 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGM-SLAM: Scene Graph Matching for Data-Efficient Distributed SLAM
Jun 15, 2026We introduce a data-efficient distributed Simultaneous Localization and Mapping (SLAM) framework designed for a team of robots equipped with LiDAR, cameras, and inertial sensors. Our framework uses scene graph matching to identify inter-robot measurement constraints. Unlike prior approaches that rely on feature-level matching, our framework is the first to perform scene graph matching using only object labels and centroids. Our approach constructs a scene graph by using fused RGB-LiDAR point clouds to generate both a semantically segmented point cloud layer, and a layer of discrete bounded objects, to accompany estimated robot trajectories. Scene graph matching is performed collaboratively through exchanging and matching object data with neighboring robots. To maximize communication efficiency, we utilize a multi-step data exchange and optimization process. We demonstrate the effectiveness and efficiency of our approach using both simulation and real-world datasets collected by legged robots in indoor and outdoor environments.
Above and Below: Heterogeneous Multi-robot SLAM Across Surface and Underwater Domains
May 10, 2026Multi-robot simultaneous localization and mapping (SLAM) is a fundamental task in multi-robot operations. Robots must have a common understanding of their location and that of their team members to complete coordinated actions. However, multi-robot SLAM between Uncrewed Surface Vessels (USVs) and Autonomous Underwater Vehicles (AUVs) has primarily been achieved through acoustic pinging between robots to retrieve range measurements; a measurement technique requires that robots to be in similar locations simultaneously, have an uninterrupted path for signal propagation, and may necessitate synchronized clocks. This is especially challenging in complex, cluttered maritime environments, where structures may impede signals. However, these same structures may be observable above and below the water's surface, presenting an opportunity for inter-robot SLAM loop closure between USV and AUV data streams. This work builds upon recent research on inter-robot SLAM loop closure between USV and AUV data, extending it to propose a centralized multi-robot SLAM system. Each robot performs its state estimation, and we detect loop closures between each AUV and the USV data. These inter-robot loop closures are used to merge each robot's state estimate into a centralized graph, yielding estimates for the whole time history of the USV and all AUVs in the system. Validation is performed using real-world perceptual data in three different environments. Results show improved errors for AUVs in the multi-robot SLAM system compared to single-robot SLAM over the same trajectories. To our knowledge, this is the first instance of a multi-robot SLAM system with AUVs and USVs built on loop closures rather than acoustic distance measurements.
dWorldEval: Scalable Robotic Policy Evaluation via Discrete Diffusion World Model
Apr 24, 2026Evaluating robotics policies across thousands of environments and thousands of tasks is infeasible with existing approaches. This motivates the need for a new methodology for scalable robotics policy evaluation. In this paper, we propose dWorldEval, which uses a discrete diffusion world model as a scalable evaluation proxy for robotics policies. Specifically, dWorldEval maps all modalities - including vision, language, and robotic actions - into a unified token space, modeling them via a single transformer-based denoising network. In this paper, we propose dWorldEval, using a discrete diffusion world model as a scalable evaluation proxy for robotics policy. Specifically, it maps all modalities, including vision, language, and robotics action into a unified token space, then denoises them with a single transformer network. Building on this architecture, we employ a sparse keyframe memory to maintain spatiotemporal consistency. We also introduce a progress token that indicates the degree of task completion. At inference, the model jointly predicts future observations and progress token, allowing automatically determine success when the progress reaches 1. Extensive experiments demonstrate that dWorldEval significantly outperforms previous approaches, i.e., WorldEval, Ctrl-World, and WorldGym, on LIBERO, RoboTwin, and multiple real-robot tasks. It paves the way for a new architectural paradigm in building world simulators for robotics evaluation at scale.
Hi-WM: Human-in-the-World-Model for Scalable Robot Post-Training
Apr 23, 2026Post-training is essential for turning pretrained generalist robot policies into reliable task-specific controllers, but existing human-in-the-loop pipelines remain tied to physical execution: each correction requires robot time, scene setup, resets, and operator supervision in the real world. Meanwhile, action-conditioned world models have been studied mainly for imagination, synthetic data generation, and policy evaluation. We propose \textbf{Human-in-the-World-Model (Hi-WM)}, a post-training framework that uses a learned world model as a reusable corrective substrate for failure-targeted policy improvement. A policy is first rolled out in closed loop inside the world model; when the rollout becomes incorrect or failure-prone, a human intervenes directly in the model to provide short corrective actions. Hi-WM caches intermediate states and supports rollback and branching, allowing a single failure state to be reused for multiple corrective continuations and yielding dense supervision around behaviors that the base policy handles poorly. The resulting corrective trajectories are then added back to the training set for post-training. We evaluate Hi-WM on three real-world manipulation tasks spanning both rigid and deformable object interaction, and on two policy backbones. Hi-WM improves real-world success by 37.9 points on average over the base policy and by 19.0 points over a world-model closed-loop baseline, while world-model evaluation correlates strongly with real-world performance (r = 0.953). These results suggest that world models can serve not only as generators or evaluators, but also as effective corrective substrates for scalable robot post-training.
