 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Generalization of Depth Estimation Foundation Model via Weakly-Supervised Adaptation with Regularization
Nov 18, 2025The emergence of foundation models has substantially advanced zero-shot generalization in monocular depth estimation (MDE), as exemplified by the Depth Anything series. However, given access to some data from downstream tasks, a natural question arises: can the performance of these models be further improved? To this end, we propose WeSTAR, a parameter-efficient framework that performs Weakly supervised Self-Training Adaptation with Regularization, designed to enhance the robustness of MDE foundation models in unseen and diverse domains. We first adopt a dense self-training objective as the primary source of structural self-supervision. To further improve robustness, we introduce semantically-aware hierarchical normalization, which exploits instance-level segmentation maps to perform more stable and multi-scale structural normalization. Beyond dense supervision, we introduce a cost-efficient weak supervision in the form of pairwise ordinal depth annotations to further guide the adaptation process, which enforces informative ordinal constraints to mitigate local topological errors. Finally, a weight regularization loss is employed to anchor the LoRA updates, ensuring training stability and preserving the model's generalizable knowledge. Extensive experiments on both realistic and corrupted out-of-distribution datasets under diverse and challenging scenarios demonstrate that WeSTAR consistently improves generalization and achieves state-of-the-art performance across a wide range of benchmarks.
UMIGen: A Unified Framework for Egocentric Point Cloud Generation and Cross-Embodiment Robotic Imitation Learning
Nov 12, 2025



Data-driven robotic learning faces an obvious dilemma: robust policies demand large-scale, high-quality demonstration data, yet collecting such data remains a major challenge owing to high operational costs, dependence on specialized hardware, and the limited spatial generalization capability of current methods. The Universal Manipulation Interface (UMI) relaxes the strict hardware requirements for data collection, but it is restricted to capturing only RGB images of a scene and omits the 3D geometric information on which many tasks rely. Inspired by DemoGen, we propose UMIGen, a unified framework that consists of two key components: (1) Cloud-UMI, a handheld data collection device that requires no visual SLAM and simultaneously records point cloud observation-action pairs; and (2) a visibility-aware optimization mechanism that extends the DemoGen pipeline to egocentric 3D observations by generating only points within the camera's field of view. These two components enable efficient data generation that aligns with real egocentric observations and can be directly transferred across different robot embodiments without any post-processing. Experiments in both simulated and real-world settings demonstrate that UMIGen supports strong cross-embodiment generalization and accelerates data collection in diverse manipulation tasks.
