 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Mathematical Reasoning Adaptive
Oct 06, 2025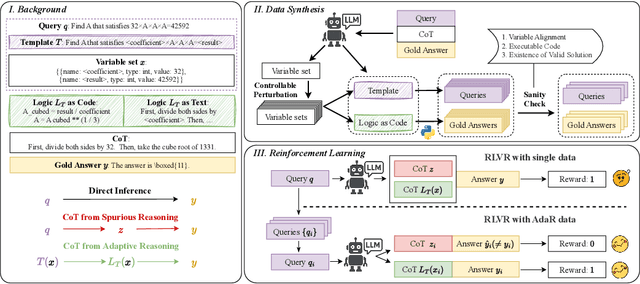
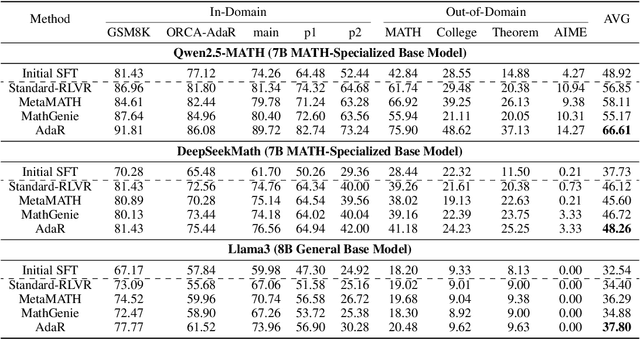


Mathematical reasoning is a primary indicator of large language models (LLMs) intelligence. However, existing LLMs exhibit failures of robustness and generalization. This paper attributes these deficiencies to spurious reasoning, i.e., producing answers from superficial features. To address this challenge, we propose the AdaR framework to enable adaptive reasoning, wherein models rely on problem-solving logic to produce answers. AdaR synthesizes logically equivalent queries by varying variable values, and trains models with RLVR on these data to penalize spurious logic while encouraging adaptive logic. To improve data quality, we extract the problem-solving logic from the original query and generate the corresponding answer by code execution, then apply a sanity check. Experimental results demonstrate that AdaR improves robustness and generalization, achieving substantial improvement in mathematical reasoning while maintaining high data efficiency. Analysis indicates that data synthesis and RLVR function in a coordinated manner to enable adaptive reasoning in LLMs. Subsequent analyses derive key design insights into the effect of critical factors and the applicability to instruct LLMs. Our project is available at https://github.com/LaiZhejian/AdaR
Fre-CW: Targeted Attack on Time Series Forecasting using Frequency Domain Loss
Aug 12, 2025Transformer-based models have made significant progress in time series forecasting. However, a key limitation of deep learning models is their susceptibility to adversarial attacks, which has not been studied enough in the context of time series prediction. In contrast to areas such as computer vision, where adversarial robustness has been extensively studied, frequency domain features of time series data play an important role in the prediction task but have not been sufficiently explored in terms of adversarial attacks. This paper proposes a time series prediction attack algorithm based on frequency domain loss. Specifically, we adapt an attack method originally designed for classification tasks to the prediction field and optimize the adversarial samples using both time-domain and frequency-domain losses. To the best of our knowledge, there is no relevant research on using frequency information for time-series adversarial attacks. Our experimental results show that these current time series prediction models are vulnerable to adversarial attacks, and our approach achieves excellent performance on major time series forecasting datasets.
Improving Generative Ad Text on Facebook using Reinforcement Learning
Jul 29, 2025Generative artificial intelligence (AI), in particular large language models (LLMs), is poised to drive transformative economic change. LLMs are pre-trained on vast text data to learn general language patterns, but a subsequent post-training phase is critical to align them for specific real-world tasks. Reinforcement learning (RL) is the leading post-training technique, yet its economic impact remains largely underexplored and unquantified. We examine this question through the lens of the first deployment of an RL-trained LLM for generative advertising on Facebook. Integrated into Meta's Text Generation feature, our model, "AdLlama," powers an AI tool that helps advertisers create new variations of human-written ad text. To train this model, we introduce reinforcement learning with performance feedback (RLPF), a post-training method that uses historical ad performance data as a reward signal. In a large-scale 10-week A/B test on Facebook spanning nearly 35,000 advertisers and 640,000 ad variations, we find that AdLlama improves click-through rates by 6.7% (p=0.0296) compared to a supervised imitation model trained on curated ads. This represents a substantial improvement in advertiser return on investment on Facebook. We also find that advertisers who used AdLlama generated more ad variations, indicating higher satisfaction with the model's outputs. To our knowledge, this is the largest study to date on the use of generative AI in an ecologically valid setting, offering an important data point quantifying the tangible impact of RL post-training. Furthermore, the results show that RLPF is a promising and generalizable approach for metric-driven post-training that bridges the gap between highly capable language models and tangible outcomes.
