 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLLG: Dynamic Logit-Level Gating of LLM Experts
Jun 03, 2026Leveraging multiple specialized LLMs can combine complementary strengths, but existing approaches trade adaptability for stability: routing commits prematurely, heuristic ensembling depends on fragile proxies, and parameter merging introduces interference. We propose DLLG (Dynamic Logit-Level Gating), a dynamic logit-level ensembling framework that learns token-level expert fusion from sparse response-level supervision. A lightweight gating module predicts step-wise fusion weights, linking trajectory-level correctness to generation without token-level labels or expert retraining. Across diverse reasoning and code benchmarks, DLLG consistently outperforms strong routing, heuristic ensembling, and parameter-merging baselines across model scales, highlighting learned logit-level fusion as a robust and scalable paradigm for integrating specialized experts.
Exploring Cross-Scenario Generality of Agentic Memory Systems: Diagnostics and a Strong Baseline
Jun 03, 2026LLM agents accumulate histories that outgrow their context windows, motivating a growing literature on memory systems. Yet most existing designs are tuned to a single scenario (multi-session chat or a single trajectory format), and there is little evidence that they generalize across the heterogeneous trajectories agents encounter in deployment. We revisit eight memory systems plus an agentic harness for search problems, on five scenarios: single-turn QA, multi-session chat, agentic-trajectory QA, memory stress tests, and long-horizon agentic tasks. The harness, which self-manages flat text-file storage via tool calls, achieves the best cross-task ranking, suggesting that memory performance hinges on giving the agent active control over storage and retrieval rather than on a passive store behind a fixed pipeline. We instantiate this insight in AutoMEM, an agentic memory harness with a self-managed tool interface that achieves the best cross-scenario generality among the systems we evaluate.
OpenRFM: Dissecting Relational In-Context Learning
Jun 03, 2026Relational Foundation Models (RFMs) promise a single pre-trained predictor that, given any relational database, returns predictions in one forward pass via relational in-context learning (ICL). Yet a substantial gap separates open RFMs from their commercial counterparts, and the origin of this gap has not been systematically understood. We dissect a representative framework, the Relational Transformer (RT), from two perspectives. Model side: we show that RT performs relation-level ICL, and a kernel regression view shows it fails when sparse label-cell coverage yields an underdetermined regression. Data side: we ablate RT's pre-training source and find that existing synthetic-only pre-training and in-distribution pre-training drive the same architecture into different regimes, lazy vs. feature-learning. Probing this gap reveals that the missing ingredient is a support-identifiable relational latent in the label-generation process. These two diagnoses translate into (1) a dual-stage ICL architecture that combines the relational backbone with a batch-level ICL layer lifted from a pre-trained tabular foundation model to overcome relation-level label scarcity, and (2) a homophily-aware synthetic plus continual real-data pre-training mixture, augmented with a prototype-based regularization. These choices define OpenRFM, a simple yet effective RFM that improves average task performance by approximately 30% over the RT backbone and surpasses the commercial model KumoRFMv1 on a large set of evaluation tasks.
Do Proactive Agents Really Need an LLM to Decide When to Wake and What to Anchor?
May 28, 2026Proactive agents read user activity as text and call an LLM on every event to decide whether to act. But user activity is not natively text: it is a structured event stream of (actor, verb, object, timestamp) tuples that the operating system already maintains in graph form. Rendering the structure as text and asking an LLM to recover it is a round-trip the system never had to take. We treat the always-on signal as graph updates rather than text and use a small temporal-graph-learning (TGL) model as the encoder: one forward pass yields a per-event trigger probability and a per-entity routing score, and only the downstream agent (turning a small structured handoff into a fluent user-facing sentence) is an LLM call, invoked only when the trigger fires. TGL improves F1 on each of 14 backbones (mean +16.7, up to +46.0); in trigger-architecture comparisons, one TGL checkpoint gives the strongest trigger AUCs and the most stable deployed threshold. It runs at 11.13 ms per event on a GPU server and 13.99 ms on a consumer laptop, approximately 4--7x and 12--83x faster than every single-forward LLM-as-trigger configuration tested in each regime, with an approximately 220 MiB BF16 resident footprint deployable on-device alongside the privacy-sensitive activity stream it consumes.
