 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruct-Imagen: Image Generation with Multi-modal Instruction
Jan 03, 2024



This paper presents instruct-imagen, a model that tackles heterogeneous image generation tasks and generalizes across unseen tasks. We introduce *multi-modal instruction* for image generation, a task representation articulating a range of generation intents with precision. It uses natural language to amalgamate disparate modalities (e.g., text, edge, style, subject, etc.), such that abundant generation intents can be standardized in a uniform format. We then build instruct-imagen by fine-tuning a pre-trained text-to-image diffusion model with a two-stage framework. First, we adapt the model using the retrieval-augmented training, to enhance model's capabilities to ground its generation on external multimodal context. Subsequently, we fine-tune the adapted model on diverse image generation tasks that requires vision-language understanding (e.g., subject-driven generation, etc.), each paired with a multi-modal instruction encapsulating the task's essence. Human evaluation on various image generation datasets reveals that instruct-imagen matches or surpasses prior task-specific models in-domain and demonstrates promising generalization to unseen and more complex tasks.
Pre-computed memory or on-the-fly encoding? A hybrid approach to retrieval augmentation makes the most of your compute
Jan 25, 2023



Retrieval-augmented language models such as Fusion-in-Decoder are powerful, setting the state of the art on a variety of knowledge-intensive tasks. However, they are also expensive, due to the need to encode a large number of retrieved passages. Some work avoids this cost by pre-encoding a text corpus into a memory and retrieving dense representations directly. However, pre-encoding memory incurs a severe quality penalty as the memory representations are not conditioned on the current input. We propose LUMEN, a hybrid between these two extremes, pre-computing the majority of the retrieval representation and completing the encoding on the fly using a live encoder that is conditioned on the question and fine-tuned for the task. We show that LUMEN significantly outperforms pure memory on multiple question-answering tasks while being much cheaper than FiD, and outperforms both for any given compute budget. Moreover, the advantage of LUMEN over FiD increases with model size.
FiDO: Fusion-in-Decoder optimized for stronger performance and faster inference
Dec 15, 2022



Fusion-in-Decoder (FiD) is a powerful retrieval-augmented language model that sets the state-of-the-art on many knowledge-intensive NLP tasks. However, FiD suffers from very expensive inference. We show that the majority of inference time results from memory bandwidth constraints in the decoder, and propose two simple changes to the FiD architecture to speed up inference by 7x. The faster decoder inference then allows for a much larger decoder. We denote FiD with the above modifications as FiDO, and show that it strongly improves performance over existing FiD models for a wide range of inference budgets. For example, FiDO-Large-XXL performs faster inference than FiD-Base and achieves better performance than FiD-Large.
