 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyn-D$^2$P: Dynamic Differentially Private Decentralized Learning with Provable Utility Guarantee
May 10, 2025Most existing decentralized learning methods with differential privacy (DP) guarantee rely on constant gradient clipping bounds and fixed-level DP Gaussian noises for each node throughout the training process, leading to a significant accuracy degradation compared to non-private counterparts. In this paper, we propose a new Dynamic Differentially Private Decentralized learning approach (termed Dyn-D$^2$P) tailored for general time-varying directed networks. Leveraging the Gaussian DP (GDP) framework for privacy accounting, Dyn-D$^2$P dynamically adjusts gradient clipping bounds and noise levels based on gradient convergence. This proposed dynamic noise strategy enables us to enhance model accuracy while preserving the total privacy budget. Extensive experiments on benchmark datasets demonstrate the superiority of Dyn-D$^2$P over its counterparts employing fixed-level noises, especially under strong privacy guarantees. Furthermore, we provide a provable utility bound for Dyn-D$^2$P that establishes an explicit dependency on network-related parameters, with a scaling factor of $1/\sqrt{n}$ in terms of the number of nodes $n$ up to a bias error term induced by gradient clipping. To our knowledge, this is the first model utility analysis for differentially private decentralized non-convex optimization with dynamic gradient clipping bounds and noise levels.
Orthogonal Factor-Based Biclustering Algorithm (BCBOF) for High-Dimensional Data and Its Application in Stock Trend Prediction
Apr 30, 2025Biclustering is an effective technique in data mining and pattern recognition. Biclustering algorithms based on traditional clustering face two fundamental limitations when processing high-dimensional data: (1) The distance concentration phenomenon in high-dimensional spaces leads to data sparsity, rendering similarity measures ineffective; (2) Mainstream linear dimensionality reduction methods disrupt critical local structural patterns. To apply biclustering to high-dimensional datasets, we propose an orthogonal factor-based biclustering algorithm (BCBOF). First, we constructed orthogonal factors in the vector space of the high-dimensional dataset. Then, we performed clustering using the coordinates of the original data in the orthogonal subspace as clustering targets. Finally, we obtained biclustering results of the original dataset. Since dimensionality reduction was applied before clustering, the proposed algorithm effectively mitigated the data sparsity problem caused by high dimensionality. Additionally, we applied this biclustering algorithm to stock technical indicator combinations and stock price trend prediction. Biclustering results were transformed into fuzzy rules, and we incorporated profit-preserving and stop-loss rules into the rule set, ultimately forming a fuzzy inference system for stock price trend predictions and trading signals. To evaluate the performance of BCBOF, we compared it with existing biclustering methods using multiple evaluation metrics. The results showed that our algorithm outperformed other biclustering techniques. To validate the effectiveness of the fuzzy inference system, we conducted virtual trading experiments using historical data from 10 A-share stocks. The experimental results showed that the generated trading strategies yielded higher returns for investors.
FlowDistill: Scalable Traffic Flow Prediction via Distillation from LLMs
Apr 02, 2025Accurate traffic flow prediction is vital for optimizing urban mobility, yet it remains difficult in many cities due to complex spatio-temporal dependencies and limited high-quality data. While deep graph-based models demonstrate strong predictive power, their performance often comes at the cost of high computational overhead and substantial training data requirements, making them impractical for deployment in resource-constrained or data-scarce environments. We propose the FlowDistill, a lightweight and scalable traffic prediction framework based on knowledge distillation from large language models (LLMs). In this teacher-student setup, a fine-tuned LLM guides a compact multi-layer perceptron (MLP) student model using a novel combination of the information bottleneck principle and teacher-bounded regression loss, ensuring the distilled model retains only essential and transferable knowledge. Spatial and temporal correlations are explicitly encoded to enhance the model's generalization across diverse urban settings. Despite its simplicity, FlowDistill consistently outperforms state-of-the-art models in prediction accuracy while requiring significantly less training data, and achieving lower memory usage and inference latency, highlighting its efficiency and suitability for real-world, scalable deployment.