Multi-Rollout On-Policy Distillation via Peer Successes and Failures
May 12, 2026Large language models are often post-trained with sparse verifier rewards, which indicate whether a sampled trajectory succeeds but provide limited guidance about where reasoning succeeds or fails. On-policy distillation (OPD) offers denser token-level supervision by training on student-generated trajectories, yet existing methods typically distill each rollout independently and ignore the other attempts sampled for the same prompt. We introduce Multi-Rollout On-Policy Distillation (MOPD), a peer-conditioned distillation framework that uses the student's local rollout group to construct more informative teacher signals. MOPD conditions the teacher on both successful and failed peer rollouts: successes provide positive evidence for valid reasoning patterns, while failures provide structured negative evidence about plausible mistakes to avoid. We study two peer-context constructions: positive peer imitation and contrastive success-failure conditioning. Experiments on competitive programming, mathematical reasoning, scientific question answering, and tool-use benchmarks show that MOPD consistently improves over standard on-policy baselines. Further teacher-signal analysis shows that mixed success-failure contexts better align teacher scores with verifier rewards, indicating that the gains arise from more faithful, instance-adaptive supervision. These results indicate that effective on-policy distillation should exploit the student's multi-rollout trial-and-error behavior rather than treating rollouts as isolated samples.
The Vision Wormhole: Latent-Space Communication in Heterogeneous Multi-Agent Systems
Feb 17, 2026Multi-Agent Systems (MAS) powered by Large Language Models have unlocked advanced collaborative reasoning, yet they remain shackled by the inefficiency of discrete text communication, which imposes significant runtime overhead and information quantization loss. While latent state transfer offers a high-bandwidth alternative, existing approaches either assume homogeneous sender-receiver architectures or rely on pair-specific learned translators, limiting scalability and modularity across diverse model families with disjoint manifolds. In this work, we propose the Vision Wormhole, a novel framework that repurposes the visual interface of Vision-Language Models (VLMs) to enable model-agnostic, text-free communication. By introducing a Universal Visual Codec, we map heterogeneous reasoning traces into a shared continuous latent space and inject them directly into the receiver's visual pathway, effectively treating the vision encoder as a universal port for inter-agent telepathy. Our framework adopts a hub-and-spoke topology to reduce pairwise alignment complexity from O(N^2) to O(N) and leverages a label-free, teacher-student distillation objective to align the high-speed visual channel with the robust reasoning patterns of the text pathway. Extensive experiments across heterogeneous model families (e.g., Qwen-VL, Gemma) demonstrate that the Vision Wormhole reduces end-to-end wall-clock time in controlled comparisons while maintaining reasoning fidelity comparable to standard text-based MAS. Code is available at https://github.com/xz-liu/heterogeneous-latent-mas
The Trojan in the Vocabulary: Stealthy Sabotage of LLM Composition
Dec 31, 2025The open-weight LLM ecosystem is increasingly defined by model composition techniques (such as weight merging, speculative decoding, and vocabulary expansion) that remix capabilities from diverse sources. A critical prerequisite for applying these methods across different model families is tokenizer transplant, which aligns incompatible vocabularies to a shared embedding space. We demonstrate that this essential interoperability step introduces a supply-chain vulnerability: we engineer a single "breaker token" that is functionally inert in a donor model yet reliably reconstructs into a high-salience malicious feature after transplant into a base model. By exploiting the geometry of coefficient reuse, our attack creates an asymmetric realizability gap that sabotages the base model's generation while leaving the donor's utility statistically indistinguishable from nominal behavior. We formalize this as a dual-objective optimization problem and instantiate the attack using a sparse solver. Empirically, the attack is training-free and achieves spectral mimicry to evade outlier detection, while demonstrating structural persistence against fine-tuning and weight merging, highlighting a hidden risk in the pipeline of modular AI composition. Code is available at https://github.com/xz-liu/tokenforge
SUV: Scalable Large Language Model Copyright Compliance with Regularized Selective Unlearning
Mar 29, 2025Large Language Models (LLMs) have transformed natural language processing by learning from massive datasets, yet this rapid progress has also drawn legal scrutiny, as the ability to unintentionally generate copyrighted content has already prompted several prominent lawsuits. In this work, we introduce SUV (Selective Unlearning for Verbatim data), a selective unlearning framework designed to prevent LLM from memorizing copyrighted content while preserving its overall utility. In detail, the proposed method constructs a dataset that captures instances of copyrighted infringement cases by the targeted LLM. With the dataset, we unlearn the content from the LLM by means of Direct Preference Optimization (DPO), which replaces the verbatim copyrighted content with plausible and coherent alternatives. Since DPO may hinder the LLM's performance in other unrelated tasks, we integrate gradient projection and Fisher information regularization to mitigate the degradation. We validate our approach using a large-scale dataset of 500 famous books (predominantly copyrighted works) and demonstrate that SUV significantly reduces verbatim memorization with negligible impact on the performance on unrelated tasks. Extensive experiments on both our dataset and public benchmarks confirm the scalability and efficacy of our approach, offering a promising solution for mitigating copyright risks in real-world LLM applications.