Augmenting Pre-trained Language Models with QA-Memory for Open-Domain Question Answering
Apr 10, 2022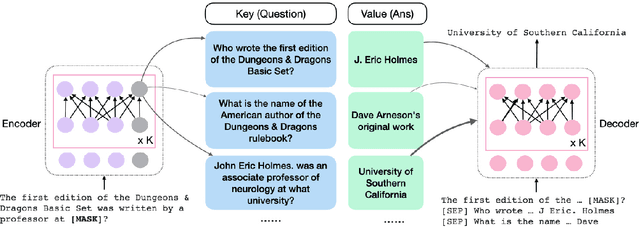
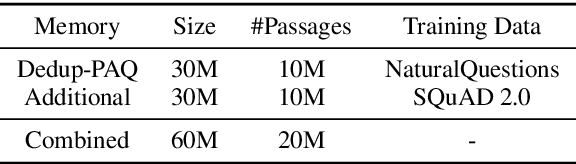
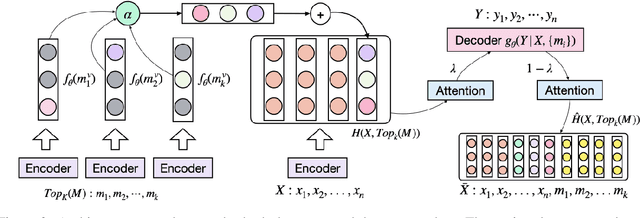
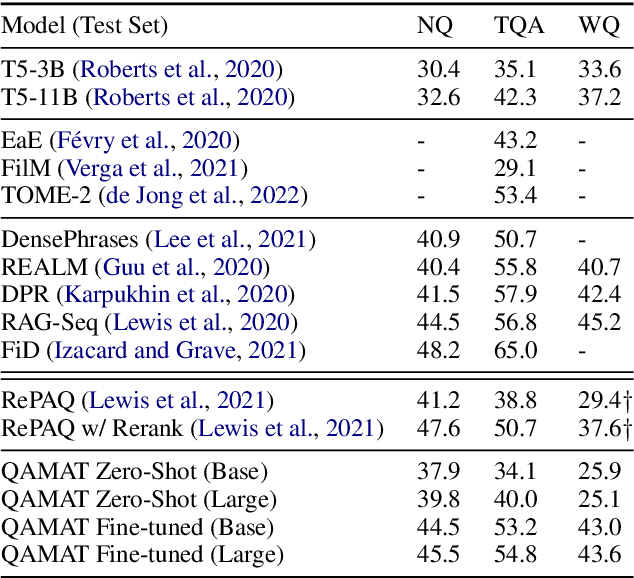
Retrieval augmented language models have recently become the standard for knowledge intensive tasks. Rather than relying purely on latent semantics within the parameters of large neural models, these methods enlist a semi-parametric memory to encode an index of knowledge for the model to retrieve over. Most prior work has employed text passages as the unit of knowledge, which has high coverage at the cost of interpretability, controllability, and efficiency. The opposite properties arise in other methods which have instead relied on knowledge base (KB) facts. At the same time, more recent work has demonstrated the effectiveness of storing and retrieving from an index of Q-A pairs derived from text \citep{lewis2021paq}. This approach yields a high coverage knowledge representation that maintains KB-like properties due to its representations being more atomic units of information. In this work we push this line of research further by proposing a question-answer augmented encoder-decoder model and accompanying pretraining strategy. This yields an end-to-end system that not only outperforms prior QA retrieval methods on single-hop QA tasks but also enables compositional reasoning, as demonstrated by strong performance on two multi-hop QA datasets. Together, these methods improve the ability to interpret and control the model while narrowing the performance gap with passage retrieval systems.
Mention Memory: incorporating textual knowledge into Transformers through entity mention attention
Oct 12, 2021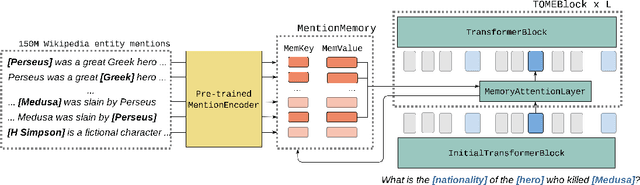
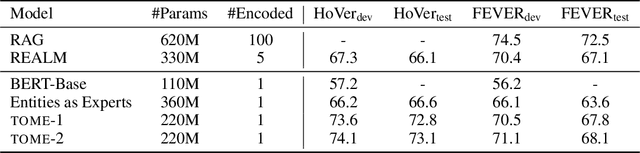
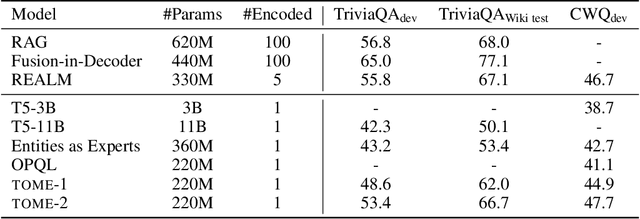
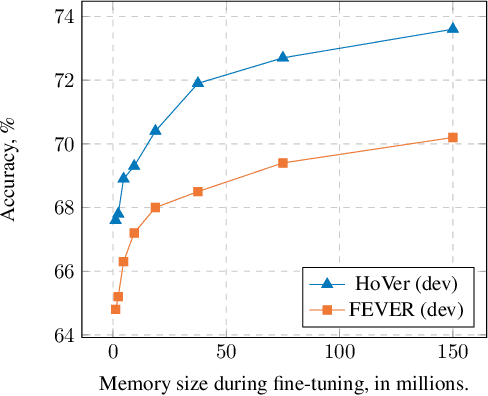
Natural language understanding tasks such as open-domain question answering often require retrieving and assimilating factual information from multiple sources. We propose to address this problem by integrating a semi-parametric representation of a large text corpus into a Transformer model as a source of factual knowledge. Specifically, our method represents knowledge with `mention memory', a table of dense vector representations of every entity mention in a corpus. The proposed model - TOME - is a Transformer that accesses the information through internal memory layers in which each entity mention in the input passage attends to the mention memory. This approach enables synthesis of and reasoning over many disparate sources of information within a single Transformer model. In experiments using a memory of 150 million Wikipedia mentions, TOME achieves strong performance on several open-domain knowledge-intensive tasks, including the claim verification benchmarks HoVer and FEVER and several entity-based QA benchmarks. We also show that the model learns to attend to informative mentions without any direct supervision. Finally we demonstrate that the model can generalize to new unseen entities by updating the memory without retraining.