EgoDemoGen: Novel Egocentric Demonstration Generation Enables Viewpoint-Robust Manipulation
Sep 26, 2025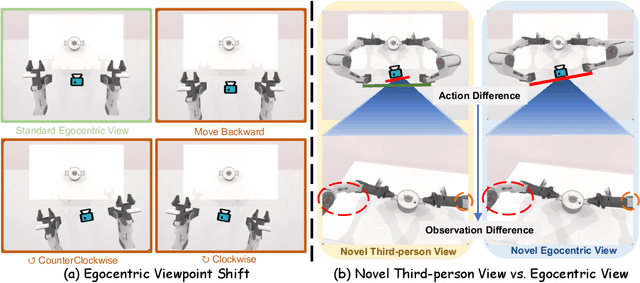

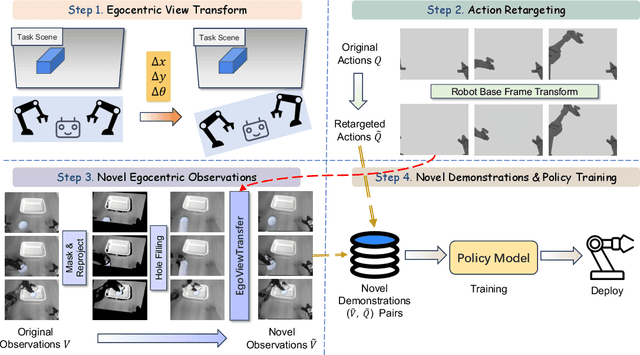
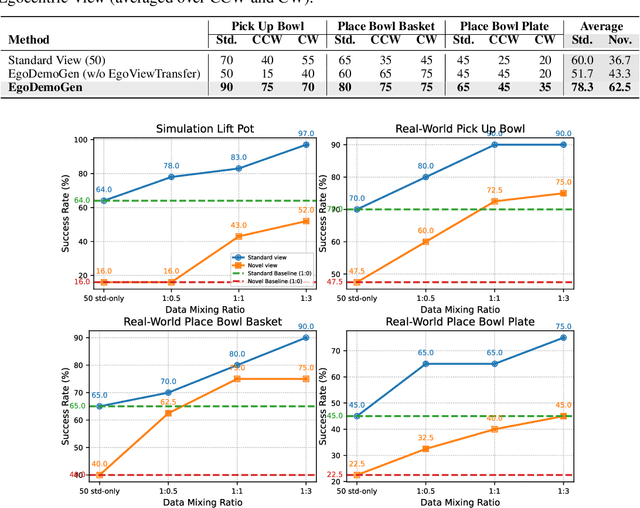
Imitation learning based policies perform well in robotic manipulation, but they often degrade under *egocentric viewpoint shifts* when trained from a single egocentric viewpoint. To address this issue, we present **EgoDemoGen**, a framework that generates *paired* novel egocentric demonstrations by retargeting actions in the novel egocentric frame and synthesizing the corresponding egocentric observation videos with proposed generative video repair model **EgoViewTransfer**, which is conditioned by a novel-viewpoint reprojected scene video and a robot-only video rendered from the retargeted joint actions. EgoViewTransfer is finetuned from a pretrained video generation model using self-supervised double reprojection strategy. We evaluate EgoDemoGen on both simulation (RoboTwin2.0) and real-world robot. After training with a mixture of EgoDemoGen-generated novel egocentric demonstrations and original standard egocentric demonstrations, policy success rate improves **absolutely** by **+17.0%** for standard egocentric viewpoint and by **+17.7%** for novel egocentric viewpoints in simulation. On real-world robot, the **absolute** improvements are **+18.3%** and **+25.8%**. Moreover, performance continues to improve as the proportion of EgoDemoGen-generated demonstrations increases, with diminishing returns. These results demonstrate that EgoDemoGen provides a practical route to egocentric viewpoint-robust robotic manipulation.
UltraTac: Integrated Ultrasound-Augmented Visuotactile Sensor for Enhanced Robotic Perception
Aug 29, 2025

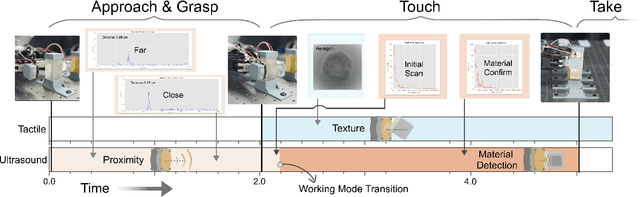
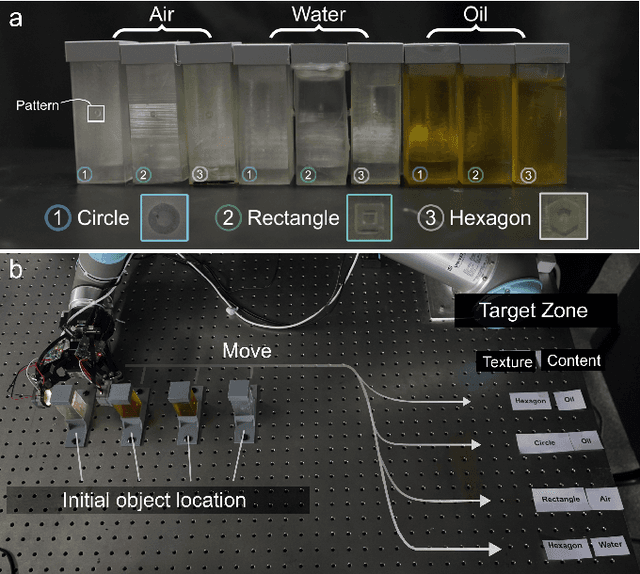
Visuotactile sensors provide high-resolution tactile information but are incapable of perceiving the material features of objects. We present UltraTac, an integrated sensor that combines visuotactile imaging with ultrasound sensing through a coaxial optoacoustic architecture. The design shares structural components and achieves consistent sensing regions for both modalities. Additionally, we incorporate acoustic matching into the traditional visuotactile sensor structure, enabling integration of the ultrasound sensing modality without compromising visuotactile performance. Through tactile feedback, we dynamically adjust the operating state of the ultrasound module to achieve flexible functional coordination. Systematic experiments demonstrate three key capabilities: proximity sensing in the 3-8 cm range ($R^2=0.90$), material classification (average accuracy: 99.20%), and texture-material dual-mode object recognition achieving 92.11% accuracy on a 15-class task. Finally, we integrate the sensor into a robotic manipulation system to concurrently detect container surface patterns and internal content, which verifies its potential for advanced human-machine interaction and precise robotic manipulation.