Improving Causal Reasoning in Large Language Models: A Survey
Oct 22, 2024



Causal reasoning (CR) is a crucial aspect of intelligence, essential for problem-solving, decision-making, and understanding the world. While large language models (LLMs) can generate rationales for their outputs, their ability to reliably perform causal reasoning remains uncertain, often falling short in tasks requiring a deep understanding of causality. In this survey, we provide a comprehensive review of research aimed at enhancing LLMs for causal reasoning. We categorize existing methods based on the role of LLMs: either as reasoning engines or as helpers providing knowledge or data to traditional CR methods, followed by a detailed discussion of the methodologies in each category. We then evaluate the performance of LLMs on various causal reasoning tasks, providing key findings and in-depth analysis. Finally, we provide insights from current studies and highlight promising directions for future research. We aim for this work to serve as a comprehensive resource, fostering further advancements in causal reasoning with LLMs. Resources are available at https://github.com/chendl02/Awesome-LLM-causal-reasoning.
On the Client Preference of LLM Fine-tuning in Federated Learning
Jul 03, 2024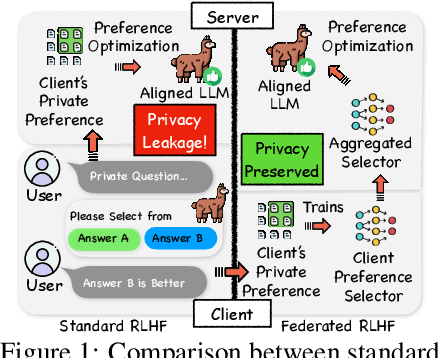
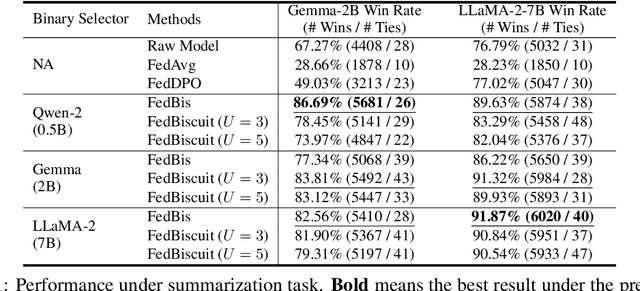
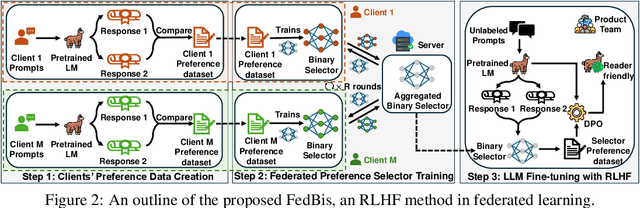
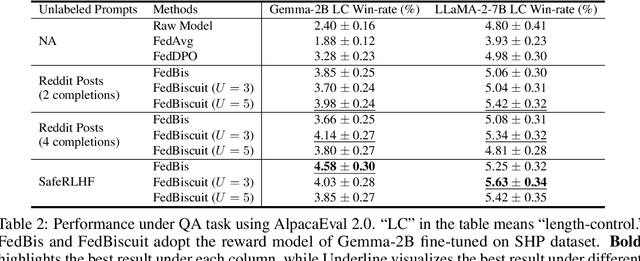
Reinforcement learning with human feedback (RLHF) fine-tunes a pretrained large language model (LLM) using preference datasets, enabling the LLM to generate outputs that align with human preferences. Given the sensitive nature of these preference datasets held by various clients, there is a need to implement RLHF within a federated learning (FL) framework, where clients are reluctant to share their data due to privacy concerns. To address this, we introduce a feasible framework in which clients collaboratively train a binary selector with their preference datasets using our proposed FedBis. With a well-trained selector, we can further enhance the LLM that generates human-preferred completions. Meanwhile, we propose a novel algorithm, FedBiscuit, that trains multiple selectors by organizing clients into balanced and disjoint clusters based on their preferences. Compared to the FedBis, FedBiscuit demonstrates superior performance in simulating human preferences for pairwise completions. Our extensive experiments on federated human preference datasets -- marking the first benchmark to address heterogeneous data partitioning among clients -- demonstrate that FedBiscuit outperforms FedBis and even surpasses traditional centralized training.