Explainable Entity-based Recommendations with Knowledge Graphs
Jul 12, 2017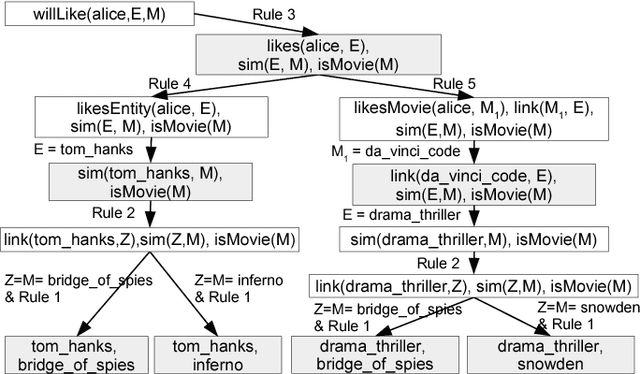
Explainable recommendation is an important task. Many methods have been proposed which generate explanations from the content and reviews written for items. When review text is unavailable, generating explanations is still a hard problem. In this paper, we illustrate how explanations can be generated in such a scenario by leveraging external knowledge in the form of knowledge graphs. Our method jointly ranks items and knowledge graph entities using a Personalized PageRank procedure to produce recommendations together with their explanations.
TransNets: Learning to Transform for Recommendation
Jun 30, 2017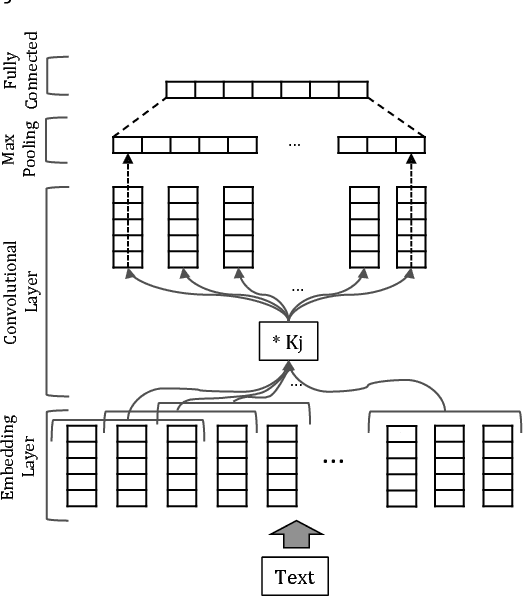
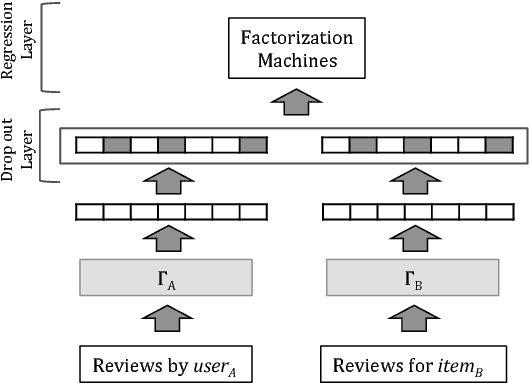
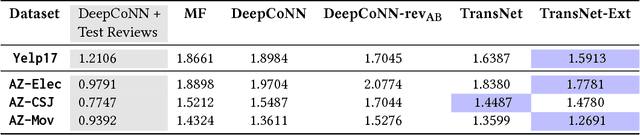
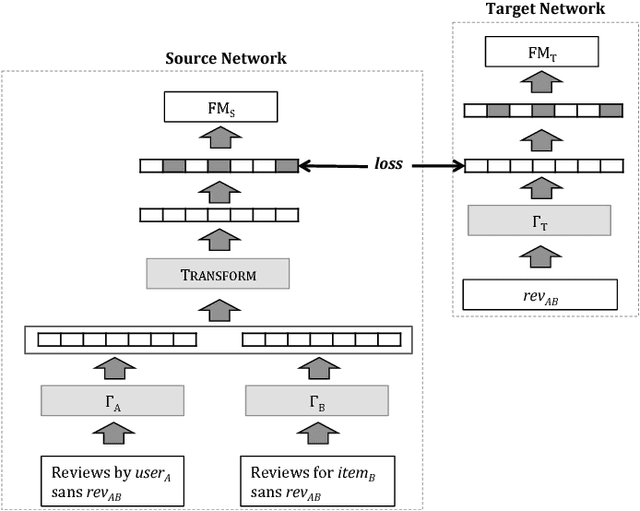
Recently, deep learning methods have been shown to improve the performance of recommender systems over traditional methods, especially when review text is available. For example, a recent model, DeepCoNN, uses neural nets to learn one latent representation for the text of all reviews written by a target user, and a second latent representation for the text of all reviews for a target item, and then combines these latent representations to obtain state-of-the-art