 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypothesis Graph Refinement: Hypothesis-Driven Exploration with Cascade Error Correction for Embodied Navigation
Apr 05, 2026Embodied agents must explore partially observed environments while maintaining reliable long-horizon memory. Existing graph-based navigation systems improve scalability, but they often treat unexplored regions as semantically unknown, leading to inefficient frontier search. Although vision-language models (VLMs) can predict frontier semantics, erroneous predictions may be embedded into memory and propagate through downstream inferences, causing structural error accumulation that confidence attenuation alone cannot resolve. These observations call for a framework that can leverage semantic predictions for directed exploration while systematically retracting errors once new evidence contradicts them. We propose Hypothesis Graph Refinement (HGR), a framework that represents frontier predictions as revisable hypothesis nodes in a dependency-aware graph memory. HGR introduces (1) semantic hypothesis module, which estimates context-conditioned semantic distributions over frontiers and ranks exploration targets by goal relevance, travel cost, and uncertainty, and (2) verification-driven cascade correction, which compares on-site observations against predicted semantics and, upon mismatch, retracts the refuted node together with all its downstream dependents. Unlike additive map-building, this allows the graph to contract by pruning erroneous subgraphs, keeping memory reliable throughout long episodes. We evaluate HGR on multimodal lifelong navigation (GOAT-Bench) and embodied question answering (A-EQA, EM-EQA). HGR achieves 72.41% success rate and 56.22% SPL on GOAT-Bench, and shows consistent improvements on both QA benchmarks. Diagnostic analysis reveals that cascade correction eliminates approximately 20% of structurally redundant hypothesis nodes and reduces revisits to erroneous regions by 4.5x, with specular and transparent surfaces accounting for 67% of corrected prediction errors.
Personalized Federated Learning via Gaussian Generative Modeling
Mar 12, 2026Federated learning has emerged as a paradigm to train models collaboratively on inherently distributed client data while safeguarding privacy. In this context, personalized federated learning tackles the challenge of data heterogeneity by equipping each client with a dedicated model. A prevalent strategy decouples the model into a shared feature extractor and a personalized classifier head, where the latter actively guides the representation learning. However, previous works have focused on classifier head-guided personalization, neglecting the potential personalized characteristics in the representation distribution. Building on this insight, we propose pFedGM, a method based on Gaussian generative modeling. The approach begins by training a Gaussian generator that models client heterogeneity via weighted re-sampling. A balance between global collaboration and personalization is then struck by employing a dual objective: a shared objective that maximizes inter-class distance across clients, and a local objective that minimizes intra-class distance within them. To achieve this, we decouple the conventional Gaussian classifier into a navigator for global optimization, and a statistic extractor for capturing distributional statistics. Inspired by the Kalman gain, the algorithm then employs a dual-scale fusion framework at global and local levels to equip each client with a personalized classifier head. In this framework, we model the global representation distribution as a prior and the client-specific data as the likelihood, enabling Bayesian inference for class probability estimation. The evaluation covers a comprehensive range of scenarios: heterogeneity in class counts, environmental corruption, and multiple benchmark datasets and configurations. pFedGM achieves superior or competitive performance compared to state-of-the-art methods.
CGL: Advancing Continual GUI Learning via Reinforcement Fine-Tuning
Mar 03, 2026Graphical User Interface (GUI) Agents, benefiting from recent advances in multimodal large language models (MLLM), have achieved significant development. However, due to the frequent updates of GUI applications, adapting to new tasks without forgetting old tasks in GUI continual learning remains an open problem. In this work, we reveal that while Supervised Fine-Tuning (SFT) facilitates fast adaptation, it often triggers knowledge overwriting, whereas Reinforcement Learning (RL) demonstrates an inherent resilience that shields prior interaction logic from erasure. Based on this insight, we propose a \textbf{C}ontinual \textbf{G}UI \textbf{L}earning (CGL) framework that dynamically balances adaptation efficiency and skill retention by enhancing the synergy between SFT and RL. Specifically, we introduce an SFT proportion adjustment mechanism guided by policy entropy to dynamically control the weight allocation between the SFT and RL training phases. To resolve explicit gradient interference, we further develop a specialized gradient surgery strategy. By projecting exploratory SFT gradients onto GRPO-based anchor gradients, our method explicitly clips the components of SFT gradients that conflict with GRPO. On top of that, we establish an AndroidControl-CL benchmark, which divides GUI applications into distinct task groups to effectively simulate and evaluate the performance of continual GUI learning. Experimental results demonstrate the effectiveness of our proposed CGL framework across continual learning scenarios. The benchmark, code, and model will be made publicly available.
