 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraHR-100K: Enhancing UHR Image Synthesis with A Large-Scale High-Quality Dataset
Oct 23, 2025



Ultra-high-resolution (UHR) text-to-image (T2I) generation has seen notable progress. However, two key challenges remain : 1) the absence of a large-scale high-quality UHR T2I dataset, and (2) the neglect of tailored training strategies for fine-grained detail synthesis in UHR scenarios. To tackle the first challenge, we introduce \textbf{UltraHR-100K}, a high-quality dataset of 100K UHR images with rich captions, offering diverse content and strong visual fidelity. Each image exceeds 3K resolution and is rigorously curated based on detail richness, content complexity, and aesthetic quality. To tackle the second challenge, we propose a frequency-aware post-training method that enhances fine-detail generation in T2I diffusion models. Specifically, we design (i) \textit{Detail-Oriented Timestep Sampling (DOTS)} to focus learning on detail-critical denoising steps, and (ii) \textit{Soft-Weighting Frequency Regularization (SWFR)}, which leverages Discrete Fourier Transform (DFT) to softly constrain frequency components, encouraging high-frequency detail preservation. Extensive experiments on our proposed UltraHR-eval4K benchmarks demonstrate that our approach significantly improves the fine-grained detail quality and overall fidelity of UHR image generation. The code is available at \href{https://github.com/NJU-PCALab/UltraHR-100k}{here}.
HiFiVFS: High Fidelity Video Face Swapping
Nov 27, 2024



Face swapping aims to generate results that combine the identity from the source with attributes from the target. Existing methods primarily focus on image-based face swapping. When processing videos, each frame is handled independently, making it difficult to ensure temporal stability. From a model perspective, face swapping is gradually shifting from generative adversarial networks (GANs) to diffusion models (DMs), as DMs have been shown to possess stronger generative capabilities. Current diffusion-based approaches often employ inpainting techniques, which struggle to preserve fine-grained attributes like lighting and makeup. To address these challenges, we propose a high fidelity video face swapping (HiFiVFS) framework, which leverages the strong generative capability and temporal prior of Stable Video Diffusion (SVD). We build a fine-grained attribute module to extract identity-disentangled and fine-grained attribute features through identity desensitization and adversarial learning. Additionally, We introduce detailed identity injection to further enhance identity similarity. Extensive experiments demonstrate that our method achieves state-of-the-art (SOTA) in video face swapping, both qualitatively and quantitatively.
Neural Material Adaptor for Visual Grounding of Intrinsic Dynamics
Oct 10, 2024



While humans effortlessly discern intrinsic dynamics and adapt to new scenarios, modern AI systems often struggle. Current methods for visual grounding of dynamics either use pure neural-network-based simulators (black box), which may violate physical laws, or traditional physical simulators (white box), which rely on expert-defined equations that may not fully capture actual dynamics. We propose the Neural Material Adaptor (NeuMA), which integrates existing physical laws with learned corrections, facilitating accurate learning of actual dynamics while maintaining the generalizability and interpretability of physical priors. Additionally, we propose Particle-GS, a particle-driven 3D Gaussian Splatting variant that bridges simulation and observed images, allowing back-propagate image gradients to optimize the simulator. Comprehensive experiments on various dynamics in terms of grounded particle accuracy, dynamic rendering quality, and generalization ability demonstrate that NeuMA can accurately capture intrinsic dynamics.
HybridBooth: Hybrid Prompt Inversion for Efficient Subject-Driven Generation
Oct 10, 2024



Recent advancements in text-to-image diffusion models have shown remarkable creative capabilities with textual prompts, but generating personalized instances based on specific subjects, known as subject-driven generation, remains challenging. To tackle this issue, we present a new hybrid framework called HybridBooth, which merges the benefits of optimization-based and direct-regression methods. HybridBooth operates in two stages: the Word Embedding Probe, which generates a robust initial word embedding using a fine-tuned encoder, and the Word Embedding Refinement, which further adapts the encoder to specific subject images by optimizing key parameters. This approach allows for effective and fast inversion of visual concepts into textual embedding, even from a single image, while maintaining the model's generalization capabilities.
PostEdit: Posterior Sampling for Efficient Zero-Shot Image Editing
Oct 07, 2024