Poly-FEVER: A Multilingual Fact Verification Benchmark for Hallucination Detection in Large Language Models
Mar 19, 2025Hallucinations in generative AI, particularly in Large Language Models (LLMs), pose a significant challenge to the reliability of multilingual applications. Existing benchmarks for hallucination detection focus primarily on English and a few widely spoken languages, lacking the breadth to assess inconsistencies in model performance across diverse linguistic contexts. To address this gap, we introduce Poly-FEVER, a large-scale multilingual fact verification benchmark specifically designed for evaluating hallucination detection in LLMs. Poly-FEVER comprises 77,973 labeled factual claims spanning 11 languages, sourced from FEVER, Climate-FEVER, and SciFact. It provides the first large-scale dataset tailored for analyzing hallucination patterns across languages, enabling systematic evaluation of LLMs such as ChatGPT and the LLaMA series. Our analysis reveals how topic distribution and web resource availability influence hallucination frequency, uncovering language-specific biases that impact model accuracy. By offering a multilingual benchmark for fact verification, Poly-FEVER facilitates cross-linguistic comparisons of hallucination detection and contributes to the development of more reliable, language-inclusive AI systems. The dataset is publicly available to advance research in responsible AI, fact-checking methodologies, and multilingual NLP, promoting greater transparency and robustness in LLM performance. The proposed Poly-FEVER is available at: https://huggingface.co/datasets/HanzhiZhang/Poly-FEVER.
Aligning Multimodal LLM with Human Preference: A Survey
Mar 18, 2025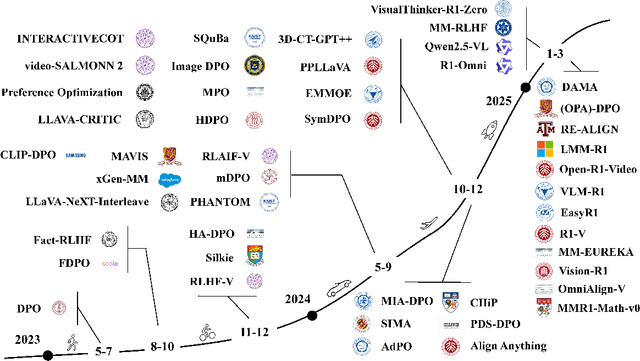
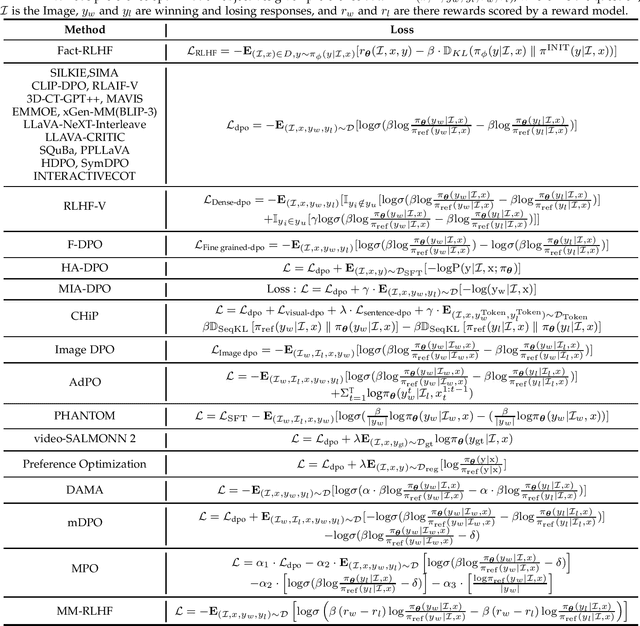
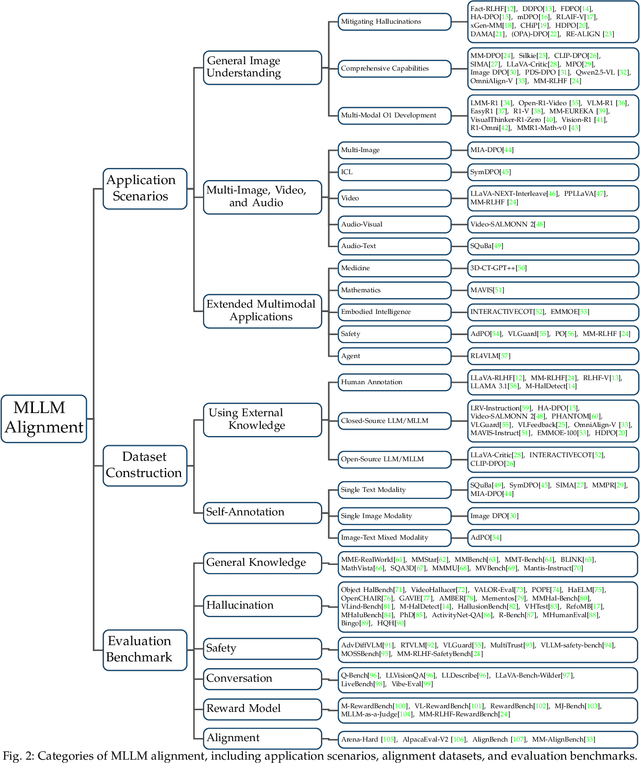

Large language models (LLMs) can handle a wide variety of general tasks with simple prompts, without the need for task-specific training. Multimodal Large Language Models (MLLMs), built upon LLMs, have demonstrated impressive potential in tackling complex tasks involving visual, auditory, and textual data. However, critical issues related to truthfulness, safety, o1-like reasoning, and alignment with human preference remain insufficiently addressed. This gap has spurred the emergence of various alignment algorithms, each targeting different application scenarios and optimization goals. Recent studies have shown that alignment algorithms are a powerful approach to resolving the aforementioned challenges. In this paper, we aim to provide a comprehensive and systematic review of alignment algorithms for MLLMs. Specifically, we explore four key aspects: (1) the application scenarios covered by alignment algorithms, including general image understanding, multi-image, video, and audio, and extended multimodal applications; (2) the core factors in constructing alignment datasets, including data sources, model responses, and preference annotations; (3) the benchmarks used to evaluate alignment algorithms; and (4) a discussion of potential future directions for the development of alignment algorithms. This work seeks to help researchers organize current advancements in the field and inspire better alignment methods. The project page of this paper is available at https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment.