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Apr 14, 2026On-policy distillation (OPD) has become a core technique in the post-training of large language models, yet its training dynamics remain poorly understood. This paper provides a systematic investigation of OPD dynamics and mechanisms. We first identify that two conditions govern whether OPD succeeds or fails: (i) the student and teacher should share compatible thinking patterns; and (ii) even with consistent thinking patterns and higher scores, the teacher must offer genuinely new capabilities beyond what the student has seen during training. We validate these findings through weak-to-strong reverse distillation, showing that same-family 1.5B and 7B teachers are distributionally indistinguishable from the student's perspective. Probing into the token-level mechanism, we show that successful OPD is characterized by progressive alignment on high-probability tokens at student-visited states, a small shared token set that concentrates most of the probability mass (97%-99%). We further propose two practical strategies to recover failing OPD: off-policy cold start and teacher-aligned prompt selection. Finally, we show that OPD's apparent free lunch of dense token-level reward comes at a cost, raising the question of whether OPD can scale to long-horizon distillation.
Towards High-Consistency Embodied World Model with Multi-View Trajectory Videos
Nov 19, 2025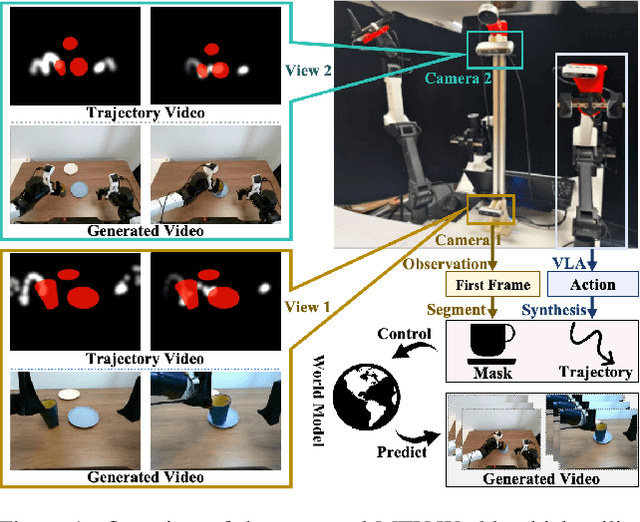

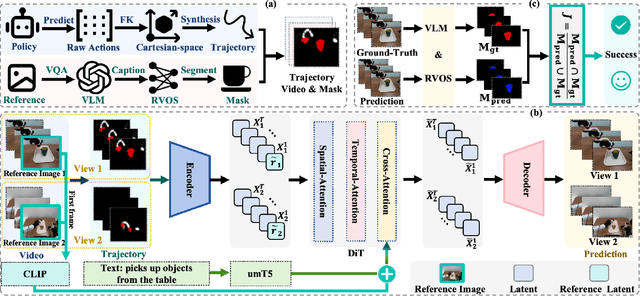
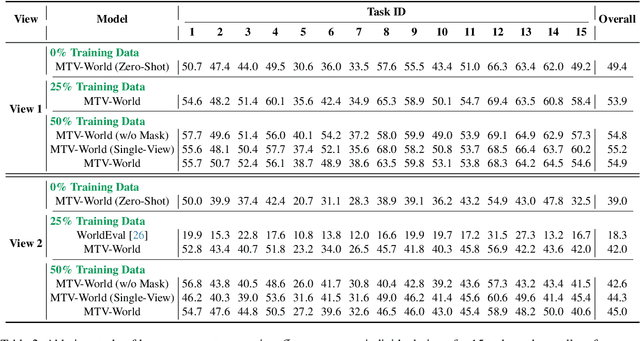
Embodied world models aim to predict and interact with the physical world through visual observations and actions. However, existing models struggle to accurately translate low-level actions (e.g., joint positions) into precise robotic movements in predicted frames, leading to inconsistencies with real-world physical interactions. To address these limitations, we propose MTV-World, an embodied world model that introduces Multi-view Trajectory-Video control for precise visuomotor prediction. Specifically, instead of directly using low-level actions for control, we employ trajectory videos obtained through camera intrinsic and extrinsic parameters and Cartesian-space transformation as control signals. However, projecting 3D raw actions onto 2D images inevitably causes a loss of spatial information, making a single view insufficient for accurate interaction modeling. To overcome this, we introduce a multi-view framework that compensates for spatial information loss and ensures high-consistency with physical world. MTV-World forecasts future frames based on multi-view trajectory videos as input and conditioning on an initial frame per view. Furthermore, to systematically evaluate both robotic motion precision and object interaction accuracy, we develop an auto-evaluation pipeline leveraging multimodal large models and referring video object segmentation models. To measure spatial consistency, we formulate it as an object location matching problem and adopt the Jaccard Index as the evaluation metric. Extensive experiments demonstrate that MTV-World achieves precise control execution and accurate physical interaction modeling in complex dual-arm scenarios.
