 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHASCO: Towards Agile HArdware and Software CO-design for Tensor Computation
May 04, 2021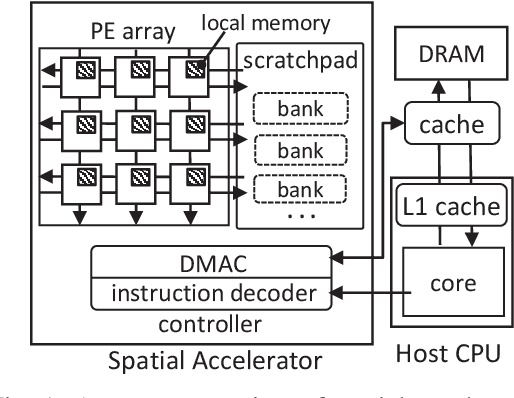
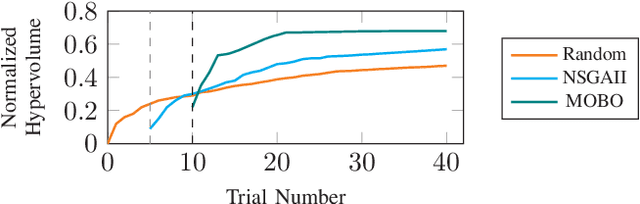
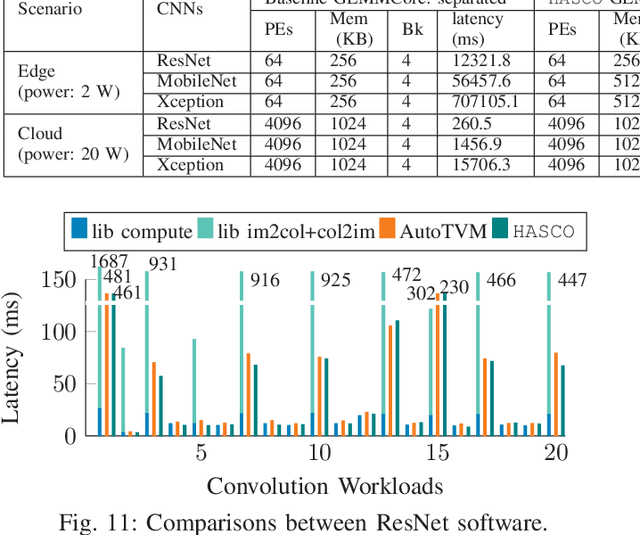
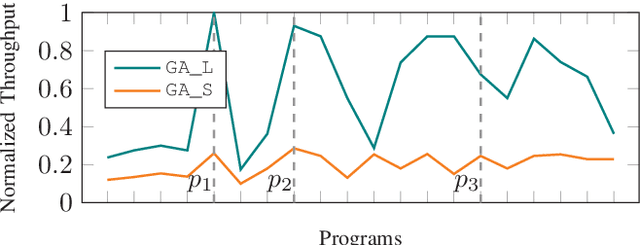
Tensor computations overwhelm traditional general-purpose computing devices due to the large amounts of data and operations of the computations. They call for a holistic solution composed of both hardware acceleration and software mapping. Hardware/software (HW/SW) co-design optimizes the hardware and software in concert and produces high-quality solutions. There are two main challenges in the co-design flow. First, multiple methods exist to partition tensor computation and have different impacts on performance and energy efficiency. Besides, the hardware part must be implemented by the intrinsic functions of spatial accelerators. It is hard for programmers to identify and analyze the partitioning methods manually. Second, the overall design space composed of HW/SW partitioning, hardware optimization, and software optimization is huge. The design space needs to be efficiently explored. To this end, we propose an agile co-design approach HASCO that provides an efficient HW/SW solution to dense tensor computation. We use tensor syntax trees as the unified IR, based on which we develop a two-step approach to identify partitioning methods. For each method, HASCO explores the hardware and software design spaces. We propose different algorithms for the explorations, as they have distinct objectives and evaluation costs. Concretely, we develop a multi-objective Bayesian optimization algorithm to explore hardware optimization. For software optimization, we use heuristic and Q-learning algorithms. Experiments demonstrate that HASCO achieves a 1.25X to 1.44X latency reduction through HW/SW co-design compared with developing the hardware and software separately.