OmniSTVG: Toward Spatio-Temporal Omni-Object Video Grounding
Mar 13, 2025In this paper, we propose spatio-temporal omni-object video grounding, dubbed OmniSTVG, a new STVG task that aims at localizing spatially and temporally all targets mentioned in the textual query from videos. Compared to classic STVG locating only a single target, OmniSTVG enables localization of not only an arbitrary number of text-referred targets but also their interacting counterparts in the query from the video, making it more flexible and practical in real scenarios for comprehensive understanding. In order to facilitate exploration of OmniSTVG, we introduce BOSTVG, a large-scale benchmark dedicated to OmniSTVG. Specifically, our BOSTVG consists of 10,018 videos with 10.2M frames and covers a wide selection of 287 classes from diverse scenarios. Each sequence in BOSTVG, paired with a free-form textual query, encompasses a varying number of targets ranging from 1 to 10. To ensure high quality, each video is manually annotated with meticulous inspection and refinement. To our best knowledge, BOSTVG is to date the first and the largest benchmark for OmniSTVG. To encourage future research, we introduce a simple yet effective approach, named OmniTube, which, drawing inspiration from Transformer-based STVG methods, is specially designed for OmniSTVG and demonstrates promising results. By releasing BOSTVG, we hope to go beyond classic STVG by locating every object appearing in the query for more comprehensive understanding, opening up a new direction for STVG. Our benchmark, model, and results will be released at https://github.com/JellyYao3000/OmniSTVG.
PedDet: Adaptive Spectral Optimization for Multimodal Pedestrian Detection
Feb 21, 2025



Pedestrian detection in intelligent transportation systems has made significant progress but faces two critical challenges: (1) insufficient fusion of complementary information between visible and infrared spectra, particularly in complex scenarios, and (2) sensitivity to illumination changes, such as low-light or overexposed conditions, leading to degraded performance. To address these issues, we propose PedDet, an adaptive spectral optimization complementarity framework specifically enhanced and optimized for multispectral pedestrian detection. PedDet introduces the Multi-scale Spectral Feature Perception Module (MSFPM) to adaptively fuse visible and infrared features, enhancing robustness and flexibility in feature extraction. Additionally, the Illumination Robustness Feature Decoupling Module (IRFDM) improves detection stability under varying lighting by decoupling pedestrian and background features. We further design a contrastive alignment to enhance intermodal feature discrimination. Experiments on LLVIP and MSDS datasets demonstrate that PedDet achieves state-of-the-art performance, improving the mAP by 6.6% with superior detection accuracy even in low-light conditions, marking a significant step forward for road safety. Code will be available at https://github.com/AIGeeksGroup/PedDet.
