 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqPE: Transformer with Sequential Position Encoding
Jun 16, 2025Since self-attention layers in Transformers are permutation invariant by design, positional encodings must be explicitly incorporated to enable spatial understanding. However, fixed-size lookup tables used in traditional learnable position embeddings (PEs) limit extrapolation capabilities beyond pre-trained sequence lengths. Expert-designed methods such as ALiBi and RoPE, mitigate this limitation but demand extensive modifications for adapting to new modalities, underscoring fundamental challenges in adaptability and scalability. In this work, we present SeqPE, a unified and fully learnable position encoding framework that represents each $n$-dimensional position index as a symbolic sequence and employs a lightweight sequential position encoder to learn their embeddings in an end-to-end manner. To regularize SeqPE's embedding space, we introduce two complementary objectives: a contrastive objective that aligns embedding distances with a predefined position-distance function, and a knowledge distillation loss that anchors out-of-distribution position embeddings to in-distribution teacher representations, further enhancing extrapolation performance. Experiments across language modeling, long-context question answering, and 2D image classification demonstrate that SeqPE not only surpasses strong baselines in perplexity, exact match (EM), and accuracy--particularly under context length extrapolation--but also enables seamless generalization to multi-dimensional inputs without requiring manual architectural redesign. We release our code, data, and checkpoints at https://github.com/ghrua/seqpe.
Evaluating Multimodal Large Language Models on Video Captioning via Monte Carlo Tree Search
Jun 11, 2025Video captioning can be used to assess the video understanding capabilities of Multimodal Large Language Models (MLLMs). However, existing benchmarks and evaluation protocols suffer from crucial issues, such as inadequate or homogeneous creation of key points, exorbitant cost of data creation, and limited evaluation scopes. To address these issues, we propose an automatic framework, named AutoCaption, which leverages Monte Carlo Tree Search (MCTS) to construct numerous and diverse descriptive sentences (\textit{i.e.}, key points) that thoroughly represent video content in an iterative way. This iterative captioning strategy enables the continuous enhancement of video details such as actions, objects' attributes, environment details, etc. We apply AutoCaption to curate MCTS-VCB, a fine-grained video caption benchmark covering video details, thereby enabling a comprehensive evaluation of MLLMs on the video captioning task. We evaluate more than 20 open- and closed-source MLLMs of varying sizes on MCTS-VCB. Results show that MCTS-VCB can effectively and comprehensively evaluate the video captioning capability, with Gemini-1.5-Pro achieving the highest F1 score of 71.2. Interestingly, we fine-tune InternVL2.5-8B with the AutoCaption-generated data, which helps the model achieve an overall improvement of 25.0% on MCTS-VCB and 16.3% on DREAM-1K, further demonstrating the effectiveness of AutoCaption. The code and data are available at https://github.com/tjunlp-lab/MCTS-VCB.
What Makes a Good Reasoning Chain? Uncovering Structural Patterns in Long Chain-of-Thought Reasoning
May 28, 2025



Recent advances in reasoning with large language models (LLMs) have popularized Long Chain-of-Thought (LCoT), a strategy that encourages deliberate and step-by-step reasoning before producing a final answer. While LCoTs have enabled expert-level performance in complex tasks, how the internal structures of their reasoning chains drive, or even predict, the correctness of final answers remains a critical yet underexplored question. In this work, we present LCoT2Tree, an automated framework that converts sequential LCoTs into hierarchical tree structures and thus enables deeper structural analysis of LLM reasoning. Using graph neural networks (GNNs), we reveal that structural patterns extracted by LCoT2Tree, including exploration, backtracking, and verification, serve as stronger predictors of final performance across a wide range of tasks and models. Leveraging an explainability technique, we further identify critical thought patterns such as over-branching that account for failures. Beyond diagnostic insights, the structural patterns by LCoT2Tree support practical applications, including improving Best-of-N decoding effectiveness. Overall, our results underscore the critical role of internal structures of reasoning chains, positioning LCoT2Tree as a powerful tool for diagnosing, interpreting, and improving reasoning in LLMs.