In the field of image editing, three core challenges persist: controllability, background preservation, and efficiency. Inversion-based methods rely on time-consuming optimization to preserve the features of the initial images, which results in low efficiency due to the requirement for extensive network inference. Conversely, inversion-free methods lack theoretical support for background similarity, as they circumvent the issue of maintaining initial features to achieve efficiency. As a consequence, none of these methods can achieve both high efficiency and background consistency. To tackle the challenges and the aforementioned disadvantages, we introduce PostEdit, a method that incorporates a posterior scheme to govern the diffusion sampling process. Specifically, a corresponding measurement term related to both the initial features and Langevin dynamics is introduced to optimize the estimated image generated by the given target prompt. Extensive experimental results indicate that the proposed PostEdit achieves state-of-the-art editing performance while accurately preserving unedited regions. Furthermore, the method is both inversion- and training-free, necessitating approximately 1.5 seconds and 18 GB of GPU memory to generate high-quality results.
StyleMaster: Towards Flexible Stylized Image Generation with Diffusion Models
May 24, 2024



Stylized Text-to-Image Generation (STIG) aims to generate images based on text prompts and style reference images. We in this paper propose a novel framework dubbed as StyleMaster for this task by leveraging pretrained Stable Diffusion (SD), which tries to solve the previous problems such as insufficient style and inconsistent semantics. The enhancement lies in two novel module, namely multi-source style embedder and dynamic attention adapter. In order to provide SD with better style embeddings, we propose the multi-source style embedder considers both global and local level visual information along with textual one, which provide both complementary style-related and semantic-related knowledge. Additionally, aiming for better balance between the adaptor capacity and semantic control, the proposed dynamic attention adapter is applied to the diffusion UNet in which adaptation weights are dynamically calculated based on the style embeddings. Two objective functions are introduced to optimize the model together with denoising loss, which can further enhance semantic and style consistency. Extensive experiments demonstrate the superiority of StyleMaster over existing methods, rendering images with variable target styles while successfully maintaining the semantic information from the text prompts.
Face Adapter for Pre-Trained Diffusion Models with Fine-Grained ID and Attribute Control
May 21, 2024



Current face reenactment and swapping methods mainly rely on GAN frameworks, but recent focus has shifted to pre-trained diffusion models for their superior generation capabilities. However, training these models is resource-intensive, and the results have not yet achieved satisfactory performance levels. To address this issue, we introduce Face-Adapter, an efficient and effective adapter designed for high-precision and high-fidelity face editing for pre-trained diffusion models. We observe that both face reenactment/swapping tasks essentially involve combinations of target structure, ID and attribute. We aim to sufficiently decouple the control of these factors to achieve both tasks in one model. Specifically, our method contains: 1) A Spatial Condition Generator that provides precise landmarks and background; 2) A Plug-and-play Identity Encoder that transfers face embeddings to the text space by a transformer decoder. 3) An Attribute Controller that integrates spatial conditions and detailed attributes. Face-Adapter achieves comparable or even superior performance in terms of motion control precision, ID retention capability, and generation quality compared to fully fine-tuned face reenactment/swapping models. Additionally, Face-Adapter seamlessly integrates with various StableDiffusion models.
DiffFAE: Advancing High-fidelity One-shot Facial Appearance Editing with Space-sensitive Customization and Semantic Preservation
Mar 26, 2024



Facial Appearance Editing (FAE) aims to modify physical attributes, such as pose, expression and lighting, of human facial images while preserving attributes like identity and background, showing great importance in photograph. In spite of the great progress in this area, current researches generally meet three challenges: low generation fidelity, poor attribute preservation, and inefficient inference. To overcome above challenges, this paper presents DiffFAE, a one-stage and highly-efficient diffusion-based framework tailored for high-fidelity FAE. For high-fidelity query attributes transfer, we adopt Space-sensitive Physical Customization (SPC), which ensures the fidelity and generalization ability by utilizing rendering texture derived from 3D Morphable Model (3DMM). In order to preserve source attributes, we introduce the Region-responsive Semantic Composition (RSC). This module is guided to learn decoupled source-regarding features, thereby better preserving the identity and alleviating artifacts from non-facial attributes such as hair, clothes, and background. We further introduce a consistency regularization for our pipeline to enhance editing controllability by leveraging prior knowledge in the attention matrices of diffusion model. Extensive experiments demonstrate the superiority of DiffFAE over existing methods, achieving state-of-the-art performance in facial appearance editing.
A Generalist FaceX via Learning Unified Facial Representation
Dec 31, 2023



