 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2R-bench: A Benchmark for Generating Article-Level Reports from Real World Industrial Tables
Aug 27, 2025Extensive research has been conducted to explore the capabilities of large language models (LLMs) in table reasoning. However, the essential task of transforming tables information into reports remains a significant challenge for industrial applications. This task is plagued by two critical issues: 1) the complexity and diversity of tables lead to suboptimal reasoning outcomes; and 2) existing table benchmarks lack the capacity to adequately assess the practical application of this task. To fill this gap, we propose the table-to-report task and construct a bilingual benchmark named T2R-bench, where the key information flow from the tables to the reports for this task. The benchmark comprises 457 industrial tables, all derived from real-world scenarios and encompassing 19 industry domains as well as 4 types of industrial tables. Furthermore, we propose an evaluation criteria to fairly measure the quality of report generation. The experiments on 25 widely-used LLMs reveal that even state-of-the-art models like Deepseek-R1 only achieves performance with 62.71 overall score, indicating that LLMs still have room for improvement on T2R-bench. Source code and data will be available after acceptance.
Chain-of-Lure: A Synthetic Narrative-Driven Approach to Compromise Large Language Models
May 23, 2025In the era of rapid generative AI development, interactions between humans and large language models face significant misusing risks. Previous research has primarily focused on black-box scenarios using human-guided prompts and white-box scenarios leveraging gradient-based LLM generation methods, neglecting the possibility that LLMs can act not only as victim models, but also as attacker models to harm other models. We proposes a novel jailbreaking method inspired by the Chain-of-Thought mechanism, where the attacker model uses mission transfer to conceal harmful user intent in dialogue and generates chained narrative lures to stimulate the reasoning capabilities of victim models, leading to successful jailbreaking. To enhance the attack success rate, we introduce a helper model that performs random narrative optimization on the narrative lures during multi-turn dialogues while ensuring alignment with the original intent, enabling the optimized lures to bypass the safety barriers of victim models effectively. Our experiments reveal that models with weaker safety mechanisms exhibit stronger attack capabilities, demonstrating that models can not only be exploited, but also help harm others. By incorporating toxicity scores, we employ third-party models to evaluate the harmfulness of victim models' responses to jailbreaking attempts. The study shows that using refusal keywords as an evaluation metric for attack success rates is significantly flawed because it does not assess whether the responses guide harmful questions, while toxicity scores measure the harm of generated content with more precision and its alignment with harmful questions. Our approach demonstrates outstanding performance, uncovering latent vulnerabilities in LLMs and providing data-driven feedback to optimize LLM safety mechanisms. We also discuss two defensive strategies to offer guidance on improving defense mechanisms.
Large Language Models Merging for Enhancing the Link Stealing Attack on Graph Neural Networks
Dec 08, 2024



Graph Neural Networks (GNNs), specifically designed to process the graph data, have achieved remarkable success in various applications. Link stealing attacks on graph data pose a significant privacy threat, as attackers aim to extract sensitive relationships between nodes (entities), potentially leading to academic misconduct, fraudulent transactions, or other malicious activities. Previous studies have primarily focused on single datasets and did not explore cross-dataset attacks, let alone attacks that leverage the combined knowledge of multiple attackers. However, we find that an attacker can combine the data knowledge of multiple attackers to create a more effective attack model, which can be referred to cross-dataset attacks. Moreover, if knowledge can be extracted with the help of Large Language Models (LLMs), the attack capability will be more significant. In this paper, we propose a novel link stealing attack method that takes advantage of cross-dataset and Large Language Models (LLMs). The LLM is applied to process datasets with different data structures in cross-dataset attacks. Each attacker fine-tunes the LLM on their specific dataset to generate a tailored attack model. We then introduce a novel model merging method to integrate the parameters of these attacker-specific models effectively. The result is a merged attack model with superior generalization capabilities, enabling effective attacks not only on the attackers' datasets but also on previously unseen (out-of-domain) datasets. We conducted extensive experiments in four datasets to demonstrate the effectiveness of our method. Additional experiments with three different GNN and LLM architectures further illustrate the generality of our approach.
Zero-shot Class Unlearning via Layer-wise Relevance Analysis and Neuronal Path Perturbation
Oct 31, 2024In the rapid advancement of artificial intelligence, privacy protection has become crucial, giving rise to machine unlearning. Machine unlearning is a technique that removes specific data influences from trained models without the need for extensive retraining. However, it faces several key challenges, including accurately implementing unlearning, ensuring privacy protection during the unlearning process, and achieving effective unlearning without significantly compromising model performance. This paper presents a novel approach to machine unlearning by employing Layer-wise Relevance Analysis and Neuronal Path Perturbation. We address three primary challenges: the lack of detailed unlearning principles, privacy guarantees in zero-shot unlearning scenario, and the balance between unlearning effectiveness and model utility. Our method balances machine unlearning performance and model utility by identifying and perturbing highly relevant neurons, thereby achieving effective unlearning. By using data not present in the original training set during the unlearning process, we satisfy the zero-shot unlearning scenario and ensure robust privacy protection. Experimental results demonstrate that our approach effectively removes targeted data from the target unlearning model while maintaining the model's utility, offering a practical solution for privacy-preserving machine learning.
Class Machine Unlearning for Complex Data via Concepts Inference and Data Poisoning
May 24, 2024



