 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix-3D: Omnidirectional Explorable 3D World Generation
Aug 11, 2025Explorable 3D world generation from a single image or text prompt forms a cornerstone of spatial intelligence. Recent works utilize video model to achieve wide-scope and generalizable 3D world generation. However, existing approaches often suffer from a limited scope in the generated scenes. In this work, we propose Matrix-3D, a framework that utilize panoramic representation for wide-coverage omnidirectional explorable 3D world generation that combines conditional video generation and panoramic 3D reconstruction. We first train a trajectory-guided panoramic video diffusion model that employs scene mesh renders as condition, to enable high-quality and geometrically consistent scene video generation. To lift the panorama scene video to 3D world, we propose two separate methods: (1) a feed-forward large panorama reconstruction model for rapid 3D scene reconstruction and (2) an optimization-based pipeline for accurate and detailed 3D scene reconstruction. To facilitate effective training, we also introduce the Matrix-Pano dataset, the first large-scale synthetic collection comprising 116K high-quality static panoramic video sequences with depth and trajectory annotations. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance in panoramic video generation and 3D world generation. See more in https://matrix-3d.github.io.
AR-VRM: Imitating Human Motions for Visual Robot Manipulation with Analogical Reasoning
Aug 11, 2025Visual Robot Manipulation (VRM) aims to enable a robot to follow natural language instructions based on robot states and visual observations, and therefore requires costly multi-modal data. To compensate for the deficiency of robot data, existing approaches have employed vision-language pretraining with large-scale data. However, they either utilize web data that differs from robotic tasks, or train the model in an implicit way (e.g., predicting future frames at the pixel level), thus showing limited generalization ability under insufficient robot data. In this paper, we propose to learn from large-scale human action video datasets in an explicit way (i.e., imitating human actions from hand keypoints), introducing Visual Robot Manipulation with Analogical Reasoning (AR-VRM). To acquire action knowledge explicitly from human action videos, we propose a keypoint Vision-Language Model (VLM) pretraining scheme, enabling the VLM to learn human action knowledge and directly predict human hand keypoints. During fine-tuning on robot data, to facilitate the robotic arm in imitating the action patterns of human motions, we first retrieve human action videos that perform similar manipulation tasks and have similar historical observations , and then learn the Analogical Reasoning (AR) map between human hand keypoints and robot components. Taking advantage of focusing on action keypoints instead of irrelevant visual cues, our method achieves leading performance on the CALVIN benchmark {and real-world experiments}. In few-shot scenarios, our AR-VRM outperforms previous methods by large margins , underscoring the effectiveness of explicitly imitating human actions under data scarcity.
eMotions: A Large-Scale Dataset and Audio-Visual Fusion Network for Emotion Analysis in Short-form Videos
Aug 09, 2025Short-form videos (SVs) have become a vital part of our online routine for acquiring and sharing information. Their multimodal complexity poses new challenges for video analysis, highlighting the need for video emotion analysis (VEA) within the community. Given the limited availability of SVs emotion data, we introduce eMotions, a large-scale dataset consisting of 27,996 videos with full-scale annotations. To ensure quality and reduce subjective bias, we emphasize better personnel allocation and propose a multi-stage annotation procedure. Additionally, we provide the category-balanced and test-oriented variants through targeted sampling to meet diverse needs. While there have been significant studies on videos with clear emotional cues (e.g., facial expressions), analyzing emotions in SVs remains a challenging task. The challenge arises from the broader content diversity, which introduces more distinct semantic gaps and complicates the representations learning of emotion-related features. Furthermore, the prevalence of audio-visual co-expressions in SVs leads to the local biases and collective information gaps caused by the inconsistencies in emotional expressions. To tackle this, we propose AV-CANet, an end-to-end audio-visual fusion network that leverages video transformer to capture semantically relevant representations. We further introduce the Local-Global Fusion Module designed to progressively capture the correlations of audio-visual features. Besides, EP-CE Loss is constructed to globally steer optimizations with tripolar penalties. Extensive experiments across three eMotions-related datasets and four public VEA datasets demonstrate the effectiveness of our proposed AV-CANet, while providing broad insights for future research. Moreover, we conduct ablation studies to examine the critical components of our method. Dataset and code will be made available at Github.