RoboSwap: A GAN-driven Video Diffusion Framework For Unsupervised Robot Arm Swapping
Jun 10, 2025Recent advancements in generative models have revolutionized video synthesis and editing. However, the scarcity of diverse, high-quality datasets continues to hinder video-conditioned robotic learning, limiting cross-platform generalization. In this work, we address the challenge of swapping a robotic arm in one video with another: a key step for crossembodiment learning. Unlike previous methods that depend on paired video demonstrations in the same environmental settings, our proposed framework, RoboSwap, operates on unpaired data from diverse environments, alleviating the data collection needs. RoboSwap introduces a novel video editing pipeline integrating both GANs and diffusion models, combining their isolated advantages. Specifically, we segment robotic arms from their backgrounds and train an unpaired GAN model to translate one robotic arm to another. The translated arm is blended with the original video background and refined with a diffusion model to enhance coherence, motion realism and object interaction. The GAN and diffusion stages are trained independently. Our experiments demonstrate that RoboSwap outperforms state-of-the-art video and image editing models on three benchmarks in terms of both structural coherence and motion consistency, thereby offering a robust solution for generating reliable, cross-embodiment data in robotic learning.
Multi-task Learning for Heterogeneous Data via Integrating Shared and Task-Specific Encodings
May 30, 2025Multi-task learning (MTL) has become an essential machine learning tool for addressing multiple learning tasks simultaneously and has been effectively applied across fields such as healthcare, marketing, and biomedical research. However, to enable efficient information sharing across tasks, it is crucial to leverage both shared and heterogeneous information. Despite extensive research on MTL, various forms of heterogeneity, including distribution and posterior heterogeneity, present significant challenges. Existing methods often fail to address these forms of heterogeneity within a unified framework. In this paper, we propose a dual-encoder framework to construct a heterogeneous latent factor space for each task, incorporating a task-shared encoder to capture common information across tasks and a task-specific encoder to preserve unique task characteristics. Additionally, we explore the intrinsic similarity structure of the coefficients corresponding to learned latent factors, allowing for adaptive integration across tasks to manage posterior heterogeneity. We introduce a unified algorithm that alternately learns the task-specific and task-shared encoders and coefficients. In theory, we investigate the excess risk bound for the proposed MTL method using local Rademacher complexity and apply it to a new but related task. Through simulation studies, we demonstrate that the proposed method outperforms existing data integration methods across various settings. Furthermore, the proposed method achieves superior predictive performance for time to tumor doubling across five distinct cancer types in PDX data.
Multi-task Learning for Heterogeneous Multi-source Block-Wise Missing Data
May 30, 2025Multi-task learning (MTL) has emerged as an imperative machine learning tool to solve multiple learning tasks simultaneously and has been successfully applied to healthcare, marketing, and biomedical fields. However, in order to borrow information across different tasks effectively, it is essential to utilize both homogeneous and heterogeneous information. Among the extensive literature on MTL, various forms of heterogeneity are presented in MTL problems, such as block-wise, distribution, and posterior heterogeneity. Existing methods, however, struggle to tackle these forms of heterogeneity simultaneously in a unified framework. In this paper, we propose a two-step learning strategy for MTL which addresses the aforementioned heterogeneity. First, we impute the missing blocks using shared representations extracted from homogeneous source across different tasks. Next, we disentangle the mappings between input features and responses into a shared component and a task-specific component, respectively, thereby enabling information borrowing through the shared component. Our numerical experiments and real-data analysis from the ADNI database demonstrate the superior MTL performance of the proposed method compared to other competing methods.