Modality Curation: Building Universal Embeddings for Advanced Multimodal Information Retrieval
May 26, 2025
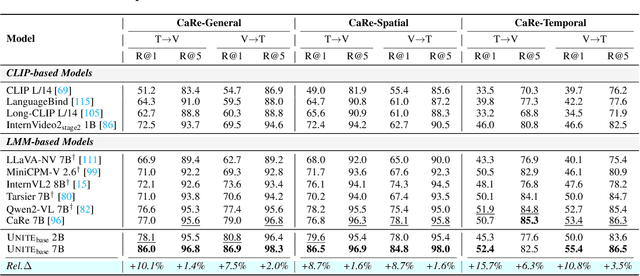

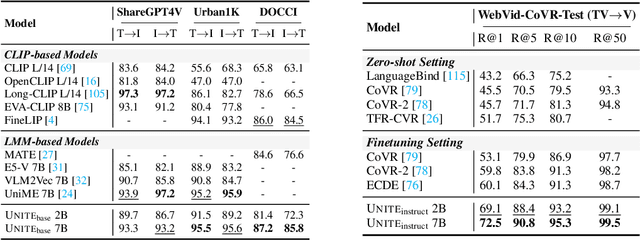
Multimodal information retrieval (MIR) faces inherent challenges due to the heterogeneity of data sources and the complexity of cross-modal alignment. While previous studies have identified modal gaps in feature spaces, a systematic approach to address these challenges remains unexplored. In this work, we introduce UNITE, a universal framework that tackles these challenges through two critical yet underexplored aspects: data curation and modality-aware training configurations. Our work provides the first comprehensive analysis of how modality-specific data properties influence downstream task performance across diverse scenarios. Moreover, we propose Modal-Aware Masked Contrastive Learning (MAMCL) to mitigate the competitive relationships among the instances of different modalities. Our framework achieves state-of-the-art results on multiple multimodal retrieval benchmarks, outperforming existing methods by notable margins. Through extensive experiments, we demonstrate that strategic modality curation and tailored training protocols are pivotal for robust cross-modal representation learning. This work not only advances MIR performance but also provides a foundational blueprint for future research in multimodal systems. Our project is available at https://friedrichor.github.io/projects/UNITE.
Evaluating Text Creativity across Diverse Domains: A Dataset and Large Language Model Evaluator
May 25, 2025Creativity evaluation remains a challenging frontier for large language models (LLMs). Current evaluations heavily rely on inefficient and costly human judgments, hindering progress in enhancing machine creativity. While automated methods exist, ranging from psychological testing to heuristic- or prompting-based approaches, they often lack generalizability or alignment with human judgment. To address these issues, in this paper, we propose a novel pairwise-comparison framework for assessing textual creativity, leveraging shared contextual instructions to improve evaluation consistency. We introduce CreataSet, a large-scale dataset with 100K+ human-level and 1M+ synthetic creative instruction-response pairs spanning diverse open-domain tasks. Through training on CreataSet, we develop an LLM-based evaluator named CrEval. CrEval demonstrates remarkable superiority over existing methods in alignment with human judgments. Experimental results underscore the indispensable significance of integrating both human-generated and synthetic data in training highly robust evaluators, and showcase the practical utility of CrEval in boosting the creativity of LLMs. We will release all data, code, and models publicly soon to support further research.
Guiding the Experts: Semantic Priors for Efficient and Focused MoE Routing
May 24, 2025Mixture-of-Experts (MoE) models have emerged as a promising direction for scaling vision architectures efficiently. Among them, Soft MoE improves training stability by assigning each token to all experts via continuous dispatch weights. However, current designs overlook the semantic structure which is implicitly encoded in these weights, resulting in suboptimal expert routing. In this paper, we discover that dispatch weights in Soft MoE inherently exhibit segmentation-like patterns but are not explicitly aligned with semantic regions. Motivated by this observation, we propose a foreground-guided enhancement strategy. Specifically, we introduce a spatially aware auxiliary loss that encourages expert activation to align with semantic foreground regions. To further reinforce this supervision, we integrate a lightweight LayerScale mechanism that improves information flow and stabilizes optimization in skip connections. Our method necessitates only minor architectural adjustments and can be seamlessly integrated into prevailing Soft MoE frameworks. Comprehensive experiments on ImageNet-1K and multiple smaller-scale classification benchmarks not only showcase consistent performance enhancements but also reveal more interpretable expert routing mechanisms.
