ntsw2001/data_detox_for_llm)
Time2Graph: Revisiting Time Series Modeling with Dynamic Shapelets
Nov 11, 2019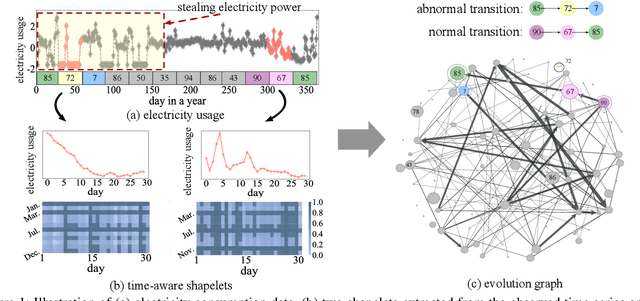
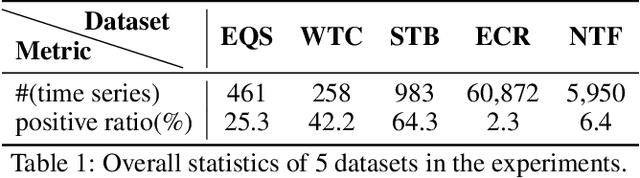
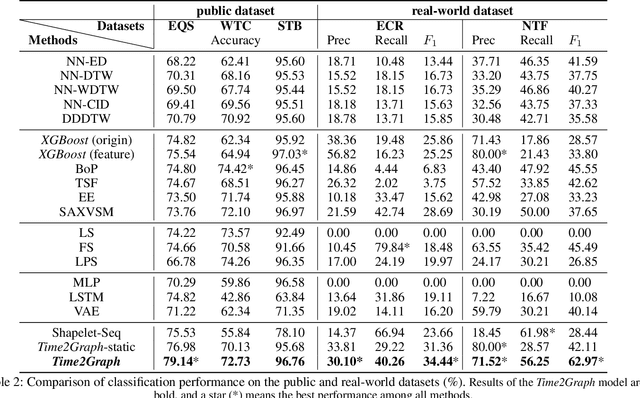
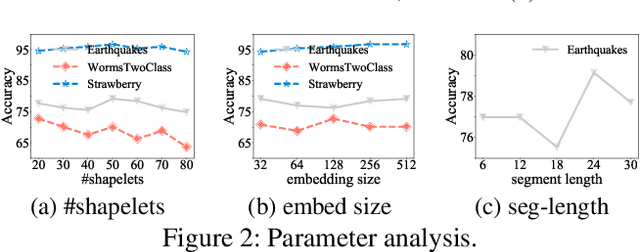
Time series modeling has attracted extensive research efforts; however, achieving both reliable efficiency and interpretability from a unified model still remains a challenging problem. Among the literature, shapelets offer interpretable and explanatory insights in the classification tasks, while most existing works ignore the differing representative power at different time slices, as well as (more importantly) the evolution pattern of shapelets. In this paper, we propose to extract time-aware shapelets by designing a two-level timing factor. Moreover, we define and construct the shapelet evolution graph, which captures how shapelets evolve over time and can be incorporated into the time series embeddings by graph embedding algorithms. To validate whether the representations obtained in this way can be applied effectively in various scenarios, we conduct experiments based on three public time series datasets, and two real-world datasets from different domains. Experimental results clearly show the improvements achieved by our approach compared with 17 state-of-the-art baselines.