CoCoL: A Communication Efficient Decentralized Collaborative Method for Multi-Robot Systems
Aug 28, 2025Collaborative learning enhances the performance and adaptability of multi-robot systems in complex tasks but faces significant challenges due to high communication overhead and data heterogeneity inherent in multi-robot tasks. To this end, we propose CoCoL, a Communication efficient decentralized Collaborative Learning method tailored for multi-robot systems with heterogeneous local datasets. Leveraging a mirror descent framework, CoCoL achieves remarkable communication efficiency with approximate Newton-type updates by capturing the similarity between objective functions of robots, and reduces computational costs through inexact sub-problem solutions. Furthermore, the integration of a gradient tracking scheme ensures its robustness against data heterogeneity. Experimental results on three representative multi robot collaborative learning tasks show the superiority of the proposed CoCoL in significantly reducing both the number of communication rounds and total bandwidth consumption while maintaining state-of-the-art accuracy. These benefits are particularly evident in challenging scenarios involving non-IID (non-independent and identically distributed) data distribution, streaming data, and time-varying network topologies.
Interleaved Transceiver Design for a Continuous- Transmission MIMO-OFDM ISAC System
Aug 14, 2025This paper proposes an interleaved transceiver design method for a multiple-input multiple-output (MIMO) integrated sensing and communication (ISAC) system utilizing orthogonal frequency division multiplexing (OFDM) waveforms. We consider a continuous transmission system and focus on the design of the transmission signal and a receiving filter in the time domain for an interleaved transmission architecture. For communication performance, constructive interference (CI) is integrated into the optimization problem. For radar sensing performance, the integrated mainlobe-to-sidelobe ratio (IMSR) of the beampattern is considered to ensure desirable directivity. Additionally, we tackle the challenges of inter-block interference and eliminate the spurious peaks, which are crucial for accurate target detection. Regarding the hardware implementation aspect, the power of each time sample is constrained to manage the peak-to-average power ratio (PAPR). The design problem is addressed using an alternating optimization (AO) framework, with the subproblem for transmitted waveform design being solved via the successive convex approximation (SCA) method. To further enhance computational efficiency, the alternate direction penalty method (ADPM) is employed to solve the subproblems within the SCA iterations. The convergence of ADPM is established, with convergence of the case of more than two auxiliary variables being established for the first time. Numerical simulations validate the effectiveness of our transceiver design in achieving desirable performance in both radar sensing and communication, with the fast algorithm achieving comparable performance with greater computational efficiency.
DTPA: Dynamic Token-level Prefix Augmentation for Controllable Text Generation
Aug 06, 2025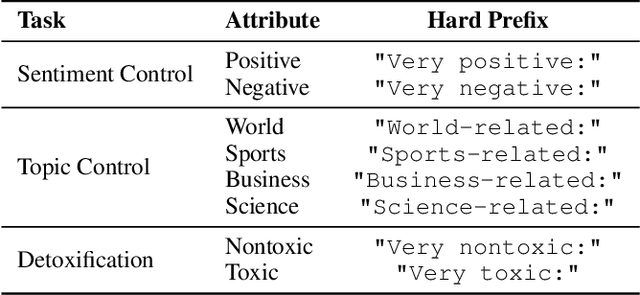

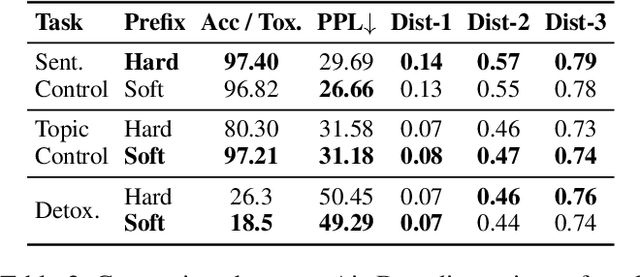

Controllable Text Generation (CTG) is a vital subfield in Natural Language Processing (NLP), aiming to generate text that aligns with desired attributes. However, previous studies commonly focus on the quality of controllable text generation for short sequences, while the generation of long-form text remains largely underexplored. In this paper, we observe that the controllability of texts generated by the powerful prefix-based method Air-Decoding tends to decline with increasing sequence length, which we hypothesize primarily arises from the observed decay in attention to the prefixes. Meanwhile, different types of prefixes including soft and hard prefixes are also key factors influencing performance. Building on these insights, we propose a lightweight and effective framework called Dynamic Token-level Prefix Augmentation (DTPA) based on Air-Decoding for controllable text generation. Specifically, it first selects the optimal prefix type for a given task. Then we dynamically amplify the attention to the prefix for the attribute distribution to enhance controllability, with a scaling factor growing exponentially as the sequence length increases. Moreover, based on the task, we optionally apply a similar augmentation to the original prompt for the raw distribution to balance text quality. After attribute distribution reconstruction, the generated text satisfies the attribute constraints well. Experiments on multiple CTG tasks demonstrate that DTPA generally outperforms other methods in attribute control while maintaining competitive fluency, diversity, and topic relevance. Further analysis highlights DTPA's superior effectiveness in long text generation.