When Prompt Engineering Meets Software Engineering: CNL-P as Natural and Robust "APIs'' for Human-AI Interaction
Aug 09, 2025With the growing capabilities of large language models (LLMs), they are increasingly applied in areas like intelligent customer service, code generation, and knowledge management. Natural language (NL) prompts act as the ``APIs'' for human-LLM interaction. To improve prompt quality, best practices for prompt engineering (PE) have been developed, including writing guidelines and templates. Building on this, we propose Controlled NL for Prompt (CNL-P), which not only incorporates PE best practices but also draws on key principles from software engineering (SE). CNL-P introduces precise grammar structures and strict semantic norms, further eliminating NL's ambiguity, allowing for a declarative but structured and accurate expression of user intent. This helps LLMs better interpret and execute the prompts, leading to more consistent and higher-quality outputs. We also introduce an NL2CNL-P conversion tool based on LLMs, enabling users to write prompts in NL, which are then transformed into CNL-P format, thus lowering the learning curve of CNL-P. In particular, we develop a linting tool that checks CNL-P prompts for syntactic and semantic accuracy, applying static analysis techniques to NL for the first time. Extensive experiments demonstrate that CNL-P enhances the quality of LLM responses through the novel and organic synergy of PE and SE. We believe that CNL-P can bridge the gap between emerging PE and traditional SE, laying the foundation for a new programming paradigm centered around NL.
UR$^2$: Unify RAG and Reasoning through Reinforcement Learning
Aug 08, 2025Large Language Models (LLMs) have shown remarkable capabilities through two complementary paradigms: Retrieval-Augmented Generation (RAG), which enhances knowledge grounding, and Reinforcement Learning from Verifiable Rewards (RLVR), which optimizes complex reasoning abilities. However, these two capabilities are often developed in isolation, and existing efforts to unify them remain narrow in scope-typically limited to open-domain QA with fixed retrieval settings and task-specific assumptions. This lack of integration constrains generalization and limits the applicability of RAG-RL methods to broader domains. To bridge this gap, we propose UR2 (Unified RAG and Reasoning), a general framework that unifies retrieval and reasoning through reinforcement learning. UR2 introduces two key contributions: a difficulty-aware curriculum training that selectively invokes retrieval only for challenging problems, and a hybrid knowledge access strategy combining domain-specific offline corpora with LLM-generated summaries. These components are designed to enable dynamic coordination between retrieval and reasoning, improving adaptability across a diverse range of tasks. Experiments across open-domain QA, MMLU-Pro, medical, and mathematical reasoning tasks demonstrate that UR2 (built on Qwen2.5-3/7B and LLaMA-3.1-8B) significantly outperforms existing RAG and RL methods, achieving comparable performance to GPT-4o-mini and GPT-4.1-mini on several benchmarks. We have released all code, models, and data at https://github.com/Tsinghua-dhy/UR2.
Learning to See and Act: Task-Aware View Planning for Robotic Manipulation
Aug 07, 2025Recent vision-language-action (VLA) models for multi-task robotic manipulation commonly rely on static viewpoints and shared visual encoders, which limit 3D perception and cause task interference, hindering robustness and generalization. In this work, we propose Task-Aware View Planning (TAVP), a framework designed to overcome these challenges by integrating active view planning with task-specific representation learning. TAVP employs an efficient exploration policy, accelerated by a novel pseudo-environment, to actively acquire informative views. Furthermore, we introduce a Mixture-of-Experts (MoE) visual encoder to disentangle features across different tasks, boosting both representation fidelity and task generalization. By learning to see the world in a task-aware way, TAVP generates more complete and discriminative visual representations, demonstrating significantly enhanced action prediction across a wide array of manipulation challenges. Extensive experiments on RLBench tasks show that our proposed TAVP model achieves superior performance over state-of-the-art fixed-view approaches. Visual results and code are provided at: https://hcplab-sysu.github.io/TAVP.
PhysPatch: A Physically Realizable and Transferable Adversarial Patch Attack for Multimodal Large Language Models-based Autonomous Driving Systems
Aug 07, 2025

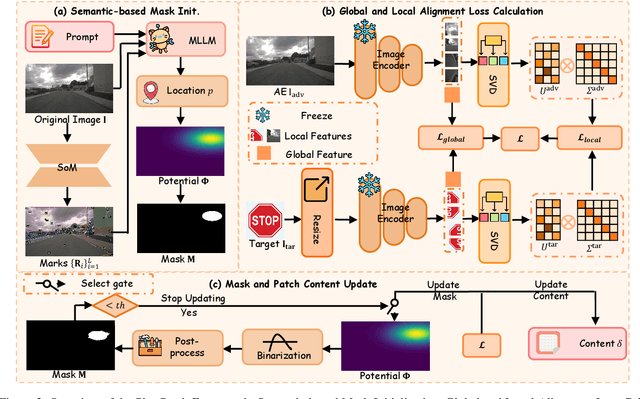

Multimodal Large Language Models (MLLMs) are becoming integral to autonomous driving (AD) systems due to their strong vision-language reasoning capabilities. However, MLLMs are vulnerable to adversarial attacks, particularly adversarial patch attacks, which can pose serious threats in real-world scenarios. Existing patch-based attack methods are primarily designed for object detection models and perform poorly when transferred to MLLM-based systems due to the latter's complex architectures and reasoning abilities. To address these limitations, we propose PhysPatch, a physically realizable and transferable adversarial patch framework tailored for MLLM-based AD systems. PhysPatch jointly optimizes patch location, shape, and content to enhance attack effectiveness and real-world applicability. It introduces a semantic-based mask initialization strategy for realistic placement, an SVD-based local alignment loss with patch-guided crop-resize to improve transferability, and a potential field-based mask refinement method. Extensive experiments across open-source, commercial, and reasoning-capable MLLMs demonstrate that PhysPatch significantly outperforms prior methods in steering MLLM-based AD systems toward target-aligned perception and planning outputs. Moreover, PhysPatch consistently places adversarial patches in physically feasible regions of AD scenes, ensuring strong real-world applicability and deployability.