In current AI era, users may request AI companies to delete their data from the training dataset due to the privacy concerns. As a model owner, retraining a model will consume significant computational resources. Therefore, machine unlearning is a new emerged technology to allow model owner to delete requested training data or a class with little affecting on the model performance. However, for large-scaling complex data, such as image or text data, unlearning a class from a model leads to a inferior performance due to the difficulty to identify the link between classes and model. An inaccurate class deleting may lead to over or under unlearning. In this paper, to accurately defining the unlearning class of complex data, we apply the definition of Concept, rather than an image feature or a token of text data, to represent the semantic information of unlearning class. This new representation can cut the link between the model and the class, leading to a complete erasing of the impact of a class. To analyze the impact of the concept of complex data, we adopt a Post-hoc Concept Bottleneck Model, and Integrated Gradients to precisely identify concepts across different classes. Next, we take advantage of data poisoning with random and targeted labels to propose unlearning methods. We test our methods on both image classification models and large language models (LLMs). The results consistently show that the proposed methods can accurately erase targeted information from models and can largely maintain the performance of the models.
Generative Adversarial Networks Unlearning
Aug 19, 2023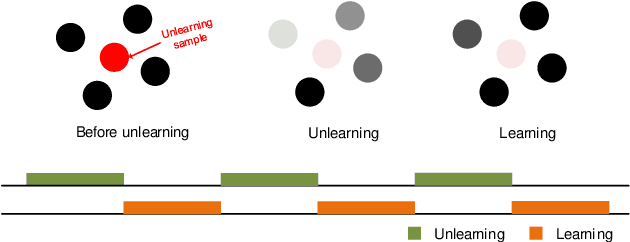

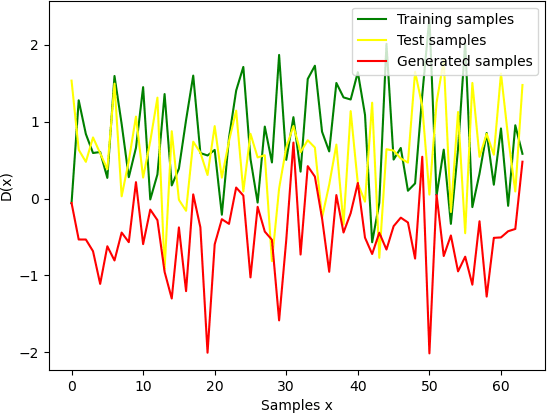
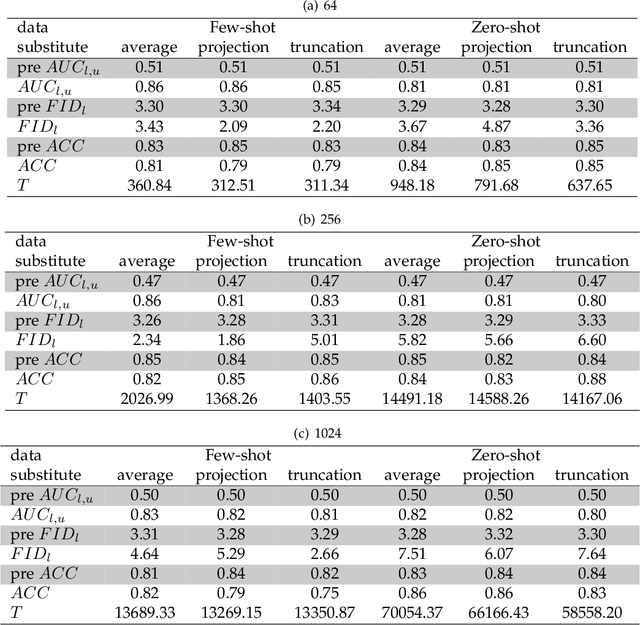
As machine learning continues to develop, and data misuse scandals become more prevalent, individuals are becoming increasingly concerned about their personal information and are advocating for the right to remove their data. Machine unlearning has emerged as a solution to erase training data from trained machine learning models. Despite its success in classifiers, research on Generative Adversarial Networks (GANs) is limited due to their unique architecture, including a generator and a discriminator. One challenge pertains to generator unlearning, as the process could potentially disrupt the continuity and completeness of the latent space. This disruption might consequently diminish the model's effectiveness after unlearning. Another challenge is how to define a criterion that the discriminator should perform for the unlearning images. In this paper, we introduce a substitution mechanism and define a fake label to effectively mitigate these challenges. Based on the substitution mechanism and fake label, we propose a cascaded unlearning approach for both item and class unlearning within GAN models, in which the unlearning and learning processes run in a cascaded manner. We conducted a comprehensive evaluation of the cascaded unlearning technique using the MNIST and CIFAR-10 datasets. Experimental results demonstrate that this approach achieves significantly improved item and class unlearning efficiency, reducing the required time by up to 185x and 284x for the MNIST and CIFAR-10 datasets, respectively, in comparison to retraining from scratch. Notably, although the model's performance experiences minor degradation after unlearning, this reduction is negligible when dealing with a minimal number of images (e.g., 64) and has no adverse effects on downstream tasks such as classification.