 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Memory Retrieval to Enhance LLM-based Generative Recommendation
Dec 23, 2024



Leveraging Large Language Models (LLMs) to harness user-item interaction histories for item generation has emerged as a promising paradigm in generative recommendation. However, the limited context window of LLMs often restricts them to focusing on recent user interactions only, leading to the neglect of long-term interests involved in the longer histories. To address this challenge, we propose a novel Automatic Memory-Retrieval framework (AutoMR), which is capable of storing long-term interests in the memory and extracting relevant information from it for next-item generation within LLMs. Extensive experimental results on two real-world datasets demonstrate the effectiveness of our proposed AutoMR framework in utilizing long-term interests for generative recommendation.
V$^2$-SfMLearner: Learning Monocular Depth and Ego-motion for Multimodal Wireless Capsule Endoscopy
Dec 23, 2024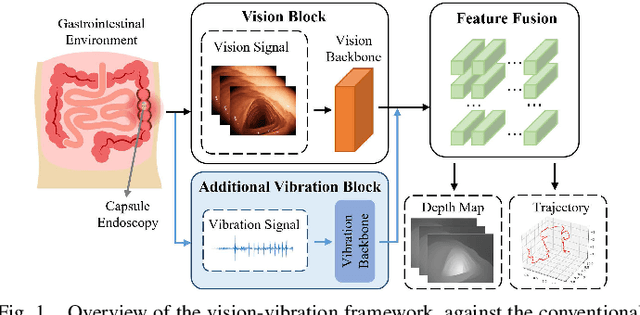
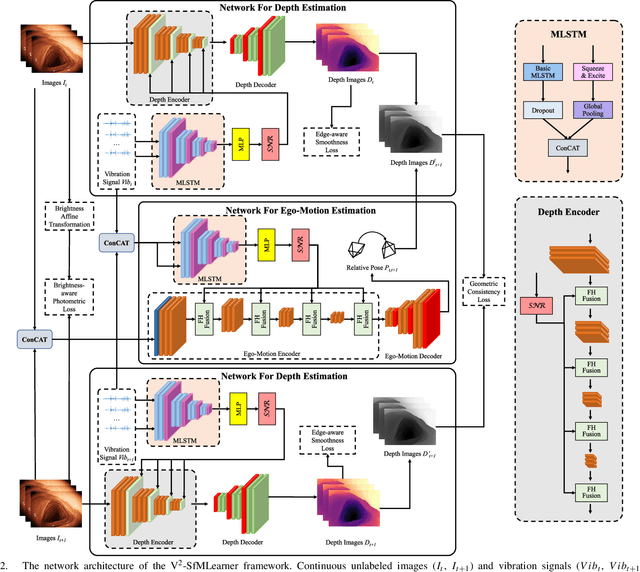
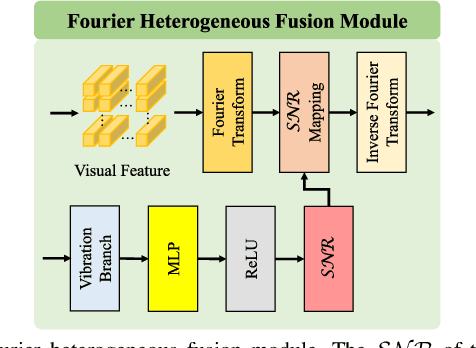
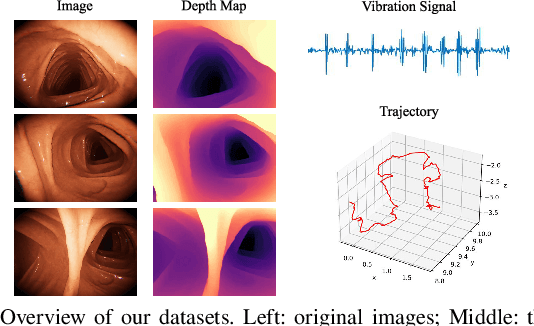
Deep learning can predict depth maps and capsule ego-motion from capsule endoscopy videos, aiding in 3D scene reconstruction and lesion localization. However, the collisions of the capsule endoscopies within the gastrointestinal tract cause vibration perturbations in the training data. Existing solutions focus solely on vision-based processing, neglecting other auxiliary signals like vibrations that could reduce noise and improve performance. Therefore, we propose V$^2$-SfMLearner, a multimodal approach integrating vibration signals into vision-based depth and capsule motion estimation for monocular capsule endoscopy. We construct a multimodal capsule endoscopy dataset containing vibration and visual signals, and our artificial intelligence solution develops an unsupervised method using vision-vibration signals, effectively eliminating vibration perturbations through multimodal learning. Specifically, we carefully design a vibration network branch and a Fourier fusion module, to detect and mitigate vibration noises. The fusion framework is compatible with popular vision-only algorithms. Extensive validation on the multimodal dataset demonstrates superior performance and robustness against vision-only algorithms. Without the need for large external equipment, our V$^2$-SfMLearner has the potential for integration into clinical capsule robots, providing real-time and dependable digestive examination tools. The findings show promise for practical implementation in clinical settings, enhancing the diagnostic capabilities of doctors.
Disentangling Reasoning Tokens and Boilerplate Tokens For Language Model Fine-tuning
Dec 19, 2024