This work presents FaceX framework, a novel facial generalist model capable of handling diverse facial tasks simultaneously. To achieve this goal, we initially formulate a unified facial representation for a broad spectrum of facial editing tasks, which macroscopically decomposes a face into fundamental identity, intra-personal variation, and environmental factors. Based on this, we introduce Facial Omni-Representation Decomposing (FORD) for seamless manipulation of various facial components, microscopically decomposing the core aspects of most facial editing tasks. Furthermore, by leveraging the prior of a pretrained StableDiffusion (SD) to enhance generation quality and accelerate training, we design Facial Omni-Representation Steering (FORS) to first assemble unified facial representations and then effectively steer the SD-aware generation process by the efficient Facial Representation Controller (FRC). %Without any additional features, Our versatile FaceX achieves competitive performance compared to elaborate task-specific models on popular facial editing tasks. Full codes and models will be available at https://github.com/diffusion-facex/FaceX.
Learning to Aggregate and Personalize 3D Face from In-the-Wild Photo Collection
Jun 15, 2021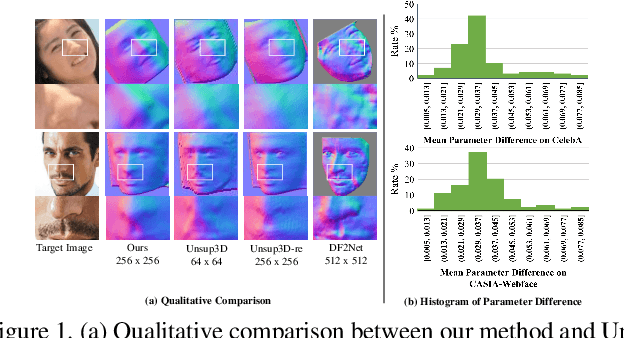
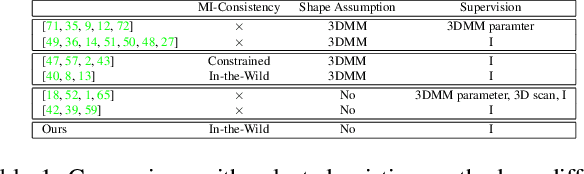
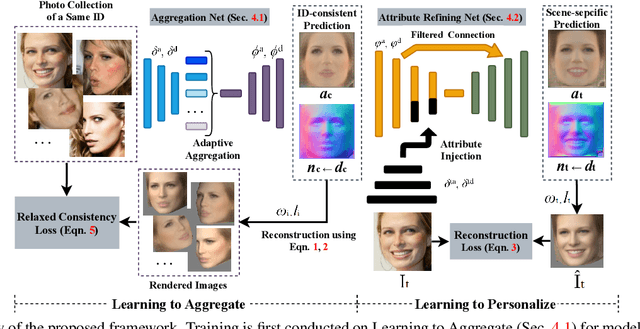
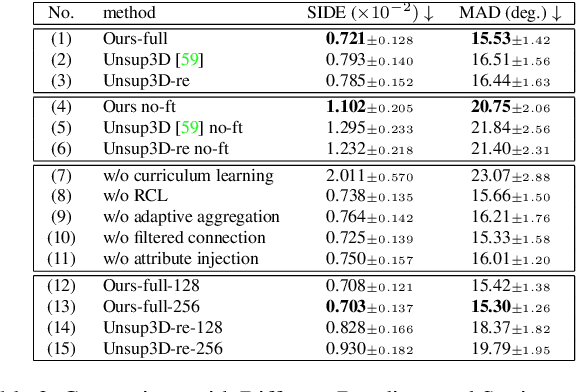
Non-parametric face modeling aims to reconstruct 3D face only from images without shape assumptions. While plausible facial details are predicted, the models tend to over-depend on local color appearance and suffer from ambiguous noise. To address such problem, this paper presents a novel Learning to Aggregate and Personalize (LAP) framework for unsupervised robust 3D face modeling. Instead of using controlled environment, the proposed method implicitly disentangles ID-consistent and scene-specific face from unconstrained photo set. Specifically, to learn ID-consistent face, LAP adaptively aggregates intrinsic face factors of an identity based on a novel curriculum learning approach with relaxed consistency loss. To adapt the face for a personalized scene, we propose a novel attribute-refining network to modify ID-consistent face with target attribute and details. Based on the proposed method, we make unsupervised 3D face modeling benefit from meaningful image facial structure and possibly higher resolutions. Extensive experiments on benchmarks show LAP recovers superior or competitive face shape and texture, compared with state-of-the-art (SOTA) methods with or without prior and supervision.