 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Feature Learning in Gated Delta Networks at Scale
Jun 02, 2026Training and scaling Large Language Models demand enormous computational resources, motivating both efficient sub-quadratic architectures and principled hyperparameter tuning methods. While the Maximal Update Parametrization ($μ$P) has enabled zero-shot hyperparameter transfer for standard Transformers, its extension to linear models, particularly those with structured state transitions and complicated architectures, remains largely unexplored. By rigorously propagating coordinate-size estimates through the forward pass, gating mechanisms, and recurrent state dynamics, we derive the scaling rules for Gated Delta Network. Experiments on language-model pre-training confirm that our configurations enable stable learning-rate transfer across model widths under both AdamW and SGD, whereas standard parametrization fails to transfer, validating the correctness and practical utility of our analysis.
Self-Distilled Policy Gradient
Jun 02, 2026On-policy self-distillation, where a language model conditions on privileged context to supervise its own generations, is a promising source of dense supervision for sparse-reward reinforcement learning. Actually, it can be instantiated as an auxiliary full-vocabulary student-to-teacher reverse Kullback-Leibler divergence loss. We therefore propose SDPG, a self-distilled policy-gradient framework that combines group-relative verifier advantages with normalized standard deviation, exact full-vocabulary on-policy self-distillation, as well as reference-policy KL regularization. Empirically, SDPG improves stability and performance over RLVR and self-distillation baselines. The code is available at https://github.com/lauyikfung/SDPG.
Mending the Holes: Mitigating Reward Hacking in Reinforcement Learning for Multilingual Translation
Mar 13, 2026Large Language Models (LLMs) have demonstrated remarkable capability in machine translation on high-resource language pairs, yet their performance on low-resource translation still lags behind. Existing post-training methods rely heavily on high-quality parallel data, which are often scarce or unavailable for low-resource languages. In this paper, we introduce WALAR, a reinforcement training method using only monolingual text to elevate LLMs' translation capabilities on massive low-resource languages while retaining their performance on high-resource languages. Our key insight is based on the observation of failure modes (or "holes") in existing source-based multilingual quality estimation (QE) models. Reinforcement learning (RL) using these QE models tends to amplify such holes, resulting in poorer multilingual LLMs. We develop techniques including word alignment and language alignment to mitigate such holes in WALAR's reward for RL training. We continually trained an LLM supporting translation of 101 languages using WALAR. The experiments show that our new model outperforms LLaMAX, one of the strongest open-source multilingual LLMs by a large margin on 1400 language directions on Flores-101 dataset.
Deep Delta Learning
Jan 01, 2026The efficacy of deep residual networks is fundamentally predicated on the identity shortcut connection. While this mechanism effectively mitigates the vanishing gradient problem, it imposes a strictly additive inductive bias on feature transformations, thereby limiting the network's capacity to model complex state transitions. In this paper, we introduce Deep Delta Learning (DDL), a novel architecture that generalizes the standard residual connection by modulating the identity shortcut with a learnable, data-dependent geometric transformation. This transformation, termed the Delta Operator, constitutes a rank-1 perturbation of the identity matrix, parameterized by a reflection direction vector $\mathbf{k}(\mathbf{X})$ and a gating scalar $β(\mathbf{X})$. We provide a spectral analysis of this operator, demonstrating that the gate $β(\mathbf{X})$ enables dynamic interpolation between identity mapping, orthogonal projection, and geometric reflection. Furthermore, we restructure the residual update as a synchronous rank-1 injection, where the gate acts as a dynamic step size governing both the erasure of old information and the writing of new features. This unification empowers the network to explicitly control the spectrum of its layer-wise transition operator, enabling the modeling of complex, non-monotonic dynamics while preserving the stable training characteristics of gated residual architectures.
Group Representational Position Encoding
Dec 08, 2025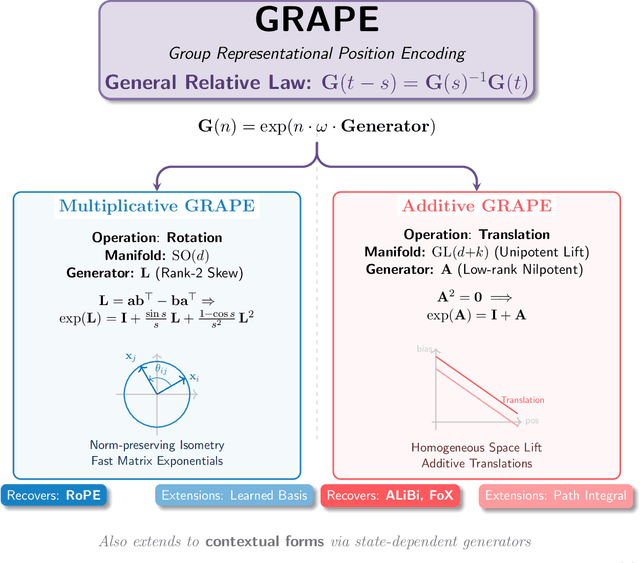
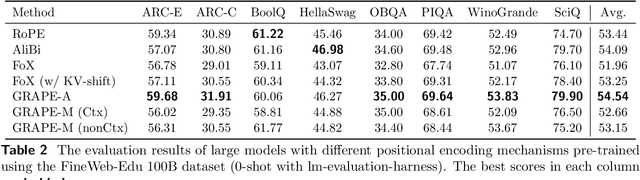
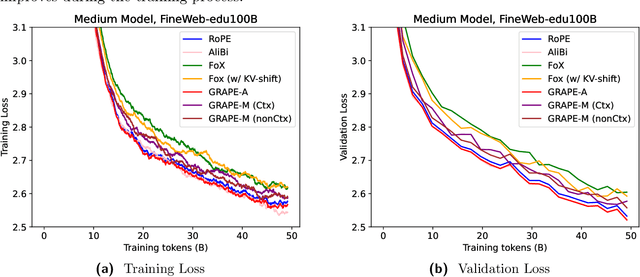