performance on recommendation tasks. We show that (unsurprisingly) much of the predictive value of review text comes from reviews of the target user for the target item. We then introduce a way in which this information can be used in recommendation, even when the target user's review for the target item is not available. Our model, called TransNets, extends the DeepCoNN model by introducing an additional latent layer representing the target user-target item pair. We then regularize this layer, at training time, to be similar to another latent representation of the target user's review of the target item. We show that TransNets and extensions of it improve substantially over the previous state-of-the-art.
Multi-Task Cross-Lingual Sequence Tagging from Scratch
Aug 09, 2016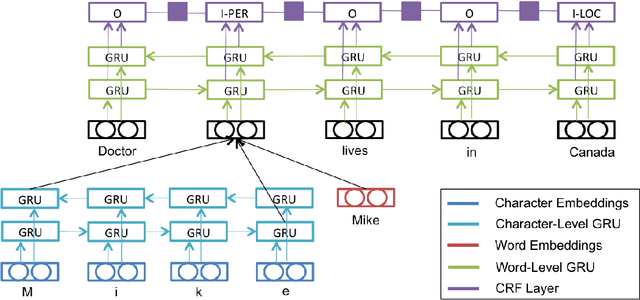

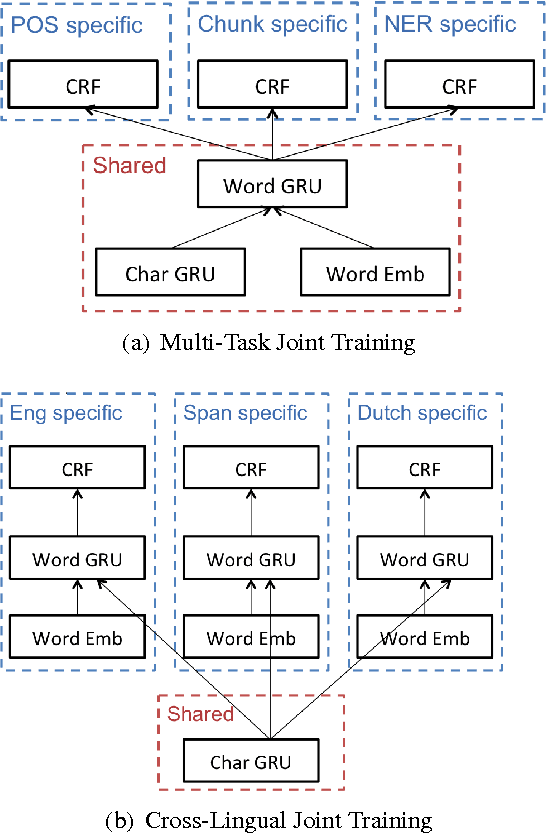
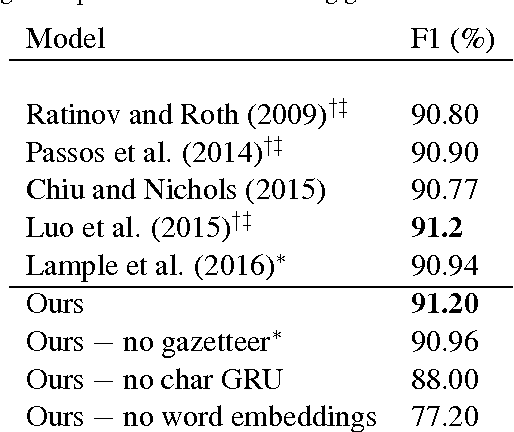
We present a deep hierarchical recurrent neural network for sequence tagging. Given a sequence of words, our model employs deep gated recurrent units on both character and word levels to encode morphology and context information, and applies a conditional random field layer to predict the tags. Our model is task independent, language independent, and feature engineering free. We further extend our model to multi-task and cross-lingual