Seismology modeling agent: A smart assistant for geophysical researchers
Dec 16, 2025To address the steep learning curve and reliance on complex manual file editing and command-line operations in the traditional workflow of the mainstream open-source seismic wave simulation software SPECFEM, this paper proposes an intelligent, interactive workflow powered by Large Language Models (LLMs). We introduce the first Model Context Protocol (MCP) server suite for SPECFEM (supporting 2D, 3D Cartesian, and 3D Globe versions), which decomposes the entire simulation process into discrete, agent-executable tools spanning from parameter generation and mesh partitioning to solver execution and visualization. This approach enables a paradigm shift from file-driven to intent-driven conversational interactions. The framework supports both fully automated execution and human-in-the-loop collaboration, allowing researchers to guide simulation strategies in real time and retain scientific decision-making authority while significantly reducing tedious low-level operations. Validated through multiple case studies, the workflow operates seamlessly in both autonomous and interactive modes, yielding high-fidelity results consistent with standard baselines. As the first application of MCP technology to computational seismology, this study significantly lowers the entry barrier, enhances reproducibility, and offers a promising avenue for advancing computational geophysics toward AI-assisted and automated scientific research. The complete source code is available at https://github.com/RenYukun1563/specfem-mcp.
Fractal Flow: Hierarchical and Interpretable Normalizing Flow via Topic Modeling and Recursive Strategy
Aug 27, 2025



Normalizing Flows provide a principled framework for high-dimensional density estimation and generative modeling by constructing invertible transformations with tractable Jacobian determinants. We propose Fractal Flow, a novel normalizing flow architecture that enhances both expressiveness and interpretability through two key innovations. First, we integrate Kolmogorov-Arnold Networks and incorporate Latent Dirichlet Allocation into normalizing flows to construct a structured, interpretable latent space and model hierarchical semantic clusters. Second, inspired by Fractal Generative Models, we introduce a recursive modular design into normalizing flows to improve transformation interpretability and estimation accuracy. Experiments on MNIST, FashionMNIST, CIFAR-10, and geophysical data demonstrate that the Fractal Flow achieves latent clustering, controllable generation, and superior estimation accuracy.
Feature-Space Planes Searcher: A Universal Domain Adaptation Framework for Interpretability and Computational Efficiency
Aug 26, 2025Domain shift, characterized by degraded model performance during transition from labeled source domains to unlabeled target domains, poses a persistent challenge for deploying deep learning systems. Current unsupervised domain adaptation (UDA) methods predominantly rely on fine-tuning feature extractors - an approach limited by inefficiency, reduced interpretability, and poor scalability to modern architectures. Our analysis reveals that models pretrained on large-scale data exhibit domain-invariant geometric patterns in their feature space, characterized by intra-class clustering and inter-class separation, thereby preserving transferable discriminative structures. These findings indicate that domain shifts primarily manifest as boundary misalignment rather than feature degradation. Unlike fine-tuning entire pre-trained models - which risks introducing unpredictable feature distortions - we propose the Feature-space Planes Searcher (FPS): a novel domain adaptation framework that optimizes decision boundaries by leveraging these geometric patterns while keeping the feature encoder frozen. This streamlined approach enables interpretative analysis of adaptation while substantially reducing memory and computational costs through offline feature extraction, permitting full-dataset optimization in a single computation cycle. Evaluations on public benchmarks demonstrate that FPS achieves competitive or superior performance to state-of-the-art methods. FPS scales efficiently with multimodal large models and shows versatility across diverse domains including protein structure prediction, remote sensing classification, and earthquake detection. We anticipate FPS will provide a simple, effective, and generalizable paradigm for transfer learning, particularly in domain adaptation tasks. .
HGSFusion: Radar-Camera Fusion with Hybrid Generation and Synchronization for 3D Object Detection
Dec 16, 2024



Millimeter-wave radar plays a vital role in 3D object detection for autonomous driving due to its all-weather and all-lighting-condition capabilities for perception. However, radar point clouds suffer from pronounced sparsity and unavoidable angle estimation errors. To address these limitations, incorporating a camera may partially help mitigate the shortcomings. Nevertheless, the direct fusion of radar and camera data can lead to negative or even opposite effects due to the lack of depth information in images and low-quality image features under adverse lighting conditions. Hence, in this paper, we present the radar-camera fusion network with Hybrid Generation and Synchronization (HGSFusion), designed to better fuse radar potentials and image features for 3D object detection. Specifically, we propose the Radar Hybrid Generation Module (RHGM), which fully considers the Direction-Of-Arrival (DOA) estimation errors in radar signal processing. This module generates denser radar points through different Probability Density Functions (PDFs) with the assistance of semantic information. Meanwhile, we introduce the Dual Sync Module (DSM), comprising spatial sync and modality sync, to enhance image features with radar positional information and facilitate the fusion of distinct characteristics in different modalities. Extensive experiments demonstrate the effectiveness of our approach, outperforming the state-of-the-art methods in the VoD and TJ4DRadSet datasets by $6.53\%$ and $2.03\%$ in RoI AP and BEV AP, respectively. The code is available at https://github.com/garfield-cpp/HGSFusion.