When using agent-task datasets to enhance agent capabilities for Large Language Models (LLMs), current methodologies often treat all tokens within a sample equally. However, we argue that tokens serving different roles - specifically, reasoning tokens versus boilerplate tokens (e.g., those governing output format) - differ significantly in importance and learning complexity, necessitating their disentanglement and distinct treatment. To address this, we propose a novel Shuffle-Aware Discriminator (SHAD) for adaptive token discrimination. SHAD classifies tokens by exploiting predictability differences observed after shuffling input-output combinations across samples: boilerplate tokens, due to their repetitive nature among samples, maintain predictability, whereas reasoning tokens do not. Using SHAD, we propose the Reasoning-highlighted Fine-Tuning (RFT) method, which adaptively emphasizes reasoning tokens during fine-tuning, yielding notable performance gains over common Supervised Fine-Tuning (SFT).
SIDE: Socially Informed Drought Estimation Toward Understanding Societal Impact Dynamics of Environmental Crisis
Dec 17, 2024



Drought has become a critical global threat with significant societal impact. Existing drought monitoring solutions primarily focus on assessing drought severity using quantitative measurements, overlooking the diverse societal impact of drought from human-centric perspectives. Motivated by the collective intelligence on social media and the computational power of AI, this paper studies a novel problem of socially informed AI-driven drought estimation that aims to leverage social and news media information to jointly estimate drought severity and its societal impact. Two technical challenges exist: 1) How to model the implicit temporal dynamics of drought societal impact. 2) How to capture the social-physical interdependence between the physical drought condition and its societal impact. To address these challenges, we develop SIDE, a socially informed AI-driven drought estimation framework that explicitly quantifies the societal impact of drought and effectively models the social-physical interdependency for joint severity-impact estimation. Experiments on real-world datasets from California and Texas demonstrate SIDE's superior performance compared to state-of-the-art baselines in accurately estimating drought severity and its societal impact. SIDE offers valuable insights for developing human-centric drought mitigation strategies to foster sustainable and resilient communities.
Effortless Efficiency: Low-Cost Pruning of Diffusion Models
Dec 03, 2024Diffusion models have achieved impressive advancements in various vision tasks. However, these gains often rely on increasing model size, which escalates computational complexity and memory demands, complicating deployment, raising inference costs, and causing environmental impact. While some studies have explored pruning techniques to improve the memory efficiency of diffusion models, most existing methods require extensive retraining to retain the model performance. Retraining a modern large diffusion model is extremely costly and resource-intensive, which limits the practicality of these methods. In this work, we achieve low-cost diffusion pruning without retraining by proposing a model-agnostic structural pruning framework for diffusion models that learns a differentiable mask to sparsify the model. To ensure effective pruning that preserves the quality of the final denoised latent, we design a novel end-to-end pruning objective that spans the entire diffusion process. As end-to-end pruning is memory-intensive, we further propose time step gradient checkpointing, a technique that significantly reduces memory usage during optimization, enabling end-to-end pruning within a limited memory budget. Results on state-of-the-art U-Net diffusion models SDXL and diffusion transformers (FLUX) demonstrate that our method can effectively prune up to 20% parameters with minimal perceptible performance degradation, and notably, without the need for model retraining. We also showcase that our method can still prune on top of time step distilled diffusion models.
Precision Profile Pollution Attack on Sequential Recommenders via Influence Function
Dec 02, 2024



