 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation-Supervised Convolutional Low-Rank Adaptation for Efficient Image Super-Resolution
Apr 15, 2025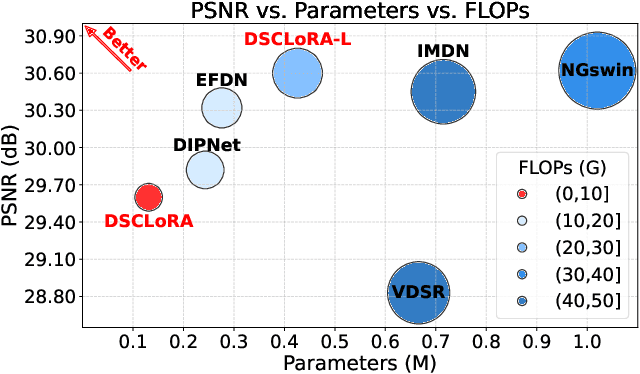
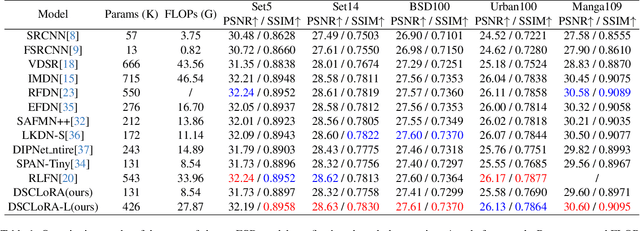
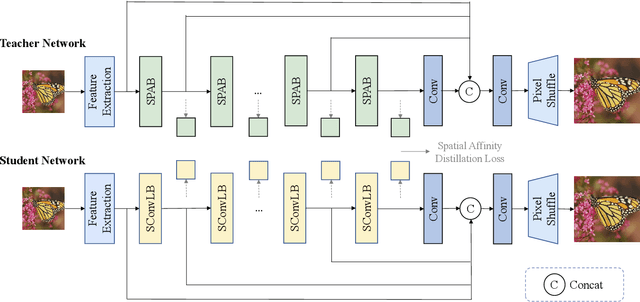

Convolutional neural networks (CNNs) have been widely used in efficient image super-resolution. However, for CNN-based methods, performance gains often require deeper networks and larger feature maps, which increase complexity and inference costs. Inspired by LoRA's success in fine-tuning large language models, we explore its application to lightweight models and propose Distillation-Supervised Convolutional Low-Rank Adaptation (DSCLoRA), which improves model performance without increasing architectural complexity or inference costs. Specifically, we integrate ConvLoRA into the efficient SR network SPAN by replacing the SPAB module with the proposed SConvLB module and incorporating ConvLoRA layers into both the pixel shuffle block and its preceding convolutional layer. DSCLoRA leverages low-rank decomposition for parameter updates and employs a spatial feature affinity-based knowledge distillation strategy to transfer second-order statistical information from teacher models (pre-trained SPAN) to student models (ours). This method preserves the core knowledge of lightweight models and facilitates optimal solution discovery under certain conditions. Experiments on benchmark datasets show that DSCLoRA improves PSNR and SSIM over SPAN while maintaining its efficiency and competitive image quality. Notably, DSCLoRA ranked first in the Overall Performance Track of the NTIRE 2025 Efficient Super-Resolution Challenge. Our code and models are made publicly available at https://github.com/Yaozzz666/DSCF-SR.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Orchestrating Joint Offloading and Scheduling for Low-Latency Edge SLAM
Feb 23, 2025Visual Simultaneous Localization and Mapping (vSLAM) is a prevailing technology for many emerging robotic applications. Achieving real-time SLAM on mobile robotic systems with limited computational resources is challenging because the complexity of SLAM algorithms increases over time. This restriction can be lifted by offloading computations to edge servers, forming the emerging paradigm of edge-assisted SLAM. Nevertheless, the exogenous and stochastic input processes affect the dynamics of the edge-assisted SLAM system. Moreover, the requirements of clients on SLAM metrics change over time, exerting implicit and time-varying effects on the system. In this paper, we aim to push the limit beyond existing edge-assist SLAM by proposing a new architecture that can handle the input-driven processes and also satisfy clients' implicit and time-varying requirements. The key innovations of our work involve a regional feature prediction method for importance-aware local data processing, a configuration adaptation policy that integrates data compression/decompression and task offloading, and an input-dependent learning framework for task scheduling with constraint satisfaction. Extensive experiments prove that our architecture improves pose estimation accuracy and saves up to 47% of communication costs compared with a popular edge-assisted SLAM system, as well as effectively satisfies the clients' requirements.
Memory Helps, but Confabulation Misleads: Understanding Streaming Events in Videos with MLLMs
Feb 21, 2025Multimodal large language models (MLLMs) have demonstrated strong performance in understanding videos holistically, yet their ability to process streaming videos-videos are treated as a sequence of visual events-remains underexplored. Intuitively, leveraging past events as memory can enrich contextual and temporal understanding of the current event. In this paper, we show that leveraging memories as contexts helps MLLMs better understand video events. However, because such memories rely on predictions of preceding events, they may contain misinformation, leading to confabulation and degraded performance. To address this, we propose a confabulation-aware memory modification method that mitigates confabulated memory for memory-enhanced event understanding.
Listen to the Patient: Enhancing Medical Dialogue Generation with Patient Hallucination Detection and Mitigation
Oct 08, 2024