No One-Size-Fits-All Neurons: Task-based Neurons for Artificial Neural Networks
May 03, 2024



Biologically, the brain does not rely on a single type of neuron that universally functions in all aspects. Instead, it acts as a sophisticated designer of task-based neurons. In this study, we address the following question: since the human brain is a task-based neuron user, can the artificial network design go from the task-based architecture design to the task-based neuron design? Since methodologically there are no one-size-fits-all neurons, given the same structure, task-based neurons can enhance the feature representation ability relative to the existing universal neurons due to the intrinsic inductive bias for the task. Specifically, we propose a two-step framework for prototyping task-based neurons. First, symbolic regression is used to identify optimal formulas that fit input data by utilizing base functions such as logarithmic, trigonometric, and exponential functions. We introduce vectorized symbolic regression that stacks all variables in a vector and regularizes each input variable to perform the same computation, which can expedite the regression speed, facilitate parallel computation, and avoid overfitting. Second, we parameterize the acquired elementary formula to make parameters learnable, which serves as the aggregation function of the neuron. The activation functions such as ReLU and the sigmoidal functions remain the same because they have proven to be good. Empirically, experimental results on synthetic data, classic benchmarks, and real-world applications show that the proposed task-based neuron design is not only feasible but also delivers competitive performance over other state-of-the-art models.
A fast and gridless ORKA algorithm for tracking moving and deforming objects
Feb 04, 2024Identifying objects in given data is a task frequently encountered in many applications. Finding vehicles or persons in video data, tracking seismic waves in geophysical exploration data, or predicting a storm front movement from meteorological measurements are only some of the possible applications. In many cases, the object of interest changes its form or position from one measurement to another. For example, vehicles in a video may change its position or angle to the camera in each frame. Seismic waves can change its arrival time, frequency, or intensity depending on the sensor position. Storm fronts can change its form and position over time. This complicates the identification and tracking as the algorithm needs to deal with the changing object over the given measurements. In a previous work, the authors presented a new algorithm to solve this problem - Object reconstruction using K-approximation (ORKA). The algorithm can solve