An integrated language-vision foundation model for conversational diagnostics and triaging in primary eye care
May 13, 2025Current deep learning models are mostly task specific and lack a user-friendly interface to operate. We present Meta-EyeFM, a multi-function foundation model that integrates a large language model (LLM) with vision foundation models (VFMs) for ocular disease assessment. Meta-EyeFM leverages a routing mechanism to enable accurate task-specific analysis based on text queries. Using Low Rank Adaptation, we fine-tuned our VFMs to detect ocular and systemic diseases, differentiate ocular disease severity, and identify common ocular signs. The model achieved 100% accuracy in routing fundus images to appropriate VFMs, which achieved $\ge$ 82.2% accuracy in disease detection, $\ge$ 89% in severity differentiation, $\ge$ 76% in sign identification. Meta-EyeFM was 11% to 43% more accurate than Gemini-1.5-flash and ChatGPT-4o LMMs in detecting various eye diseases and comparable to an ophthalmologist. This system offers enhanced usability and diagnostic performance, making it a valuable decision support tool for primary eye care or an online LLM for fundus evaluation.
DiffPattern-Flex: Efficient Layout Pattern Generation via Discrete Diffusion
May 07, 2025Recent advancements in layout pattern generation have been dominated by deep generative models. However, relying solely on neural networks for legality guarantees raises concerns in many practical applications. In this paper, we present \tool{DiffPattern}-Flex, a novel approach designed to generate reliable layout patterns efficiently. \tool{DiffPattern}-Flex incorporates a new method for generating diverse topologies using a discrete diffusion model while maintaining a lossless and compute-efficient layout representation. To ensure legal pattern generation, we employ {an} optimization-based, white-box pattern assessment process based on specific design rules. Furthermore, fast sampling and efficient legalization technologies are employed to accelerate the generation process. Experimental results across various benchmarks demonstrate that \tool{DiffPattern}-Flex significantly outperforms existing methods and excels at producing reliable layout patterns.
Proximal Inference on Population Intervention Indirect Effect
Apr 16, 2025



The population intervention indirect effect (PIIE) is a novel mediation effect representing the indirect component of the population intervention effect. Unlike traditional mediation measures, such as the natural indirect effect, the PIIE holds particular relevance in observational studies involving unethical exposures, when hypothetical interventions that impose harmful exposures are inappropriate. Although prior research has identified PIIE under unmeasured confounders between exposure and outcome, it has not fully addressed the confounding that affects the mediator. This study extends the PIIE identification to settings where unmeasured confounders influence exposure-outcome, exposure-mediator, and mediator-outcome relationships. Specifically, we leverage observed covariates as proxy variables for unmeasured confounders, constructing three proximal identification frameworks. Additionally, we characterize the semiparametric efficiency bound and develop multiply robust and locally efficient estimators. To handle high-dimensional nuisance parameters, we propose a debiased machine learning approach that achieves $\sqrt{n}$-consistency and asymptotic normality to estimate the true PIIE values, even when the machine learning estimators for the nuisance functions do not converge at $\sqrt{n}$-rate. In simulations, our estimators demonstrate higher confidence interval coverage rates than conventional methods across various model misspecifications. In a real data application, our approaches reveal an indirect effect of alcohol consumption on depression risk mediated by depersonalization symptoms.
Spatial Audio Processing with Large Language Model on Wearable Devices
Apr 11, 2025Integrating spatial context into large language models (LLMs) has the potential to revolutionize human-computer interaction, particularly in wearable devices. In this work, we present a novel system architecture that incorporates spatial speech understanding into LLMs, enabling contextually aware and adaptive applications for wearable technologies. Our approach leverages microstructure-based spatial sensing to extract precise Direction of Arrival (DoA) information using a monaural microphone. To address the lack of existing dataset for microstructure-assisted speech recordings, we synthetically create a dataset called OmniTalk by using the LibriSpeech dataset. This spatial information is fused with linguistic embeddings from OpenAI's Whisper model, allowing each modality to learn complementary contextual representations. The fused embeddings are aligned with the input space of LLaMA-3.2 3B model and fine-tuned with lightweight adaptation technique LoRA to optimize for on-device processing. SING supports spatially-aware automatic speech recognition (ASR), achieving a mean error of $25.72^\circ$-a substantial improvement compared to the 88.52$^\circ$ median error in existing work-with a word error rate (WER) of 5.3. SING also supports soundscaping, for example, inference how many people were talking and their directions, with up to 5 people and a median DoA error of 16$^\circ$. Our system demonstrates superior performance in spatial speech understanding while addressing the challenges of power efficiency, privacy, and hardware constraints, paving the way for advanced applications in augmented reality, accessibility, and immersive experiences.