 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Manipulate Anything: Revealing Data Scaling Laws in Bounding-Box Guided Policies
Feb 12, 2026Diffusion-based policies show limited generalization in semantic manipulation, posing a key obstacle to the deployment of real-world robots. This limitation arises because relying solely on text instructions is inadequate to direct the policy's attention toward the target object in complex and dynamic environments. To solve this problem, we propose leveraging bounding-box instruction to directly specify target object, and further investigate whether data scaling laws exist in semantic manipulation tasks. Specifically, we design a handheld segmentation device with an automated annotation pipeline, Label-UMI, which enables the efficient collection of demonstration data with semantic labels. We further propose a semantic-motion-decoupled framework that integrates object detection and bounding-box guided diffusion policy to improve generalization and adaptability in semantic manipulation. Throughout extensive real-world experiments on large-scale datasets, we validate the effectiveness of the approach, and reveal a power-law relationship between generalization performance and the number of bounding-box objects. Finally, we summarize an effective data collection strategy for semantic manipulation, which can achieve 85\% success rates across four tasks on both seen and unseen objects. All datasets and code will be released to the community.
AirHunt: Bridging VLM Semantics and Continuous Planning for Efficient Aerial Object Navigation
Jan 19, 2026Recent advances in large Vision-Language Models (VLMs) have provided rich semantic understanding that empowers drones to search for open-set objects via natural language instructions. However, prior systems struggle to integrate VLMs into practical aerial systems due to orders-of-magnitude frequency mismatch between VLM inference and real-time planning, as well as VLMs' limited 3D scene understanding. They also lack a unified mechanism to balance semantic guidance with motion efficiency in large-scale environments. To address these challenges, we present AirHunt, an aerial object navigation system that efficiently locates open-set objects with zero-shot generalization in outdoor environments by seamlessly fusing VLM semantic reasoning with continuous path planning. AirHunt features a dual-pathway asynchronous architecture that establishes a synergistic interface between VLM reasoning and path planning, enabling continuous flight with adaptive semantic guidance that evolves through motion. Moreover, we propose an active dual-task reasoning module that exploits geometric and semantic redundancy to enable selective VLM querying, and a semantic-geometric coherent planning module that dynamically reconciles semantic priorities and motion efficiency in a unified framework, enabling seamless adaptation to environmental heterogeneity. We evaluate AirHunt across diverse object navigation tasks and environments, demonstrating a higher success rate with lower navigation error and reduced flight time compared to state-of-the-art methods. Real-world experiments further validate AirHunt's practical capability in complex and challenging environments. Code and dataset will be made publicly available before publication.
CausalNav: A Long-term Embodied Navigation System for Autonomous Mobile Robots in Dynamic Outdoor Scenarios
Jan 05, 2026Autonomous language-guided navigation in large-scale outdoor environments remains a key challenge in mobile robotics, due to difficulties in semantic reasoning, dynamic conditions, and long-term stability. We propose CausalNav, the first scene graph-based semantic navigation framework tailored for dynamic outdoor environments. We construct a multi-level semantic scene graph using LLMs, referred to as the Embodied Graph, that hierarchically integrates coarse-grained map data with fine-grained object entities. The constructed graph serves as a retrievable knowledge base for Retrieval-Augmented Generation (RAG), enabling semantic navigation and long-range planning under open-vocabulary queries. By fusing real-time perception with offline map data, the Embodied Graph supports robust navigation across varying spatial granularities in dynamic outdoor environments. Dynamic objects are explicitly handled in both the scene graph construction and hierarchical planning modules. The Embodied Graph is continuously updated within a temporal window to reflect environmental changes and support real-time semantic navigation. Extensive experiments in both simulation and real-world settings demonstrate superior robustness and efficiency.