joint training by sharing the architecture and parameters. Our model achieves state-of-the-art results in multiple languages on several benchmark tasks including POS tagging, chunking, and NER. We also demonstrate that multi-task and cross-lingual joint training can improve the performance in various cases.
Multi-Modal Bayesian Embeddings for Learning Social Knowledge Graphs
Apr 20, 2016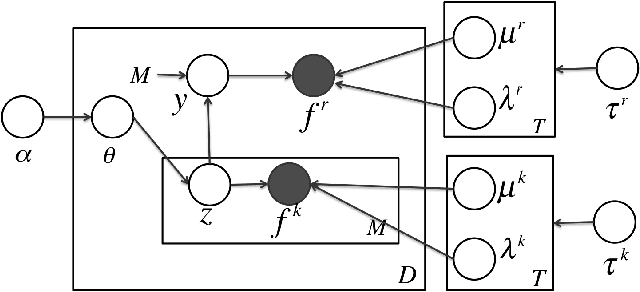

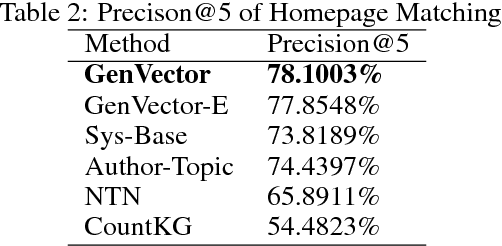
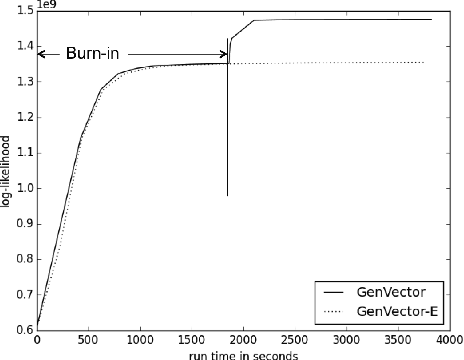
We study the extent to which online social networks can be connected to open knowledge bases. The problem is referred to as learning social knowledge graphs. We propose a multi-modal Bayesian embedding model, GenVector, to learn latent topics that generate word and network embeddings. GenVector leverages large-scale unlabeled data with embeddings and represents data of two modalities---i.e., social network users and knowledge concepts---in a shared latent topic space. Experiments on three datasets show that the proposed method clearly outperforms state-of-the-art methods. We then deploy the method on AMiner, a large-scale online academic search system with a network of 38,049,189 researchers with a knowledge base with 35,415,011 concepts. Our method significantly decreases the error rate in an online A/B test with live users.