We present GRAPE (Group RepresentAtional Position Encoding), a unified framework for positional encoding based on group actions. GRAPE brings together two families of mechanisms: (i) multiplicative rotations (Multiplicative GRAPE) in $\mathrm{SO}(d)$ and (ii) additive logit biases (Additive GRAPE) arising from unipotent actions in the general linear group $\mathrm{GL}$. In Multiplicative GRAPE, a position $n \in \mathbb{Z}$ (or $t \in \mathbb{R}$) acts as $\mathbf{G}(n)=\exp(n\,ω\,\mathbf{L})$ with a rank-2 skew generator $\mathbf{L} \in \mathbb{R}^{d \times d}$, yielding a relative, compositional, norm-preserving map with a closed-form matrix exponential. RoPE is recovered exactly when the $d/2$ planes are the canonical coordinate pairs with log-uniform spectrum. Learned commuting subspaces and compact non-commuting mixtures strictly extend this geometry to capture cross-subspace feature coupling at $O(d)$ and $O(r d)$ cost per head, respectively. In Additive GRAPE, additive logits arise as rank-1 (or low-rank) unipotent actions, recovering ALiBi and the Forgetting Transformer (FoX) as exact special cases while preserving an exact relative law and streaming cacheability. Altogether, GRAPE supplies a principled design space for positional geometry in long-context models, subsuming RoPE and ALiBi as special cases. Project Page: https://github.com/model-architectures/GRAPE.
On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning
May 23, 2025Policy gradient algorithms have been successfully applied to enhance the reasoning capabilities of large language models (LLMs). Despite the widespread use of Kullback-Leibler (KL) regularization in policy gradient algorithms to stabilize training, the systematic exploration of how different KL divergence formulations can be estimated and integrated into surrogate loss functions for online reinforcement learning (RL) presents a nuanced and systematically explorable design space. In this paper, we propose regularized policy gradient (RPG), a systematic framework for deriving and analyzing KL-regularized policy gradient methods in the online RL setting. We derive policy gradients and corresponding surrogate loss functions for objectives regularized by both forward and reverse KL divergences, considering both normalized and unnormalized policy distributions. Furthermore, we present derivations for fully differentiable loss functions as well as REINFORCE-style gradient estimators, accommodating diverse algorithmic needs. We conduct extensive experiments on RL for LLM reasoning using these methods, showing improved or competitive results in terms of training stability and performance compared to strong baselines such as GRPO, REINFORCE++, and DAPO. The code is available at https://github.com/complex-reasoning/RPG.
R-PRM: Reasoning-Driven Process Reward Modeling
Mar 27, 2025