WorldEval: World Model as Real-World Robot Policies Evaluator
May 25, 2025The field of robotics has made significant strides toward developing generalist robot manipulation policies. However, evaluating these policies in real-world scenarios remains time-consuming and challenging, particularly as the number of tasks scales and environmental conditions change. In this work, we demonstrate that world models can serve as a scalable, reproducible, and reliable proxy for real-world robot policy evaluation. A key challenge is generating accurate policy videos from world models that faithfully reflect the robot actions. We observe that directly inputting robot actions or using high-dimensional encoding methods often fails to generate action-following videos. To address this, we propose Policy2Vec, a simple yet effective approach to turn a video generation model into a world simulator that follows latent action to generate the robot video. We then introduce WorldEval, an automated pipeline designed to evaluate real-world robot policies entirely online. WorldEval effectively ranks various robot policies and individual checkpoints within a single policy, and functions as a safety detector to prevent dangerous actions by newly developed robot models. Through comprehensive paired evaluations of manipulation policies in real-world environments, we demonstrate a strong correlation between policy performance in WorldEval and real-world scenarios. Furthermore, our method significantly outperforms popular methods such as real-to-sim approach.
Speech Audio Generation from dynamic MRI via a Knowledge Enhanced Conditional Variational Autoencoder
Mar 09, 2025



Dynamic Magnetic Resonance Imaging (MRI) of the vocal tract has become an increasingly adopted imaging modality for speech motor studies. Beyond image signals, systematic data loss, noise pollution, and audio file corruption can occur due to the unpredictability of the MRI acquisition environment. In such cases, generating audio from images is critical for data recovery in both clinical and research applications. However, this remains challenging due to hardware constraints, acoustic interference, and data corruption. Existing solutions, such as denoising and multi-stage synthesis methods, face limitations in audio fidelity and generalizability. To address these challenges, we propose a Knowledge Enhanced Conditional Variational Autoencoder (KE-CVAE), a novel two-step "knowledge enhancement + variational inference" framework for generating speech audio signals from cine dynamic MRI sequences. This approach introduces two key innovations: (1) integration of unlabeled MRI data for knowledge enhancement, and (2) a variational inference architecture to improve generative modeling capacity. To the best of our knowledge, this is one of the first attempts at synthesizing speech audio directly from dynamic MRI video sequences. The proposed method was trained and evaluated on an open-source dynamic vocal tract MRI dataset recorded during speech. Experimental results demonstrate its effectiveness in generating natural speech waveforms while addressing MRI-specific acoustic challenges, outperforming conventional deep learning-based synthesis approaches.
A Two-Stage Pretraining-Finetuning Framework for Treatment Effect Estimation with Unmeasured Confounding
Jan 15, 2025

Estimating the conditional average treatment effect (CATE) from observational data plays a crucial role in areas such as e-commerce, healthcare, and economics. Existing studies mainly rely on the strong ignorability assumption that there are no unmeasured confounders, whose presence cannot be tested from observational data and can invalidate any causal conclusion. In contrast, data collected from randomized controlled trials (RCT) do not suffer from confounding, but are usually limited by a small sample size. In this paper, we propose a two-stage pretraining-finetuning (TSPF) framework using both large-scale observational data and small-scale RCT data to estimate the CATE in the presence of unmeasured confounding. In the first stage, a foundational representation of covariates is trained to estimate counterfactual outcomes through large-scale observational data. In the second stage, we propose to train an augmented representation of the covariates, which is concatenated to the foundational representation obtained in the first stage to adjust for the unmeasured confounding. To avoid overfitting caused by the small-scale RCT data in the second stage, we further propose a partial parameter initialization approach, rather than training a separate network. The superiority of our approach is validated on two public datasets with extensive experiments. The code is available at https://github.com/zhouchuanCN/KDD25-TSPF.
DAIL: Data Augmentation for In-Context Learning via Self-Paraphrase
Nov 06, 2023



In-Context Learning (ICL) combined with pre-trained large language models has achieved promising results on various NLP tasks. However, ICL requires high-quality annotated demonstrations which might not be available in real-world scenarios. To overcome this limitation, we propose \textbf{D}ata \textbf{A}ugmentation for \textbf{I}n-Context \textbf{L}earning (\textbf{DAIL}). DAIL leverages the intuition that large language models are more familiar with the content generated by themselves. It first utilizes the language model to generate paraphrases of the test sample and employs majority voting to determine the final result based on individual predictions. Our extensive empirical evaluation shows that DAIL outperforms the standard ICL method and other ensemble-based methods in the low-resource scenario. Additionally, we explore the use of voting consistency as a confidence score of the model when the logits of predictions are inaccessible. We believe our work will stimulate further research on ICL in low-resource settings.