 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLO-Lab: Benchmarking Deformable Linear Object Manipulations with Differentiable Physics
Jun 02, 2026We address the challenge of enabling robots to manipulate deformable linear objects (DLOs), such as ropes, cables, and rubber bands. Prior work has primarily focused on narrow, task-specific problems, often relying on real-world demonstrations or handcrafted heuristics. Such approaches, however, struggle to scale to the wide variety of materials and tasks encountered in practice, and collecting sufficiently diverse real-world data is often impractical. Additionally, existing simulation environments offer limited support for the broad spectrum of material behaviors necessary for generalizable DLO manipulation. To overcome these limitations, we introduce a differentiable simulator explicitly designed for versatile DLO manipulation. Our simulator models a wide range of material properties-including (in)extensibility, elasticity, bending plasticity, and complex interactions with other objects-providing a robust foundation for learning and evaluating manipulation skills. Building on this simulator, we propose a benchmark suite of representative tasks that highlight the unique challenges of DLO manipulation. The successful execution of these tasks is often hindered by the topological complexity and grasp sensitivity inherent to DLOs. Therefore, we introduce a specialized DLO agent that explicitly manages these challenges by proposing strategic grasping points and decomposing long-horizon tasks to maximize control authority. Finally, we evaluate various policy-learning algorithms using our framework, alongside sim-to-real transfer experiments, demonstrating our platform's potential to advance DLO manipulation.
Patch-Discontinuity Mining for Generalized Deepfake Detection
Dec 26, 2025The rapid advancement of generative artificial intelligence has enabled the creation of highly realistic fake facial images, posing serious threats to personal privacy and the integrity of online information. Existing deepfake detection methods often rely on handcrafted forensic cues and complex architectures, achieving strong performance in intra-domain settings but suffering significant degradation when confronted with unseen forgery patterns. In this paper, we propose GenDF, a simple yet effective framework that transfers a powerful large-scale vision model to the deepfake detection task with a compact and neat network design. GenDF incorporates deepfake-specific representation learning to capture discriminative patterns between real and fake facial images, feature space redistribution to mitigate distribution mismatch, and a classification-invariant feature augmentation strategy to enhance generalization without introducing additional trainable parameters. Extensive experiments demonstrate that GenDF achieves state-of-the-art generalization performance in cross-domain and cross-manipulation settings while requiring only 0.28M trainable parameters, validating the effectiveness and efficiency of the proposed framework.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025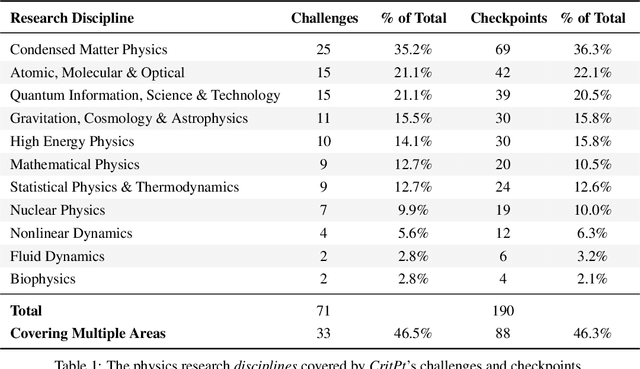



While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
SOPHY: Generating Simulation-Ready Objects with Physical Materials
Apr 17, 2025



We present SOPHY, a generative model for 3D physics-aware shape synthesis. Unlike existing 3D generative models that focus solely on static geometry or 4D models that produce physics-agnostic animations, our approach jointly synthesizes shape, texture, and material properties related to physics-grounded dynamics, making the generated objects ready for simulations and interactive, dynamic environments. To train our model, we introduce a dataset of 3D objects annotated with detailed physical material attributes, along with an annotation pipeline for efficient material annotation. Our method enables applications such as text-driven generation of interactive, physics-aware 3D objects and single-image reconstruction of physically plausible shapes. Furthermore, our experiments demonstrate that jointly modeling shape and material properties enhances the realism and fidelity of generated shapes, improving performance on generative geometry evaluation metrics.
Neural Material Adaptor for Visual Grounding of Intrinsic Dynamics
Oct 10, 2024



While humans effortlessly discern intrinsic dynamics and adapt to new scenarios, modern AI systems often struggle. Current methods for visual grounding of dynamics either use pure neural-network-based simulators (black box), which may violate physical laws, or traditional physical simulators (white box), which rely on expert-defined equations that may not fully capture actual dynamics. We propose the Neural Material Adaptor (NeuMA), which integrates existing physical laws with learned corrections, facilitating accurate learning of actual dynamics while maintaining the generalizability and interpretability of physical priors. Additionally, we propose Particle-GS, a particle-driven 3D Gaussian Splatting variant that bridges simulation and observed images, allowing back-propagate image gradients to optimize the simulator. Comprehensive experiments on various dynamics in terms of grounded particle accuracy, dynamic rendering quality, and generalization ability demonstrate that NeuMA can accurately capture intrinsic dynamics.
Lightning NeRF: Efficient Hybrid Scene Representation for Autonomous Driving
Mar 09, 2024



Recent studies have highlighted the promising application of NeRF in autonomous driving contexts. However, the complexity of outdoor environments, combined with the restricted viewpoints in driving scenarios, complicates the task of precisely reconstructing scene geometry. Such challenges often lead to diminished quality in reconstructions and extended durations for both training and rendering. To tackle these challenges, we present Lightning NeRF. It uses an efficient hybrid scene representation that effectively utilizes the geometry prior from LiDAR in autonomous driving scenarios. Lightning NeRF significantly improves the novel view synthesis performance of NeRF and reduces computational overheads. Through evaluations on real-world datasets, such as KITTI-360, Argoverse2, and our private dataset, we demonstrate that our approach not only exceeds the current state-of-the-art in novel view synthesis quality but also achieves a five-fold increase in training speed and a ten-fold improvement in rendering speed. Codes are available at https://github.com/VISION-SJTU/Lightning-NeRF .
Artificial Intelligence Security Competition (AISC)
Dec 07, 2022



The security of artificial intelligence (AI) is an important research area towards safe, reliable, and trustworthy AI systems. To accelerate the research on AI security, the Artificial Intelligence Security Competition (AISC) was organized by the Zhongguancun Laboratory, China Industrial Control Systems Cyber Emergency Response Team, Institute for Artificial Intelligence, Tsinghua University, and RealAI as part of the Zhongguancun International Frontier Technology Innovation Competition (https://www.zgc-aisc.com/en). The competition consists of three tracks, including Deepfake Security Competition, Autonomous Driving Security Competition, and Face Recognition Security Competition. This report will introduce the competition rules of these three tracks and the solutions of top-ranking teams in each track.