Large language models (LLMs) inevitably make mistakes when performing step-by-step mathematical reasoning. Process Reward Models (PRMs) have emerged as a promising solution by evaluating each reasoning step. However, existing PRMs typically output evaluation scores directly, limiting both learning efficiency and evaluation accuracy, which is further exacerbated by the scarcity of annotated data. To address these issues, we propose Reasoning-Driven Process Reward Modeling (R-PRM). First, we leverage stronger LLMs to generate seed data from limited annotations, effectively bootstrapping our model's reasoning capabilities and enabling comprehensive step-by-step evaluation. Second, we further enhance performance through preference optimization, without requiring additional annotated data. Third, we introduce inference-time scaling to fully harness the model's reasoning potential. Extensive experiments demonstrate R-PRM's effectiveness: on ProcessBench and PRMBench, it surpasses strong baselines by 11.9 and 8.5 points in F1 scores, respectively. When applied to guide mathematical reasoning, R-PRM achieves consistent accuracy improvements of over 8.5 points across six challenging datasets. Further analysis reveals that R-PRM exhibits more comprehensive evaluation and stronger generalization capabilities, thereby highlighting its significant potential.
A Survey of Zero-Knowledge Proof Based Verifiable Machine Learning
Feb 25, 2025



As machine learning technologies advance rapidly across various domains, concerns over data privacy and model security have grown significantly. These challenges are particularly pronounced when models are trained and deployed on cloud platforms or third-party servers due to the computational resource limitations of users' end devices. In response, zero-knowledge proof (ZKP) technology has emerged as a promising solution, enabling effective validation of model performance and authenticity in both training and inference processes without disclosing sensitive data. Thus, ZKP ensures the verifiability and security of machine learning models, making it a valuable tool for privacy-preserving AI. Although some research has explored the verifiable machine learning solutions that exploit ZKP, a comprehensive survey and summary of these efforts remain absent. This survey paper aims to bridge this gap by reviewing and analyzing all the existing Zero-Knowledge Machine Learning (ZKML) research from June 2017 to December 2024. We begin by introducing the concept of ZKML and outlining its ZKP algorithmic setups under three key categories: verifiable training, verifiable inference, and verifiable testing. Next, we provide a comprehensive categorization of existing ZKML research within these categories and analyze the works in detail. Furthermore, we explore the implementation challenges faced in this field and discuss the improvement works to address these obstacles. Additionally, we highlight several commercial applications of ZKML technology. Finally, we propose promising directions for future advancements in this domain.
Tensor Product Attention Is All You Need
Jan 11, 2025



Scaling language models to handle longer input sequences typically necessitates large key-value (KV) caches, resulting in substantial memory overhead during inference. In this paper, we propose Tensor Product Attention (TPA), a novel attention mechanism that uses tensor decompositions to represent queries, keys, and values compactly, significantly shrinking KV cache size at inference time. By factorizing these representations into contextual low-rank components (contextual factorization) and seamlessly integrating with RoPE, TPA achieves improved model quality alongside memory efficiency. Based on TPA, we introduce the Tensor ProducT ATTenTion Transformer (T6), a new model architecture for sequence modeling. Through extensive empirical evaluation of language modeling tasks, we demonstrate that T6 exceeds the performance of standard Transformer baselines including MHA, MQA, GQA, and MLA across various metrics, including perplexity and a range of renowned evaluation benchmarks. Notably, TPAs memory efficiency enables the processing of significantly longer sequences under fixed resource constraints, addressing a critical scalability challenge in modern language models. The code is available at https://github.com/tensorgi/T6.
MARS: Unleashing the Power of Variance Reduction for Training Large Models
Nov 15, 2024



Training deep neural networks--and more recently, large models--demands efficient and scalable optimizers. Adaptive gradient algorithms like Adam, AdamW, and their variants have been central to this task. Despite the development of numerous variance reduction algorithms in the past decade aimed at accelerating stochastic optimization in both convex and nonconvex settings, variance reduction has not found widespread success in training deep neural networks or large language models. Consequently, it has remained a less favored approach in modern AI. In this paper, to unleash the power of variance reduction for efficient training of large models, we propose a unified optimization framework, MARS (Make vAriance Reduction Shine), which reconciles preconditioned gradient methods with variance reduction via a scaled stochastic recursive momentum technique. Within our framework, we introduce three instances of MARS that leverage preconditioned gradient updates based on AdamW, Lion, and Shampoo, respectively. We also draw a connection between our algorithms and existing optimizers. Experimental results on training GPT-2 models indicate that MARS consistently outperforms AdamW by a large margin.