Sequential recommendation approaches have demonstrated remarkable proficiency in modeling user preferences. Nevertheless, they are susceptible to profile pollution attacks (PPA), wherein items are introduced into a user's interaction history deliberately to influence the recommendation list. Since retraining the model for each polluted item is time-consuming, recent PPAs estimate item influence based on gradient directions to identify the most effective attack candidates. However, the actual item representations diverge significantly from the gradients, resulting in disparate outcomes.To tackle this challenge, we introduce an INFluence Function-based Attack approach INFAttack that offers a more accurate estimation of the influence of polluting items. Specifically, we calculate the modifications to the original model using the influence function when generating polluted sequences by introducing specific items. Subsequently, we choose the sequence that has been most significantly influenced to substitute the original sequence, thus promoting the target item. Comprehensive experiments conducted on five real-world datasets illustrate that INFAttack surpasses all baseline methods and consistently delivers stable attack performance for both popular and unpopular items.
MolMetaLM: a Physicochemical Knowledge-Guided Molecular Meta Language Model
Nov 23, 2024Most current molecular language models transfer the masked language model or image-text generation model from natural language processing to molecular field. However, molecules are not solely characterized by atom/bond symbols; they encapsulate important physical/chemical properties. Moreover, normal language models bring grammar rules that are irrelevant for understanding molecules. In this study, we propose a novel physicochemical knowledge-guided molecular meta language framework MolMetaLM. We design a molecule-specialized meta language paradigm, formatted as multiple <S,P,O> (subject, predicate, object) knowledge triples sharing the same S (i.e., molecule) to enhance learning the semantic relationships between physicochemical knowledge and molecules. By introducing different molecular knowledge and noises, the meta language paradigm generates tens of thousands of pretraining tasks. By recovering the token/sequence/order-level noises, MolMetaLM exhibits proficiency in large-scale benchmark evaluations involving property prediction, molecule generation, conformation inference, and molecular optimization. Through MolMetaLM, we offer a new insight for designing language models.
Arm Robot: AR-Enhanced Embodied Control and Visualization for Intuitive Robot Arm Manipulation
Nov 21, 2024Embodied interaction has been introduced to human-robot interaction (HRI) as a type of teleoperation, in which users control robot arms with bodily action via handheld controllers or haptic gloves. Embodied teleoperation has made robot control intuitive to non-technical users, but differences between humans' and robots' capabilities \eg ranges of motion and response time, remain challenging. In response, we present Arm Robot, an embodied robot arm teleoperation system that helps users tackle human-robot discrepancies. Specifically, Arm Robot (1) includes AR visualization as real-time feedback on temporal and spatial discrepancies, and (2) allows users to change observing perspectives and expand action space. We conducted a user study (N=18) to investigate the usability of the Arm Robot and learn how users perceive the embodiment. Our results show users could use Arm Robot's features to effectively control the robot arm, providing insights for continued work in embodied HRI.
Leveraging MLLM Embeddings and Attribute Smoothing for Compositional Zero-Shot Learning
Nov 18, 2024Compositional zero-shot learning (CZSL) aims to recognize novel compositions of attributes and objects learned from seen compositions. Previous works disentangle attribute and object by extracting shared and exclusive parts between image pairs sharing the same attribute (object), as well as aligning them with pretrained word embeddings to improve unseen attribute-object recognition. Despite the significant achievements of existing efforts, they are hampered by three limitations: (1) the efficacy of disentanglement is compromised due to the influence of the background and the intricate entanglement of attribute with object in the same parts. (2) existing word embeddings fail to capture complex multimodal semantic information. (3) overconfidence exhibited by existing models in seen compositions hinders their generalization to novel compositions. Being aware of these, we propose a novel framework named Multimodal Large Language Model (MLLM) embeddings and attribute smoothing guided disentanglement (TRIDENT) for CZSL. First, we leverage feature adaptive aggregation modules to mitigate the impact of background, and utilize learnable condition masks to capture multigranularity features for disentanglement. Then, the last hidden states of MLLM are employed as word embeddings for their superior representation capabilities. Moreover, we propose attribute smoothing with auxiliary attributes generated by Large Language Model (LLM) for seen compositions, addressing the issue of overconfidence by encouraging the model to learn more attributes in one given composition. Extensive experiments demonstrate that TRIDENT achieves state-of-the-art performance on three benchmarks.
BioNeMo Framework: a modular, high-performance library for AI model development in drug discovery
Nov 15, 2024



Artificial Intelligence models encoding biology and chemistry are opening new routes to high-throughput and high-quality in-silico drug development. However, their training increasingly relies on computational scale, with recent protein language models (pLM) training on hundreds of graphical processing units (GPUs). We introduce the BioNeMo Framework to facilitate the training of computational biology and chemistry AI models across hundreds of GPUs. Its modular design allows the integration of individual components, such as data loaders, into existing workflows and is open to community contributions. We detail technical features of the BioNeMo Framework through use cases such as pLM pre-training and fine-tuning. On 256 NVIDIA A100s, BioNeMo Framework trains a three billion parameter BERT-based pLM on over one trillion tokens in 4.2 days. The BioNeMo Framework is open-source and free for everyone to use.