EC-Flow: Enabling Versatile Robotic Manipulation from Action-Unlabeled Videos via Embodiment-Centric Flow
Jul 08, 2025



Current language-guided robotic manipulation systems often require low-level action-labeled datasets for imitation learning. While object-centric flow prediction methods mitigate this issue, they remain limited to scenarios involving rigid objects with clear displacement and minimal occlusion. In this work, we present Embodiment-Centric Flow (EC-Flow), a framework that directly learns manipulation from action-unlabeled videos by predicting embodiment-centric flow. Our key insight is that incorporating the embodiment's inherent kinematics significantly enhances generalization to versatile manipulation scenarios, including deformable object handling, occlusions, and non-object-displacement tasks. To connect the EC-Flow with language instructions and object interactions, we further introduce a goal-alignment module by jointly optimizing movement consistency and goal-image prediction. Moreover, translating EC-Flow to executable robot actions only requires a standard robot URDF (Unified Robot Description Format) file to specify kinematic constraints across joints, which makes it easy to use in practice. We validate EC-Flow on both simulation (Meta-World) and real-world tasks, demonstrating its state-of-the-art performance in occluded object handling (62% improvement), deformable object manipulation (45% improvement), and non-object-displacement tasks (80% improvement) than prior state-of-the-art object-centric flow methods. For more information, see our project website at https://ec-flow1.github.io .
BridgeVLA: Input-Output Alignment for Efficient 3D Manipulation Learning with Vision-Language Models
Jun 09, 2025Recently, leveraging pre-trained vision-language models (VLMs) for building vision-language-action (VLA) models has emerged as a promising approach to effective robot manipulation learning. However, only few methods incorporate 3D signals into VLMs for action prediction, and they do not fully leverage the spatial structure inherent in 3D data, leading to low sample efficiency. In this paper, we introduce BridgeVLA, a novel 3D VLA model that (1) projects 3D inputs to multiple 2D images, ensuring input alignment with the VLM backbone, and (2) utilizes 2D heatmaps for action prediction, unifying the input and output spaces within a consistent 2D image space. In addition, we propose a scalable pre-training method that equips the VLM backbone with the capability to predict 2D heatmaps before downstream policy learning. Extensive experiments show the proposed method is able to learn 3D manipulation efficiently and effectively. BridgeVLA outperforms state-of-the-art baseline methods across three simulation benchmarks. In RLBench, it improves the average success rate from 81.4% to 88.2%. In COLOSSEUM, it demonstrates significantly better performance in challenging generalization settings, boosting the average success rate from 56.7% to 64.0%. In GemBench, it surpasses all the comparing baseline methods in terms of average success rate. In real-robot experiments, BridgeVLA outperforms a state-of-the-art baseline method by 32% on average. It generalizes robustly in multiple out-of-distribution settings, including visual disturbances and unseen instructions. Remarkably, it is able to achieve a success rate of 96.8% on 10+ tasks with only 3 trajectories per task, highlighting its extraordinary sample efficiency. Project Website:https://bridgevla.github.io/
Enhancing Marker Scoring Accuracy through Ordinal Confidence Modelling in Educational Assessments
May 29, 2025A key ethical challenge in Automated Essay Scoring (AES) is ensuring that scores are only released when they meet high reliability standards. Confidence modelling addresses this by assigning a reliability estimate measure, in the form of a confidence score, to each automated score. In this study, we frame confidence estimation as a classification task: predicting whether an AES-generated score correctly places a candidate in the appropriate CEFR level. While this is a binary decision, we leverage the inherent granularity of the scoring domain in two ways. First, we reformulate the task as an n-ary classification problem using score binning. Second, we introduce a set of novel Kernel Weighted Ordinal Categorical Cross Entropy (KWOCCE) loss functions that incorporate the ordinal structure of CEFR labels. Our best-performing model achieves an F1 score of 0.97, and enables the system to release 47% of scores with 100% CEFR agreement and 99% with at least 95% CEFR agreement -compared to approximately 92% (approx.) CEFR agreement from the standalone AES model where we release all AM predicted scores.