No Cache Left Idle: Accelerating diffusion model via Extreme-slimming Caching
Dec 14, 2025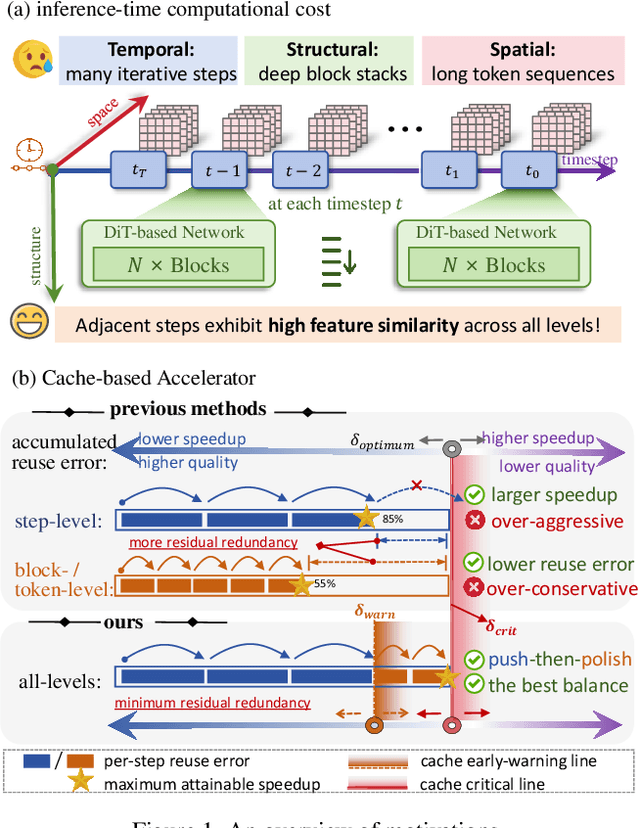
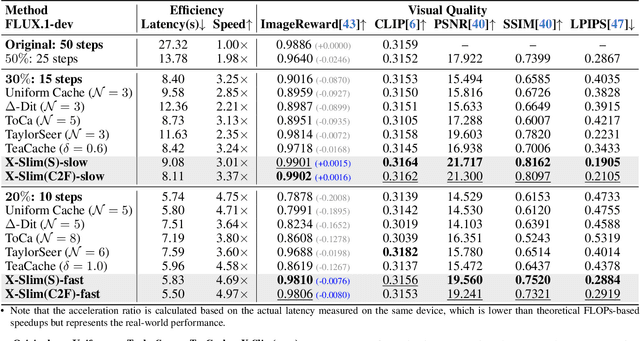
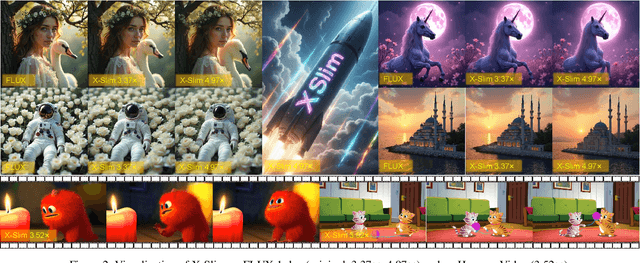
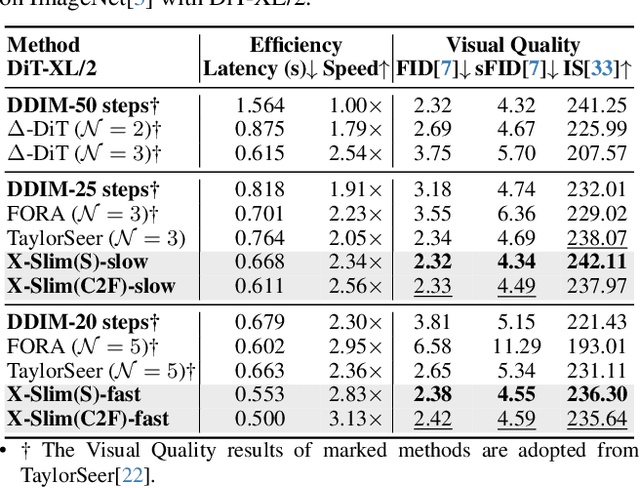
Diffusion models achieve remarkable generative quality, but computational overhead scales with step count, model depth, and sequence length. Feature caching is effective since adjacent timesteps yield highly similar features. However, an inherent trade-off remains: aggressive timestep reuse offers large speedups but can easily cross the critical line, hurting fidelity, while block- or token-level reuse is safer but yields limited computational savings. We present X-Slim (eXtreme-Slimming Caching), a training-free, cache-based accelerator that, to our knowledge, is the first unified framework to exploit cacheable redundancy across timesteps, structure (blocks), and space (tokens). Rather than simply mixing levels, X-Slim introduces a dual-threshold controller that turns caching into a push-then-polish process: it first pushes reuse at the timestep level up to an early-warning line, then switches to lightweight block- and token-level refresh to polish the remaining redundancy, and triggers full inference once the critical line is crossed to reset accumulated error. At each level, context-aware indicators decide when and where to cache. Across diverse tasks, X-Slim advances the speed-quality frontier. On FLUX.1-dev and HunyuanVideo, it reduces latency by up to 4.97x and 3.52x with minimal perceptual loss. On DiT-XL/2, it reaches 3.13x acceleration and improves FID by 2.42 over prior methods.
UACER: An Uncertainty-Aware Critic Ensemble Framework for Robust Adversarial Reinforcement Learning
Dec 11, 2025Robust adversarial reinforcement learning has emerged as an effective paradigm for training agents to handle uncertain disturbance in real environments, with critical applications in sequential decision-making domains such as autonomous driving and robotic control. Within this paradigm, agent training is typically formulated as a zero-sum Markov game between a protagonist and an adversary to enhance policy robustness. However, the trainable nature of the adversary inevitably induces non-stationarity in the learning dynamics, leading to exacerbated training instability and convergence difficulties, particularly in high-dimensional complex environments. In this paper, we propose a novel approach, Uncertainty-Aware Critic Ensemble for robust adversarial Reinforcement learning (UACER), which consists of two strategies: 1) Diversified critic ensemble: a diverse set of K critic networks is exploited in parallel to stabilize Q-value estimation rather than conventional single-critic architectures for both variance reduction and robustness enhancement. 