 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightGTS: A Lightweight General Time Series Forecasting Model
Jun 06, 2025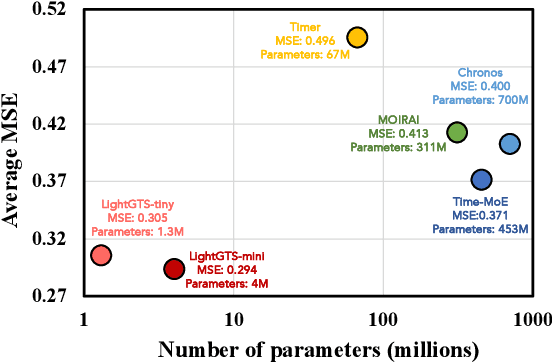
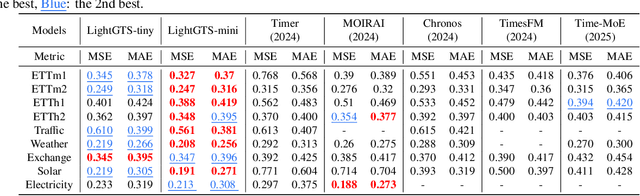
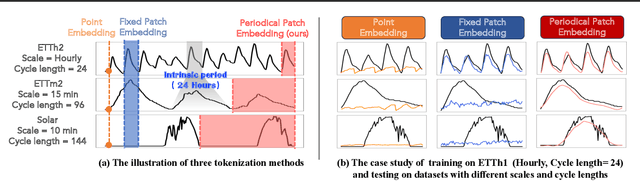
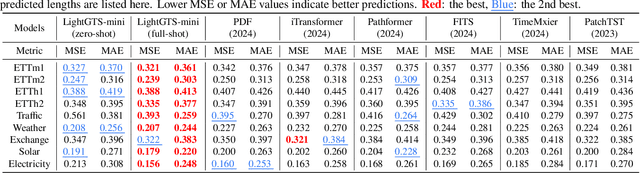
Existing works on general time series forecasting build foundation models with heavy model parameters through large-scale multi-source pre-training. These models achieve superior generalization ability across various datasets at the cost of significant computational burdens and limitations in resource-constrained scenarios. This paper introduces LightGTS, a lightweight general time series forecasting model designed from the perspective of consistent periodical modeling. To handle diverse scales and intrinsic periods in multi-source pre-training, we introduce Periodical Tokenization, which extracts consistent periodic patterns across different datasets with varying scales. To better utilize the periodicity in the decoding process, we further introduce Periodical Parallel Decoding, which leverages historical tokens to improve forecasting. Based on the two techniques above which fully leverage the inductive bias of periods inherent in time series, LightGTS uses a lightweight model to achieve outstanding performance on general time series forecasting. It achieves state-of-the-art forecasting performance on 9 real-world benchmarks in both zero-shot and full-shot settings with much better efficiency compared with existing time series foundation models.
ROSE: Register Assisted General Time Series Forecasting with Decomposed Frequency Learning
May 24, 2024With the increasing collection of time series data from various domains, there arises a strong demand for general time series forecasting models pre-trained on a large number of time-series datasets to support a variety of downstream prediction tasks. Enabling general time series forecasting faces two challenges: how to obtain unified representations from multi-domian time series data, and how to capture domain-specific features from time series data across various domains for adaptive transfer in downstream tasks. To address these challenges, we propose a Register Assisted General Time Series Forecasting Model with Decomposed Frequency Learning (ROSE), a novel pre-trained model for time series forecasting. ROSE employs Decomposed Frequency Learning for the pre-training task, which decomposes coupled semantic and periodic information in time series with frequency-based masking and reconstruction to obtain unified representations across domains. We also equip ROSE with a Time Series Register, which learns to generate a register codebook to capture domain-specific representations during pre-training and enhances domain-adaptive transfer by selecting related register tokens on downstream tasks. After pre-training on large-scale time series data, ROSE achieves state-of-the-art forecasting performance on 8 real-world benchmarks. Remarkably, even in few-shot scenarios, it demonstrates competitive or superior performance compared to existing methods trained with full data.