the problem at hand but suffers from two disadvantages. On the one hand, the reconstructed object movement is bound to a grid that depends on the data resolution. On the other hand, the complexity of the algorithm increases exponentially with the resolution. We overcome both disadvantages by introducing an iterative strategy that uses a resampling method to create multiple resolutions of the data. In each iteration the resolution is increased to reconstruct more details of the object of interest. This way, we can even go beyond the original resolution by artificially upsampling the data. We give error bounds and a complexity analysis of the new method. Furthermore, we analyze its performance in several numerical experiments as well as on real data. We also give a brief introduction on the original ORKA algorithm. Knowledge of the previous work is thus not required.
Wave simulation in non-smooth media by PINN with quadratic neural network and PML condition
Aug 16, 2022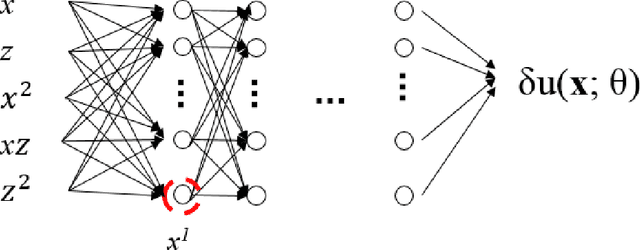
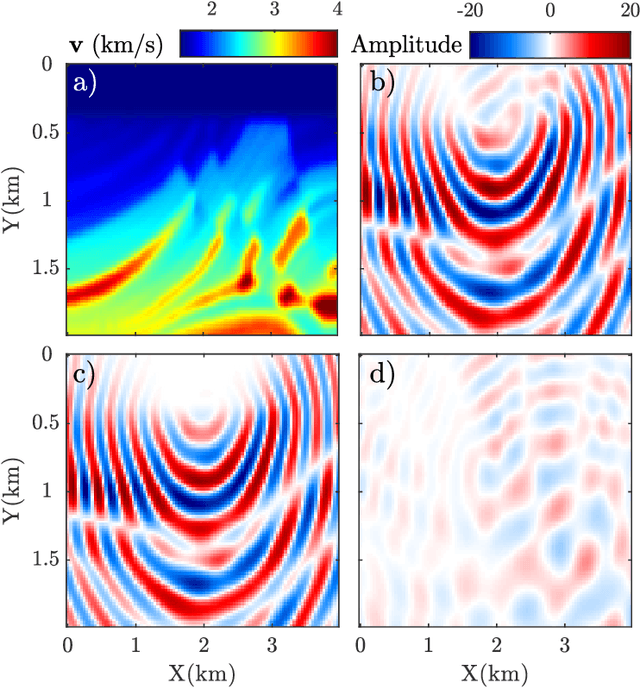
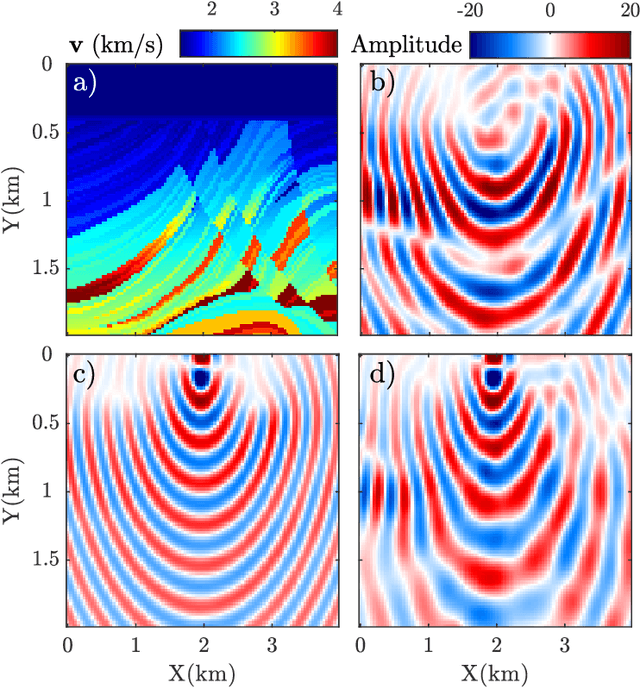
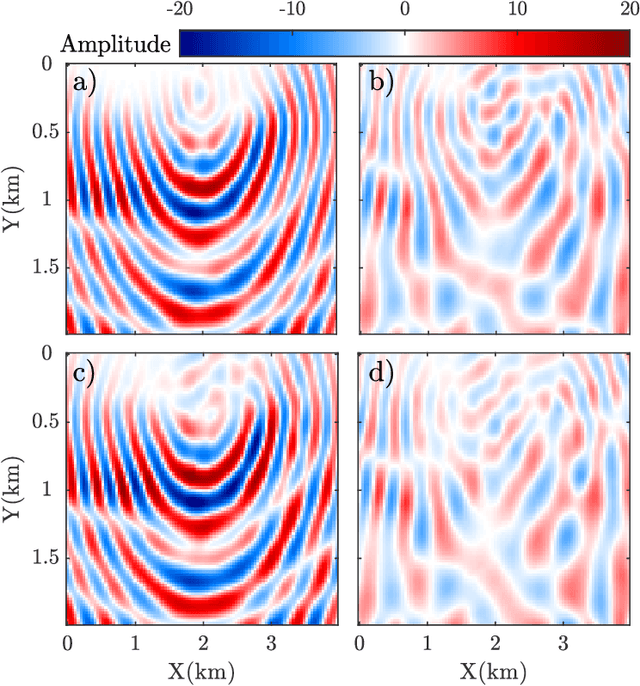
Frequency-domain simulation of seismic waves plays an important role in seismic inversion, but it remains challenging in large models. The recently proposed physics-informed neural network (PINN), as an effective deep learning method, has achieved successful applications in solving a wide range of partial differential equations (PDEs), and there is still room for improvement on this front. For example, PINN can lead to inaccurate solutions when PDE coefficients are non-smooth and describe structurally-complex media. In this paper, we solve the acoustic and visco-acoustic scattered-field wave equation in the frequency domain with PINN instead of the wave equation to remove source singularity. We first illustrate that non-smooth velocity models lead to inaccurate wavefields when no boundary conditions are implemented in the loss function. Then, we add the perfectly matched layer (PML) conditions in the loss function of PINN and design a quadratic neural network to overcome the detrimental effects of non-smooth models in PINN. We show that PML and quadratic neurons improve the results as well as attenuation and discuss the reason for this improvement. We also illustrate that a network trained during a wavefield simulation can be used to pre-train the neural network of another wavefield simulation after PDE-coefficient alteration and improve the convergence speed accordingly. This pre-training strategy should find application in iterative full waveform inversion (FWI) and time-lag target-oriented imaging when the model perturbation between two consecutive iterations or two consecutive experiments can be small.