DiffusionReward: Enhancing Blind Face Restoration through Reward Feedback Learning
May 23, 2025Reward Feedback Learning (ReFL) has recently shown great potential in aligning model outputs with human preferences across various generative tasks. In this work, we introduce a ReFL framework, named DiffusionReward, to the Blind Face Restoration task for the first time. DiffusionReward effectively overcomes the limitations of diffusion-based methods, which often fail to generate realistic facial details and exhibit poor identity consistency. The core of our framework is the Face Reward Model (FRM), which is trained using carefully annotated data. It provides feedback signals that play a pivotal role in steering the optimization process of the restoration network. In particular, our ReFL framework incorporates a gradient flow into the denoising process of off-the-shelf face restoration methods to guide the update of model parameters. The guiding gradient is collaboratively determined by three aspects: (i) the FRM to ensure the perceptual quality of the restored faces; (ii) a regularization term that functions as a safeguard to preserve generative diversity; and (iii) a structural consistency constraint to maintain facial fidelity. Furthermore, the FRM undergoes dynamic optimization throughout the process. It not only ensures that the restoration network stays precisely aligned with the real face manifold, but also effectively prevents reward hacking. Experiments on synthetic and wild datasets demonstrate that our method outperforms state-of-the-art methods, significantly improving identity consistency and facial details. The source codes, data, and models are available at: https://github.com/01NeuralNinja/DiffusionReward.
Leanabell-Prover: Posttraining Scaling in Formal Reasoning
Apr 09, 2025Recent advances in automated theorem proving (ATP) through LLMs have highlighted the potential of formal reasoning with Lean 4 codes. However, ATP has not yet be revolutionized by the recent posttraining scaling as demonstrated by Open AI O1/O3 and Deepseek R1. In this work, we investigate the entire posttraining of ATP, aiming to align it with breakthroughs in reasoning models in natural languages. To begin, we continual train current ATP models with a hybrid dataset, which consists of numerous statement-proof pairs, and additional data aimed at incorporating cognitive behaviors that emulate human reasoning and hypothesis refinement. Next, we explore reinforcement learning with the use of outcome reward returned by Lean 4 compiler. Through our designed continual training and reinforcement learning processes, we have successfully improved existing formal provers, including both DeepSeek-Prover-v1.5 and Goedel-Prover, achieving state-of-the-art performance in the field of whole-proof generation. For example, we achieve a 59.8% pass rate (pass@32) on MiniF2F. This is an on-going project and we will progressively update our findings, release our data and training details.
SEGT: A General Spatial Expansion Group Transformer for nuScenes Lidar-based Object Detection Task
Dec 12, 2024

In the technical report, we present a novel transformer-based framework for nuScenes lidar-based object detection task, termed Spatial Expansion Group Transformer (SEGT). To efficiently handle the irregular and sparse nature of point cloud, we propose migrating the voxels into distinct specialized ordered fields with the general spatial expansion strategies, and employ group attention mechanisms to extract the exclusive feature maps within each field. Subsequently, we integrate the feature representations across different ordered fields by alternately applying diverse expansion strategies, thereby enhancing the model's ability to capture comprehensive spatial information. The method was evaluated on the nuScenes lidar-based object detection test dataset, achieving an NDS score of 73.5 without Test-Time Augmentation (TTA) and 74.2 with TTA, demonstrating the effectiveness of the proposed method.
LTOS: Layout-controllable Text-Object Synthesis via Adaptive Cross-attention Fusions
Apr 21, 2024



Controllable text-to-image generation synthesizes visual text and objects in images with certain conditions, which are frequently applied to emoji and poster generation. Visual text rendering and layout-to-image generation tasks have been popular in controllable text-to-image generation. However, each of these tasks typically focuses on single modality generation or rendering, leaving yet-to-be-bridged gaps between the approaches correspondingly designed for each of the tasks. In this paper, we combine text rendering and layout-to-image generation tasks into a single task: layout-controllable text-object synthesis (LTOS) task, aiming at synthesizing images with object and visual text based on predefined object layout and text contents. As compliant datasets are not readily available for our LTOS task, we construct a layout-aware text-object synthesis dataset, containing elaborate well-aligned labels of visual text and object information. Based on the dataset, we propose a layout-controllable text-object adaptive fusion (TOF) framework, which generates images with clear, legible visual text and plausible objects. We construct a visual-text rendering module to synthesize text and employ an object-layout control module to generate objects while integrating the two modules to harmoniously generate and integrate text content and objects in images. To better the image-text integration, we propose a self-adaptive cross-attention fusion module that helps the image generation to attend more to important text information. Within such a fusion module, we use a self-adaptive learnable factor to learn to flexibly control the influence of cross-attention outputs on image generation. Experimental results show that our method outperforms the state-of-the-art in LTOS, text rendering, and layout-to-image tasks, enabling harmonious visual text rendering and object generation.