Scaling Graph-based Semi Supervised Learning to Large Number of Labels Using Count-Min Sketch
Feb 27, 2014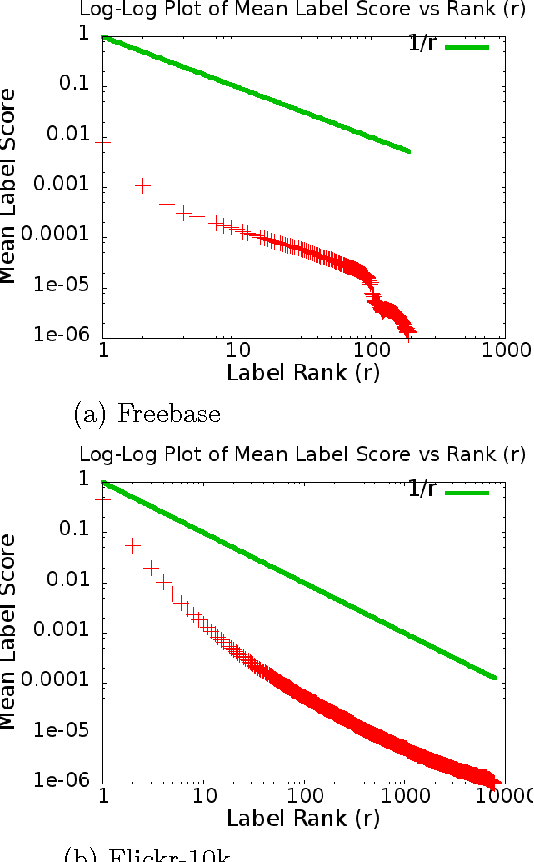

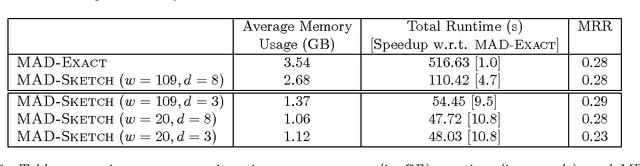
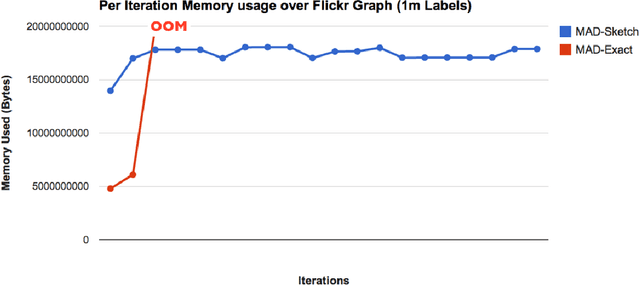
Graph-based Semi-supervised learning (SSL) algorithms have been successfully used in a large number of applications. These methods classify initially unlabeled nodes by propagating label information over the structure of graph starting from seed nodes. Graph-based SSL algorithms usually scale linearly with the number of distinct labels (m), and require O(m) space on each node. Unfortunately, there exist many applications of practical significance with very large m over large graphs, demanding better space and time complexity. In this paper, we propose MAD-SKETCH, a novel graph-based SSL algorithm which compactly stores label distribution on each node using Count-min Sketch, a randomized data structure. We present theoretical analysis showing that under mild conditions, MAD-SKETCH can reduce space complexity at each node from O(m) to O(log m), and achieve similar savings in time complexity as well. We support our analysis through experiments on multiple real world datasets. We observe that MAD-SKETCH achieves similar performance as existing state-of-the-art graph- based SSL algorithms, while requiring smaller memory footprint and at the same time achieving up to 10x speedup. We find that MAD-SKETCH is able to scale to datasets with one million labels, which is beyond the scope of existing graph- based SSL algorithms.