 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Capacity: Evaluating the Efficiency of Large Language Models via Text Compression
Nov 13, 2025Recent years have witnessed the rapid advancements of large language models (LLMs) and their expanding applications, leading to soaring demands for computational resources. The widespread adoption of test-time scaling further aggravates the tension between model capability and resource consumption, highlighting the importance of inference efficiency. However, a unified metric that accurately reflects an LLM's efficiency across different model sizes and architectures remains absent. Motivated by the correlation between compression and intelligence, we introduce information capacity, a measure of model efficiency based on text compression performance relative to computational complexity. Larger models can predict the next token more accurately, achieving greater compression gains but at higher computational costs. Empirical evaluations on mainstream open-source models show that models of varying sizes within a series exhibit consistent information capacity. This metric enables a fair efficiency comparison across model series and accurate performance prediction within a model series. A distinctive feature of information capacity is that it incorporates tokenizer efficiency, which affects both input and output token counts but is often neglected in LLM evaluations. We assess the information capacity of 49 models on 5 heterogeneous datasets and observe consistent results on the influences of tokenizer efficiency, pretraining data, and the mixture-of-experts architecture.
Exploring the Underwater World Segmentation without Extra Training
Nov 11, 2025Accurate segmentation of marine organisms is vital for biodiversity monitoring and ecological assessment, yet existing datasets and models remain largely limited to terrestrial scenes. To bridge this gap, we introduce \textbf{AquaOV255}, the first large-scale and fine-grained underwater segmentation dataset containing 255 categories and over 20K images, covering diverse categories for open-vocabulary (OV) evaluation. Furthermore, we establish the first underwater OV segmentation benchmark, \textbf{UOVSBench}, by integrating AquaOV255 with five additional underwater datasets to enable comprehensive evaluation. Alongside, we present \textbf{Earth2Ocean}, a training-free OV segmentation framework that transfers terrestrial vision--language models (VLMs) to underwater domains without any additional underwater training. Earth2Ocean consists of two core components: a Geometric-guided Visual Mask Generator (\textbf{GMG}) that refines visual features via self-similarity geometric priors for local structure perception, and a Category-visual Semantic Alignment (\textbf{CSA}) module that enhances text embeddings through multimodal large language model reasoning and scene-aware template construction. Extensive experiments on the UOVSBench benchmark demonstrate that Earth2Ocean achieves significant performance improvement on average while maintaining efficient inference.
ScRPO: From Errors to Insights
Nov 11, 2025We propose Self-correction Relative Policy Optimization (ScRPO), a novel reinforcement learning framework designed to enhance large language models on challenging mathematical problems by leveraging self-reflection and error correction. Our approach consists of two stages: (1) Trial-and-error learning stage: training the model with GRPO and collecting incorrect answers along with their corresponding questions in an error pool; (2) Self-correction learning stage: guiding the model to reflect on why its previous answers were wrong. Extensive experiments across multiple math reasoning benchmarks, including AIME, AMC, Olympiad, MATH-500, GSM8k, using Deepseek-Distill-Qwen-1.5B and Deepseek-Distill-Qwen-7B. The experimental results demonstrate that ScRPO consistently outperforms several post-training methods. These findings highlight ScRPO as a promising paradigm for enabling language models to self-improve on difficult tasks with limited external feedback, paving the way toward more reliable and capable AI systems.
Class-Aware Prototype Learning with Negative Contrast for Test-Time Adaptation of Vision-Language Models
Oct 22, 2025Vision-Language Models (VLMs) demonstrate impressive zero-shot generalization through large-scale image-text pretraining, yet their performance can drop once the deployment distribution diverges from the training distribution. To address this, Test-Time Adaptation (TTA) methods update models using unlabeled target data. However, existing approaches often ignore two key challenges: prototype degradation in long-tailed distributions and confusion between semantically similar classes. To tackle these issues, we propose \textbf{C}lass-Aware \textbf{P}rototype \textbf{L}earning with \textbf{N}egative \textbf{C}ontrast(\textbf{CPL-NC}), a lightweight TTA framework designed specifically for VLMs to enhance generalization under distribution shifts. CPL-NC introduces a \textit{Class-Aware Prototype Cache} Module that dynamically adjusts per-class capacity based on test-time frequency and activation history, with a rejuvenation mechanism for inactive classes to retain rare-category knowledge. Additionally, a \textit{Negative Contrastive Learning} Mechanism identifies and constrains hard visual-textual negatives to improve class separability. The framework employs asymmetric optimization, refining only textual prototypes while anchoring on stable visual features. Experiments on 15 benchmarks show that CPL-NC consistently outperforms prior TTA methods across both ResNet-50 and ViT-B/16 backbones.