PRVQL: Progressive Knowledge-guided Refinement for Robust Egocentric Visual Query Localization
Feb 11, 2025Egocentric visual query localization (EgoVQL) focuses on localizing the target of interest in space and time from first-person videos, given a visual query. Despite recent progressive, existing methods often struggle to handle severe object appearance changes and cluttering background in the video due to lacking sufficient target cues, leading to degradation. Addressing this, we introduce PRVQL, a novel Progressive knowledge-guided Refinement framework for EgoVQL. The core is to continuously exploit target-relevant knowledge directly from videos and utilize it as guidance to refine both query and video features for improving target localization. Our PRVQL contains multiple processing stages. The target knowledge from one stage, comprising appearance and spatial knowledge extracted via two specially designed knowledge learning modules, are utilized as guidance to refine the query and videos features for the next stage, which are used to generate more accurate knowledge for further feature refinement. With such a progressive process, target knowledge in PRVQL can be gradually improved, which, in turn, leads to better refined query and video features for localization in the final stage. Compared to previous methods, our PRVQL, besides the given object cues, enjoys additional crucial target information from a video as guidance to refine features, and hence enhances EgoVQL in complicated scenes. In our experiments on challenging Ego4D, PRVQL achieves state-of-the-art result and largely surpasses other methods, showing its efficacy. Our code, model and results will be released at https://github.com/fb-reps/PRVQL.
Hierarchical Contextual Manifold Alignment for Structuring Latent Representations in Large Language Models
Feb 06, 2025The organization of latent token representations plays a crucial role in determining the stability, generalization, and contextual consistency of language models, yet conventional approaches to embedding refinement often rely on parameter modifications that introduce additional computational overhead. A hierarchical alignment method was introduced to restructure token embeddings without altering core model weights, ensuring that representational distributions maintained coherence across different linguistic contexts. Experimental evaluations demonstrated improvements in rare token retrieval, adversarial robustness, and long-range dependency tracking, highlighting the advantages of hierarchical structuring in mitigating inconsistencies in latent space organization. The comparative analysis against conventional fine-tuning and embedding perturbation methods revealed that hierarchical restructuring maintained computational efficiency while achieving measurable gains in representation quality. Structural refinements introduced through the alignment process resulted in improved contextual stability across varied linguistic tasks, reducing inconsistencies in token proximity relationships and enhancing interpretability in language generation. A detailed computational assessment confirmed that the realignment process introduced minimal inference overhead, ensuring that representational improvements did not compromise model efficiency. The findings reinforced the broader significance of structured representation learning, illustrating that hierarchical embedding modifications could serve as an effective strategy for refining latent space distributions while preserving pre-learned semantic associations.
HGSFusion: Radar-Camera Fusion with Hybrid Generation and Synchronization for 3D Object Detection
Dec 16, 2024



Millimeter-wave radar plays a vital role in 3D object detection for autonomous driving due to its all-weather and all-lighting-condition capabilities for perception. However, radar point clouds suffer from pronounced sparsity and unavoidable angle estimation errors. To address these limitations, incorporating a camera may partially help mitigate the shortcomings. Nevertheless, the direct fusion of radar and camera data can lead to negative or even opposite effects due to the lack of depth information in images and low-quality image features under adverse lighting conditions. Hence, in this paper, we present the radar-camera fusion network with Hybrid Generation and Synchronization (HGSFusion), designed to better fuse radar potentials and image features for 3D object detection. Specifically, we propose the Radar Hybrid Generation Module (RHGM), which fully considers the Direction-Of-Arrival (DOA) estimation errors in radar signal processing. This module generates denser radar points through different Probability Density Functions (PDFs) with the assistance of semantic information. Meanwhile, we introduce the Dual Sync Module (DSM), comprising spatial sync and modality sync, to enhance image features with radar positional information and facilitate the fusion of distinct characteristics in different modalities. Extensive experiments demonstrate the effectiveness of our approach, outperforming the state-of-the-art methods in the VoD and TJ4DRadSet datasets by $6.53\%$ and $2.03\%$ in RoI AP and BEV AP, respectively. The code is available at https://github.com/garfield-cpp/HGSFusion.