2) Time-varying Decay Uncertainty (TDU) mechanism: advancing beyond simple linear combinations, we develop a variance-derived Q-value aggregation strategy that explicitly incorporates epistemic uncertainty to dynamically regulate the exploration-exploitation trade-off while simultaneously stabilizing the training process. Comprehensive experiments across several MuJoCo control problems validate the superior effectiveness of UACER, outperforming state-of-the-art methods in terms of overall performance, stability, and efficiency.
Count Every Rotation and Every Rotation Counts: Exploring Drone Dynamics via Propeller Sensing
Nov 17, 2025As drone-based applications proliferate, paramount contactless sensing of airborne drones from the ground becomes indispensable. This work demonstrates concentrating on propeller rotational speed will substantially improve drone sensing performance and proposes an event-camera-based solution, \sysname. \sysname features two components: \textit{Count Every Rotation} achieves accurate, real-time propeller speed estimation by mitigating ultra-high sensitivity of event cameras to environmental noise. \textit{Every Rotation Counts} leverages these speeds to infer both internal and external drone dynamics. Extensive evaluations in real-world drone delivery scenarios show that \sysname achieves a sensing latency of 3$ms$ and a rotational speed estimation error of merely 0.23\%. Additionally, \sysname infers drone flight commands with 96.5\% precision and improves drone tracking accuracy by over 22\% when combined with other sensing modalities. \textit{ Demo: {\color{blue}https://eventpro25.github.io/EventPro/.} }
Sample By Step, Optimize By Chunk: Chunk-Level GRPO For Text-to-Image Generation
Oct 24, 2025



Group Relative Policy Optimization (GRPO) has shown strong potential for flow-matching-based text-to-image (T2I) generation, but it faces two key limitations: inaccurate advantage attribution, and the neglect of temporal dynamics of generation. In this work, we argue that shifting the optimization paradigm from the step level to the chunk level can effectively alleviate these issues. Building on this idea, we propose Chunk-GRPO, the first chunk-level GRPO-based approach for T2I generation. The insight is to group consecutive steps into coherent 'chunk's that capture the intrinsic temporal dynamics of flow matching, and to optimize policies at the chunk level. In addition, we introduce an optional weighted sampling strategy to further enhance performance. Extensive experiments show that ChunkGRPO achieves superior results in both preference alignment and image quality, highlighting the promise of chunk-level optimization for GRPO-based methods.