FastUMI-100K: Advancing Data-driven Robotic Manipulation with a Large-scale UMI-style Dataset
Oct 09, 2025Data-driven robotic manipulation learning depends on large-scale, high-quality expert demonstration datasets. However, existing datasets, which primarily rely on human teleoperated robot collection, are limited in terms of scalability, trajectory smoothness, and applicability across different robotic embodiments in real-world environments. In this paper, we present FastUMI-100K, a large-scale UMI-style multimodal demonstration dataset, designed to overcome these limitations and meet the growing complexity of real-world manipulation tasks. Collected by FastUMI, a novel robotic system featuring a modular, hardware-decoupled mechanical design and an integrated lightweight tracking system, FastUMI-100K offers a more scalable, flexible, and adaptable solution to fulfill the diverse requirements of real-world robot demonstration data. Specifically, FastUMI-100K contains over 100K+ demonstration trajectories collected across representative household environments, covering 54 tasks and hundreds of object types. Our dataset integrates multimodal streams, including end-effector states, multi-view wrist-mounted fisheye images and textual annotations. Each trajectory has a length ranging from 120 to 500 frames. Experimental results demonstrate that FastUMI-100K enables high policy success rates across various baseline algorithms, confirming its robustness, adaptability, and real-world applicability for solving complex, dynamic manipulation challenges. The source code and dataset will be released in this link https://github.com/MrKeee/FastUMI-100K.
Towards Reliable LLM-based Robot Planning via Combined Uncertainty Estimation
Oct 09, 2025



Large language models (LLMs) demonstrate advanced reasoning abilities, enabling robots to understand natural language instructions and generate high-level plans with appropriate grounding. However, LLM hallucinations present a significant challenge, often leading to overconfident yet potentially misaligned or unsafe plans. While researchers have explored uncertainty estimation to improve the reliability of LLM-based planning, existing studies have not sufficiently differentiated between epistemic and intrinsic uncertainty, limiting the effectiveness of uncertainty esti- mation. In this paper, we present Combined Uncertainty estimation for Reliable Embodied planning (CURE), which decomposes the uncertainty into epistemic and intrinsic uncertainty, each estimated separately. Furthermore, epistemic uncertainty is subdivided into task clarity and task familiarity for more accurate evaluation. The overall uncertainty assessments are obtained using random network distillation and multi-layer perceptron regression heads driven by LLM features. We validated our approach in two distinct experimental settings: kitchen manipulation and tabletop rearrangement experiments. The results show that, compared to existing methods, our approach yields uncertainty estimates that are more closely aligned with the actual execution outcomes.
T2R-bench: A Benchmark for Generating Article-Level Reports from Real World Industrial Tables
Aug 27, 2025Extensive research has been conducted to explore the capabilities of large language models (LLMs) in table reasoning. However, the essential task of transforming tables information into reports remains a significant challenge for industrial applications. This task is plagued by two critical issues: 1) the complexity and diversity of tables lead to suboptimal reasoning outcomes; and 2) existing table benchmarks lack the capacity to adequately assess the practical application of this task. To fill this gap, we propose the table-to-report task and construct a bilingual benchmark named T2R-bench, where the key information flow from the tables to the reports for this task. The benchmark comprises 457 industrial tables, all derived from real-world scenarios and encompassing 19 industry domains as well as 4 types of industrial tables. Furthermore, we propose an evaluation criteria to fairly measure the quality of report generation. The experiments on 25 widely-used LLMs reveal that even state-of-the-art models like Deepseek-R1 only achieves performance with 62.71 overall score, indicating that LLMs still have room for improvement on T2R-bench. Source code and data will be available after acceptance.
