 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKlear-AgentForge: Forging Agentic Intelligence through Posttraining Scaling
Nov 08, 2025



Despite the proliferation of powerful agentic models, the lack of critical post-training details hinders the development of strong counterparts in the open-source community. In this study, we present a comprehensive and fully open-source pipeline for training a high-performance agentic model for interacting with external tools and environments, named Klear-Qwen3-AgentForge, starting from the Qwen3-8B base model. We design effective supervised fine-tuning (SFT) with synthetic data followed by multi-turn reinforcement learning (RL) to unlock the potential for multiple diverse agentic tasks. We perform exclusive experiments on various agentic benchmarks in both tool use and coding domains. Klear-Qwen3-AgentForge-8B achieves state-of-the-art performance among LLMs of similar size and remains competitive with significantly larger models.
DynTok: Dynamic Compression of Visual Tokens for Efficient and Effective Video Understanding
Jun 04, 2025Typical video modeling methods, such as LLava, represent videos as sequences of visual tokens, which are then processed by the LLM backbone for effective video understanding. However, this approach leads to a massive number of visual tokens, especially for long videos. A practical solution is to first extract relevant visual information from the large visual context before feeding it into the LLM backbone, thereby reducing computational overhead. In this work, we introduce DynTok, a novel \textbf{Dyn}amic video \textbf{Tok}en compression strategy. DynTok adaptively splits visual tokens into groups and merges them within each group, achieving high compression in regions with low information density while preserving essential content. Our method reduces the number of tokens to 44.4% of the original size while maintaining comparable performance. It further benefits from increasing the number of video frames and achieves 65.3% on Video-MME and 72.5% on MLVU. By applying this simple yet effective compression method, we expose the redundancy in video token representations and offer insights for designing more efficient video modeling techniques.
TUNA: Comprehensive Fine-grained Temporal Understanding Evaluation on Dense Dynamic Videos
May 26, 2025Videos are unique in their integration of temporal elements, including camera, scene, action, and attribute, along with their dynamic relationships over time. However, existing benchmarks for video understanding often treat these properties separately or narrowly focus on specific aspects, overlooking the holistic nature of video content. To address this, we introduce TUNA, a temporal-oriented benchmark for fine-grained understanding on dense dynamic videos, with two complementary tasks: captioning and QA. Our TUNA features diverse video scenarios and dynamics, assisted by interpretable and robust evaluation criteria. We evaluate several leading models on our benchmark, providing fine-grained performance assessments across various dimensions. This evaluation reveals key challenges in video temporal understanding, such as limited action description, inadequate multi-subject understanding, and insensitivity to camera motion, offering valuable insights for improving video understanding models. The data and code are available at https://friedrichor.github.io/projects/TUNA.
Leanabell-Prover: Posttraining Scaling in Formal Reasoning
Apr 09, 2025Recent advances in automated theorem proving (ATP) through LLMs have highlighted the potential of formal reasoning with Lean 4 codes. However, ATP has not yet be revolutionized by the recent posttraining scaling as demonstrated by Open AI O1/O3 and Deepseek R1. In this work, we investigate the entire posttraining of ATP, aiming to align it with breakthroughs in reasoning models in natural languages. To begin, we continual train current ATP models with a hybrid dataset, which consists of numerous statement-proof pairs, and additional data aimed at incorporating cognitive behaviors that emulate human reasoning and hypothesis refinement. Next, we explore reinforcement learning with the use of outcome reward returned by Lean 4 compiler. Through our designed continual training and reinforcement learning processes, we have successfully improved existing formal provers, including both DeepSeek-Prover-v1.5 and Goedel-Prover, achieving state-of-the-art performance in the field of whole-proof generation. For example, we achieve a 59.8% pass rate (pass@32) on MiniF2F. This is an on-going project and we will progressively update our findings, release our data and training details.
KNPTC: Knowledge and Neural Machine Translation Powered Chinese Pinyin Typo Correction
May 02, 2018
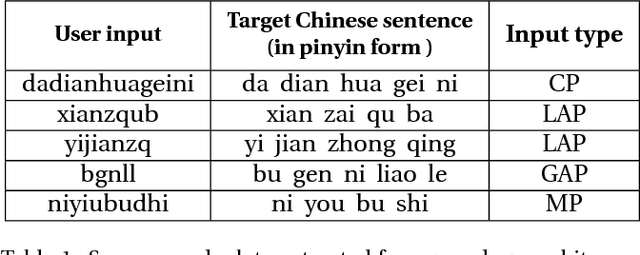
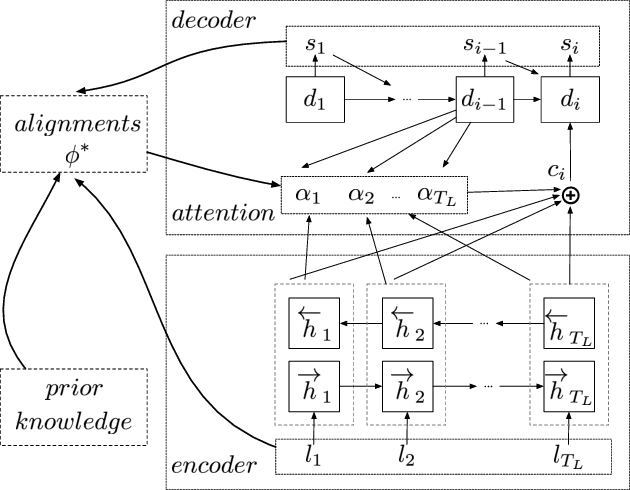
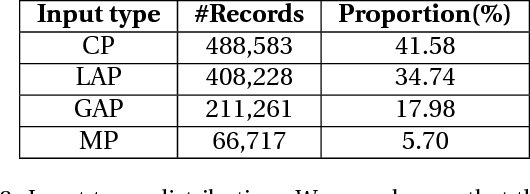
Chinese pinyin input methods are very important for Chinese language processing. Actually, users may make typos inevitably when they input pinyin. Moreover, pinyin typo correction has become an increasingly important task with the popularity of smartphones and the mobile Internet. How to exploit the knowledge of users typing behaviors and support the typo correction for acronym pinyin remains a challenging problem. To tackle these challenges, we propose KNPTC, a novel approach based on neural machine translation (NMT). In contrast to previous work, KNPTC is able to integrate explicit knowledge into NMT for pinyin typo correction, and is able to learn to correct a variety of typos without the guidance of manually selected constraints or languagespecific features. In this approach, we first obtain the transition probabilities between adjacent letters based on large-scale real-life datasets. Then, we construct the "ground-truth" alignments of training sentence pairs by utilizing these probabilities. Furthermore, these alignments are integrated into NMT to capture sensible pinyin typo correction patterns. KNPTC is applied to correct typos in real-life datasets, which achieves 32.77% increment on average in accuracy rate of typo correction compared against the state-of-the-art system.