FinMMR: Make Financial Numerical Reasoning More Multimodal, Comprehensive, and Challenging
Aug 06, 2025We present FinMMR, a novel bilingual multimodal benchmark tailored to evaluate the reasoning capabilities of multimodal large language models (MLLMs) in financial numerical reasoning tasks. Compared to existing benchmarks, our work introduces three significant advancements. (1) Multimodality: We meticulously transform existing financial reasoning benchmarks, and construct novel questions from the latest Chinese financial research reports. FinMMR comprises 4.3K questions and 8.7K images spanning 14 categories, including tables, bar charts, and ownership structure charts. (2) Comprehensiveness: FinMMR encompasses 14 financial subdomains, including corporate finance, banking, and industry analysis, significantly exceeding existing benchmarks in financial domain knowledge breadth. (3) Challenge: Models are required to perform multi-step precise numerical reasoning by integrating financial knowledge with the understanding of complex financial images and text. The best-performing MLLM achieves only 53.0% accuracy on Hard problems. We believe that FinMMR will drive advancements in enhancing the reasoning capabilities of MLLMs in real-world scenarios.
ICM-Fusion: In-Context Meta-Optimized LoRA Fusion for Multi-Task Adaptation
Aug 06, 2025



Enabling multi-task adaptation in pre-trained Low-Rank Adaptation (LoRA) models is crucial for enhancing their generalization capabilities. Most existing pre-trained LoRA fusion methods decompose weight matrices, sharing similar parameters while merging divergent ones. However, this paradigm inevitably induces inter-weight conflicts and leads to catastrophic domain forgetting. While incremental learning enables adaptation to multiple tasks, it struggles to achieve generalization in few-shot scenarios. Consequently, when the weight data follows a long-tailed distribution, it can lead to forgetting in the fused weights. To address this issue, we propose In-Context Meta LoRA Fusion (ICM-Fusion), a novel framework that synergizes meta-learning with in-context adaptation. The key innovation lies in our task vector arithmetic, which dynamically balances conflicting optimization directions across domains through learned manifold projections. ICM-Fusion obtains the optimal task vector orientation for the fused model in the latent space by adjusting the orientation of the task vectors. Subsequently, the fused LoRA is reconstructed by a self-designed Fusion VAE (F-VAE) to realize multi-task LoRA generation. We have conducted extensive experiments on visual and linguistic tasks, and the experimental results demonstrate that ICM-Fusion can be adapted to a wide range of architectural models and applied to various tasks. Compared to the current pre-trained LoRA fusion method, ICM-Fusion fused LoRA can significantly reduce the multi-tasking loss and can even achieve task enhancement in few-shot scenarios.
Unveiling Over-Memorization in Finetuning LLMs for Reasoning Tasks
Aug 06, 2025



The pretrained large language models (LLMs) are finetuned with labeled data for better instruction following ability and alignment with human values. In this paper, we study the learning dynamics of LLM finetuning on reasoning tasks and reveal the uncovered over-memorization phenomenon during a specific stage of LLM finetuning. At this stage, the LLMs have excessively memorized training data and exhibit high test perplexity while maintaining good test accuracy. We investigate the conditions that lead to LLM over-memorization and find that training epochs and large learning rates contribute to this issue. Although models with over-memorization demonstrate comparable test accuracy to normal models, they suffer from reduced robustness, poor out-of-distribution generalization, and decreased generation diversity. Our experiments unveil the over-memorization to be broadly applicable across different tasks, models, and finetuning methods. Our research highlights that overparameterized, extensively finetuned LLMs exhibit unique learning dynamics distinct from traditional machine learning models. Based on our observations of over-memorization, we provide recommendations on checkpoint and learning rate selection during finetuning.