ERF-BA-TFD+: A Multimodal Model for Audio-Visual Deepfake Detection
Aug 24, 2025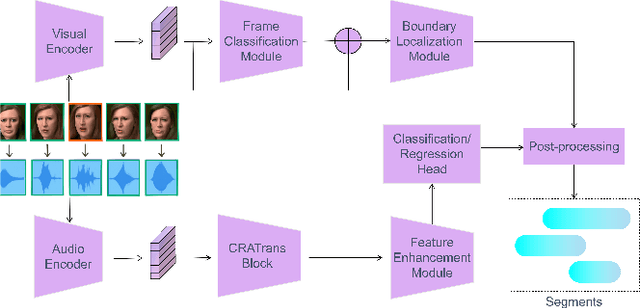
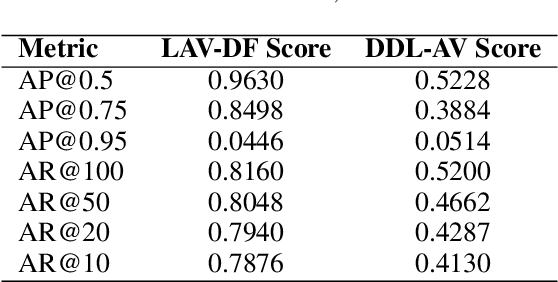
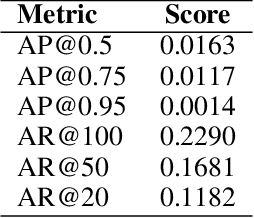
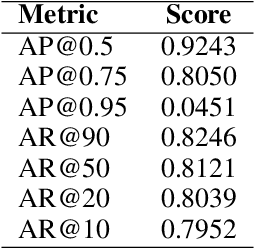
Deepfake detection is a critical task in identifying manipulated multimedia content. In real-world scenarios, deepfake content can manifest across multiple modalities, including audio and video. To address this challenge, we present ERF-BA-TFD+, a novel multimodal deepfake detection model that combines enhanced receptive field (ERF) and audio-visual fusion. Our model processes both audio and video features simultaneously, leveraging their complementary information to improve detection accuracy and robustness. The key innovation of ERF-BA-TFD+ lies in its ability to model long-range dependencies within the audio-visual input, allowing it to better capture subtle discrepancies between real and fake content. In our experiments, we evaluate ERF-BA-TFD+ on the DDL-AV dataset, which consists of both segmented and full-length video clips. Unlike previous benchmarks, which focused primarily on isolated segments, the DDL-AV dataset allows us to assess the model's performance in a more comprehensive and realistic setting. Our method achieves state-of-the-art results on this dataset, outperforming existing techniques in terms of both accuracy and processing speed. The ERF-BA-TFD+ model demonstrated its effectiveness in the "Workshop on Deepfake Detection, Localization, and Interpretability," Track 2: Audio-Visual Detection and Localization (DDL-AV), and won first place in this competition.
InterSyn: Interleaved Learning for Dynamic Motion Synthesis in the Wild
Aug 14, 2025We present Interleaved Learning for Motion Synthesis (InterSyn), a novel framework that targets the generation of realistic interaction motions by learning from integrated motions that consider both solo and multi-person dynamics. Unlike previous methods that treat these components separately, InterSyn employs an interleaved learning strategy to capture the natural, dynamic interactions and nuanced coordination inherent in real-world scenarios. Our framework comprises two key modules: the Interleaved Interaction Synthesis (INS) module, which jointly models solo and interactive behaviors in a unified paradigm from a first-person perspective to support multiple character interactions, and the Relative Coordination Refinement (REC) module, which refines mutual dynamics and ensures synchronized motions among characters. Experimental results show that the motion sequences generated by InterSyn exhibit higher text-to-motion alignment and improved diversity compared with recent methods, setting a new benchmark for robust and natural motion synthesis. Additionally, our code will be open-sourced in the future to promote further research and development in this area.
Safe Semantics, Unsafe Interpretations: Tackling Implicit Reasoning Safety in Large Vision-Language Models
Aug 12, 2025Large Vision-Language Models face growing safety challenges with multimodal inputs. This paper introduces the concept of Implicit Reasoning Safety, a vulnerability in LVLMs. Benign combined inputs trigger unsafe LVLM outputs due to flawed or hidden reasoning. To showcase this, we developed Safe Semantics, Unsafe Interpretations, the first dataset for this critical issue. Our demonstrations show that even simple In-Context Learning with SSUI significantly mitigates these implicit multimodal threats, underscoring the urgent need to improve cross-modal implicit reasoning.