Medical dialogue systems aim to provide medical services through patient-agent conversations. Previous methods typically regard patients as ideal users, focusing mainly on common challenges in dialogue systems, while neglecting the potential biases or misconceptions that might be introduced by real patients, who are typically non-experts. This study investigates the discrepancy between patients' expressions during medical consultations and their actual health conditions, defined as patient hallucination. Such phenomena often arise from patients' lack of knowledge and comprehension, concerns, and anxieties, resulting in the transmission of inaccurate or wrong information during consultations. To address this issue, we propose MedPH, a Medical dialogue generation method for mitigating the problem of Patient Hallucinations designed to detect and cope with hallucinations. MedPH incorporates a detection method that utilizes one-dimensional structural entropy over a temporal dialogue entity graph, and a mitigation strategy based on hallucination-related information to guide patients in expressing their actual conditions. Experimental results indicate the high effectiveness of MedPH when compared to existing approaches in both medical entity prediction and response generation tasks, while also demonstrating its effectiveness in mitigating hallucinations within interactive scenarios.
FedBiP: Heterogeneous One-Shot Federated Learning with Personalized Latent Diffusion Models
Oct 07, 2024



One-Shot Federated Learning (OSFL), a special decentralized machine learning paradigm, has recently gained significant attention. OSFL requires only a single round of client data or model upload, which reduces communication costs and mitigates privacy threats compared to traditional FL. Despite these promising prospects, existing methods face challenges due to client data heterogeneity and limited data quantity when applied to real-world OSFL systems. Recently, Latent Diffusion Models (LDM) have shown remarkable advancements in synthesizing high-quality images through pretraining on large-scale datasets, thereby presenting a potential solution to overcome these issues. However, directly applying pretrained LDM to heterogeneous OSFL results in significant distribution shifts in synthetic data, leading to performance degradation in classification models trained on such data. This issue is particularly pronounced in rare domains, such as medical imaging, which are underrepresented in LDM's pretraining data. To address this challenge, we propose Federated Bi-Level Personalization (FedBiP), which personalizes the pretrained LDM at both instance-level and concept-level. Hereby, FedBiP synthesizes images following the client's local data distribution without compromising the privacy regulations. FedBiP is also the first approach to simultaneously address feature space heterogeneity and client data scarcity in OSFL. Our method is validated through extensive experiments on three OSFL benchmarks with feature space heterogeneity, as well as on challenging medical and satellite image datasets with label heterogeneity. The results demonstrate the effectiveness of FedBiP, which substantially outperforms other OSFL methods.
Posterior Conformal Prediction
Sep 29, 2024