A Hybrid Force-Position Strategy for Shape Control of Deformable Linear Objects With Graph Attention Networks
Aug 10, 2025Manipulating deformable linear objects (DLOs) such as wires and cables is crucial in various applications like electronics assembly and medical surgeries. However, it faces challenges due to DLOs' infinite degrees of freedom, complex nonlinear dynamics, and the underactuated nature of the system. To address these issues, this paper proposes a hybrid force-position strategy for DLO shape control. The framework, combining both force and position representations of DLO, integrates state trajectory planning in the force space and Model Predictive Control (MPC) in the position space. We present a dynamics model with an explicit action encoder, a property extractor and a graph processor based on Graph Attention Networks. The model is used in the MPC to enhance prediction accuracy. Results from both simulations and real-world experiments demonstrate the effectiveness of our approach in achieving efficient and stable shape control of DLOs. Codes and videos are available at https://sites.google.com/view/dlom.
Mastering Massive Multi-Task Reinforcement Learning via Mixture-of-Expert Decision Transformer
May 30, 2025Despite recent advancements in offline multi-task reinforcement learning (MTRL) have harnessed the powerful capabilities of the Transformer architecture, most approaches focus on a limited number of tasks, with scaling to extremely massive tasks remaining a formidable challenge. In this paper, we first revisit the key impact of task numbers on current MTRL method, and further reveal that naively expanding the parameters proves insufficient to counteract the performance degradation as the number of tasks escalates. Building upon these insights, we propose M3DT, a novel mixture-of-experts (MoE) framework that tackles task scalability by further unlocking the model's parameter scalability. Specifically, we enhance both the architecture and the optimization of the agent, where we strengthen the Decision Transformer (DT) backbone with MoE to reduce task load on parameter subsets, and introduce a three-stage training mechanism to facilitate efficient training with optimal performance. Experimental results show that, by increasing the number of experts, M3DT not only consistently enhances its performance as model expansion on the fixed task numbers, but also exhibits remarkable task scalability, successfully extending to 160 tasks with superior performance.
Lifelong Safety Alignment for Language Models
May 26, 2025



LLMs have made impressive progress, but their growing capabilities also expose them to highly flexible jailbreaking attacks designed to bypass safety alignment. While many existing defenses focus on known types of attacks, it is more critical to prepare LLMs for unseen attacks that may arise during deployment. To address this, we propose a lifelong safety alignment framework that enables LLMs to continuously adapt to new and evolving jailbreaking strategies. Our framework introduces a competitive setup between two components: a Meta-Attacker, trained to actively discover novel jailbreaking strategies, and a Defender, trained to resist them. To effectively warm up the Meta-Attacker, we first leverage the GPT-4o API to extract key insights from a large collection of jailbreak-related research papers. Through iterative training, the first iteration Meta-Attacker achieves a 73% attack success rate (ASR) on RR and a 57% transfer ASR on LAT using only single-turn attacks. Meanwhile, the Defender progressively improves its robustness and ultimately reduces the Meta-Attacker's success rate to just 7%, enabling safer and more reliable deployment of LLMs in open-ended environments. The code is available at https://github.com/sail-sg/LifelongSafetyAlignment.