Conformal prediction is a popular technique for constructing prediction intervals with distribution-free coverage guarantees. The coverage is marginal, meaning it only holds on average over the entire population but not necessarily for any specific subgroup. This article introduces a new method, posterior conformal prediction (PCP), which generates prediction intervals with both marginal and approximate conditional validity for clusters (or subgroups) naturally discovered in the data. PCP achieves these guarantees by modelling the conditional conformity score distribution as a mixture of cluster distributions. Compared to other methods with approximate conditional validity, this approach produces tighter intervals, particularly when the test data is drawn from clusters that are well represented in the validation data. PCP can also be applied to guarantee conditional coverage on user-specified subgroups, in which case it achieves robust coverage on smaller subgroups within the specified subgroups. In classification, the theory underlying PCP allows for adjusting the coverage level based on the classifier's confidence, achieving significantly smaller sets than standard conformal prediction sets. We evaluate the performance of PCP on diverse datasets from socio-economic, scientific and healthcare applications.
WebPilot: A Versatile and Autonomous Multi-Agent System for Web Task Execution with Strategic Exploration
Aug 28, 2024



LLM-based autonomous agents often fail to execute complex web tasks that require dynamic interaction due to the inherent uncertainty and complexity of these environments. Existing LLM-based web agents typically rely on rigid, expert-designed policies specific to certain states and actions, which lack the flexibility and generalizability needed to adapt to unseen tasks. In contrast, humans excel by exploring unknowns, continuously adapting strategies, and resolving ambiguities through exploration. To emulate human-like adaptability, web agents need strategic exploration and complex decision-making. Monte Carlo Tree Search (MCTS) is well-suited for this, but classical MCTS struggles with vast action spaces, unpredictable state transitions, and incomplete information in web tasks. In light of this, we develop WebPilot, a multi-agent system with a dual optimization strategy that improves MCTS to better handle complex web environments. Specifically, the Global Optimization phase involves generating a high-level plan by breaking down tasks into manageable subtasks and continuously refining this plan, thereby focusing the search process and mitigating the challenges posed by vast action spaces in classical MCTS. Subsequently, the Local Optimization phase executes each subtask using a tailored MCTS designed for complex environments, effectively addressing uncertainties and managing incomplete information. Experimental results on WebArena and MiniWoB++ demonstrate the effectiveness of WebPilot. Notably, on WebArena, WebPilot achieves SOTA performance with GPT-4, achieving a 93% relative increase in success rate over the concurrent tree search-based method. WebPilot marks a significant advancement in general autonomous agent capabilities, paving the way for more advanced and reliable decision-making in practical environments.
Robust Principal Component Analysis via Discriminant Sample Weight Learning
Aug 22, 2024



Principal component analysis (PCA) is a classical feature extraction method, but it may be adversely affected by outliers, resulting in inaccurate learning of the projection matrix. This paper proposes a robust method to estimate both the data mean and the PCA projection matrix by learning discriminant sample weights from data containing outliers. Each sample in the dataset is assigned a weight, and the proposed algorithm iteratively learns the weights, the mean, and the projection matrix, respectively. Specifically, when the mean and the projection matrix are available, via fine-grained analysis of outliers, a weight for each sample is learned hierarchically so that outliers have small weights while normal samples have large weights. With the learned weights available, a weighted optimization problem is solved to estimate both the data mean and the projection matrix. Because the learned weights discriminate outliers from normal samples, the adverse influence of outliers is mitigated due to the corresponding small weights. Experiments on toy data, UCI dataset, and face dataset demonstrate the effectiveness of the proposed method in estimating the mean and the projection matrix from the data containing outliers.
Automatic Organ and Pan-cancer Segmentation in Abdomen CT: the FLARE 2023 Challenge
Aug 22, 2024Organ and cancer segmentation in abdomen Computed Tomography (CT) scans is the prerequisite for precise cancer diagnosis and treatment. Most existing benchmarks and algorithms are tailored to specific cancer types, limiting their ability to provide comprehensive cancer analysis. This work presents the first international competition on abdominal organ and pan-cancer segmentation by providing a large-scale and diverse dataset, including 4650 CT scans with various cancer types from over 40 medical centers. The winning team established a new state-of-the-art with a deep learning-based cascaded framework, achieving average Dice Similarity Coefficient scores of 92.3% for organs and 64.9% for lesions on the hidden multi-national testing set. The dataset and code of top teams are publicly available, offering a benchmark platform to drive further innovations https://codalab.lisn.upsaclay.fr/competitions/12239.