Mix and Match: A Novel FPGA-Centric Deep Neural Network Quantization Framework
Dec 12, 2020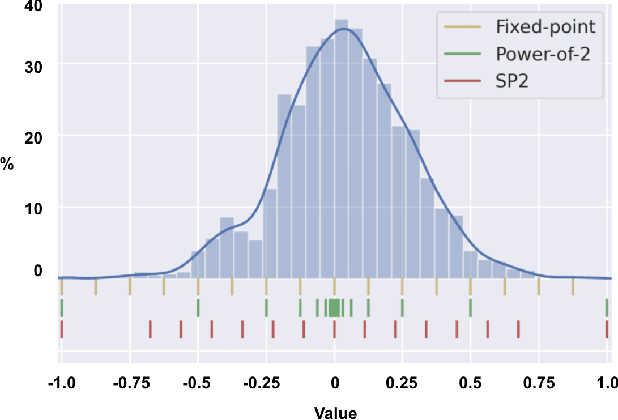
Deep Neural Networks (DNNs) have achieved extraordinary performance in various application domains. To support diverse DNN models, efficient implementations of DNN inference on edge-computing platforms, e.g., ASICs, FPGAs, and embedded systems, are extensively investigated. Due to the huge model size and computation amount, model compression is a critical step to deploy DNN models on edge devices. This paper focuses on weight quantization, a hardware-friendly model compression approach that is complementary to weight pruning. Unlike existing methods that use the same quantization scheme for all weights, we propose the first solution that applies different quantization schemes for different rows of the weight matrix. It is motivated by (1) the distribution of the weights in the different rows are not the same; and (2) the potential of achieving better utilization of heterogeneous FPGA hardware resources. To achieve that, we first propose a hardware-friendly quantization scheme named sum-of-power-of-2 (SP2) suitable for Gaussian-like weight distribution, in which the multiplication arithmetic can be replaced with logic shifter and adder, thereby enabling highly efficient implementations with the FPGA LUT resources. In contrast, the existing fixed-point quantization is suitable for Uniform-like weight distribution and can be implemented efficiently by DSP. Then to fully explore the resources, we propose an FPGA-centric mixed scheme quantization (MSQ) with an ensemble of the proposed SP2 and the fixed-point schemes. Combining the two schemes can maintain, or even increase accuracy due to better matching with weight distributions.
PERMDNN: Efficient Compressed DNN Architecture with Permuted Diagonal Matrices
Apr 23, 2020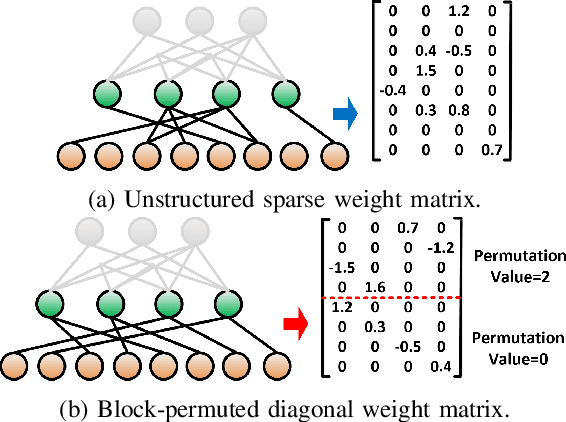
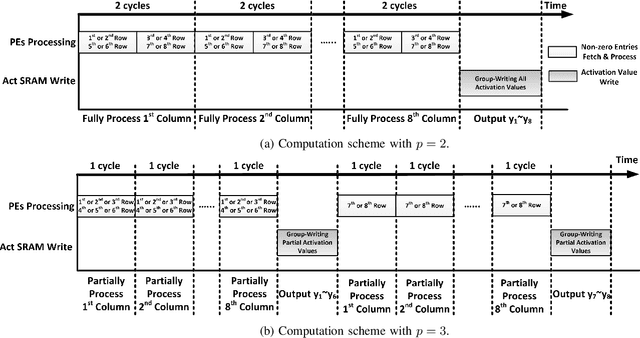

Deep neural network (DNN) has emerged as the most important and popular artificial intelligent (AI) technique. The growth of model size poses a key energy efficiency challenge for the underlying computing platform. Thus, model compression becomes a crucial problem. However, the current approaches are limited by various drawbacks. Specifically, network sparsification approach suffers from irregularity, heuristic nature and large indexing overhead. On the other hand, the recent structured matrix-based approach (i.e., CirCNN) is limited by the relatively complex arithmetic computation (i.e., FFT), less flexible compression ratio, and its inability to fully utilize input sparsity. To address these drawbacks, this paper proposes PermDNN, a novel approach to generate and execute hardware-friendly structured sparse DNN models using permuted diagonal matrices. Compared with unstructured sparsification approach, PermDNN eliminates the drawbacks of indexing overhead, non-heuristic compression effects and time-consuming retraining. Compared with circulant structure-imposing approach, PermDNN enjoys the benefits of higher reduction in computational complexity, flexible compression ratio, simple arithmetic computation and full utilization of input sparsity. We propose PermDNN architecture, a multi-processing element (PE) fully-connected (FC) layer-targeted computing engine. The entire architecture is highly scalable and flexible, and hence it can support the needs of different applications with different model configurations. We implement a 32-PE design using CMOS 28nm technology. Compared with EIE, PermDNN achieves 3.3x~4.8x higher throughout, 5.9x~8.5x better area efficiency and 2.8x~4.0x better energy efficiency on different workloads. Compared with CirCNN, PermDNN achieves 11.51x higher throughput and 3.89x better energy efficiency.
PatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning
Jan 22, 2020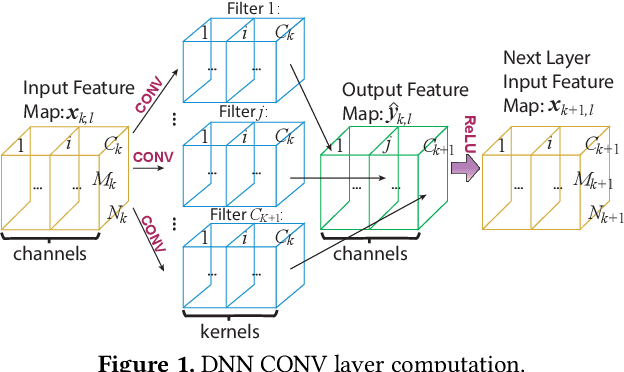
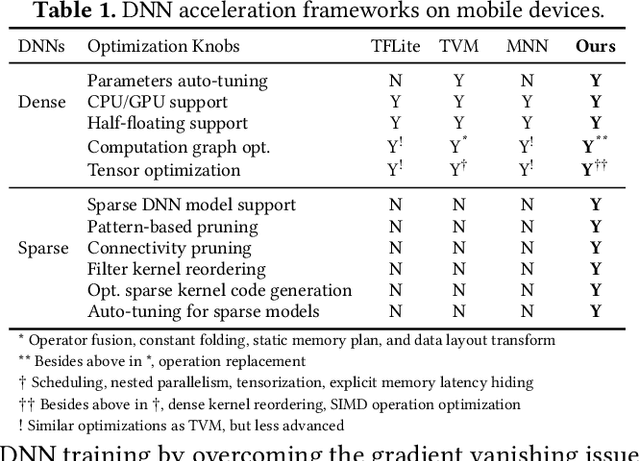
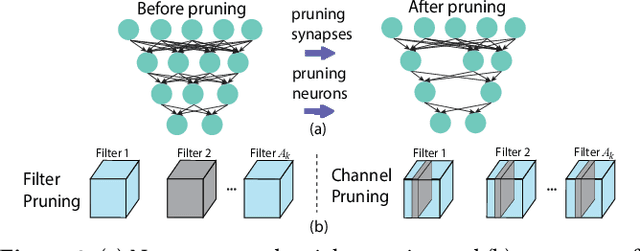
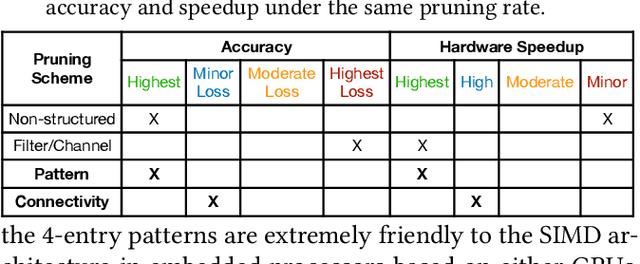
With the emergence of a spectrum of high-end mobile devices, many applications that formerly required desktop-level computation capability are being transferred to these devices. However, executing the inference of Deep Neural Networks (DNNs) is still challenging considering high computation and storage demands, specifically, if real-time performance with high accuracy is needed. Weight pruning of DNNs is proposed, but existing schemes represent two extremes in the design space: non-structured pruning is fine-grained, accurate, but not hardware friendly; structured pruning is coarse-grained, hardware-efficient, but with higher accuracy loss. In this paper, we introduce a new dimension, fine-grained pruning patterns inside the coarse-grained structures, revealing a previously unknown point in design space. With the higher accuracy enabled by fine-grained pruning patterns, the unique insight is to use the compiler to re-gain and guarantee high hardware efficiency. In other words, our method achieves the best of both worlds, and is desirable across theory/algorithm, compiler, and hardware levels. The proposed PatDNN is an end-to-end framework to efficiently execute DNN on mobile devices with the help of a novel model compression technique (pattern-based pruning based on extended ADMM solution framework) and a set of thorough architecture-aware compiler- and code generation-based optimizations (filter kernel reordering, compressed weight storage, register load redundancy elimination, and parameter auto-tuning). Evaluation results demonstrate that PatDNN outperforms three state-of-the-art end-to-end DNN frameworks, TensorFlow Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 44.5x, 11.4x, and 7.1x, respectively, with no accuracy compromise. Real-time inference of representative large-scale DNNs (e.g., VGG-16, ResNet-50) can be achieved using mobile devices.
Heterogeneity-Aware Asynchronous Decentralized Training
Sep 17, 2019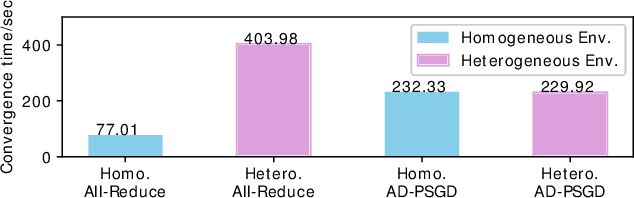
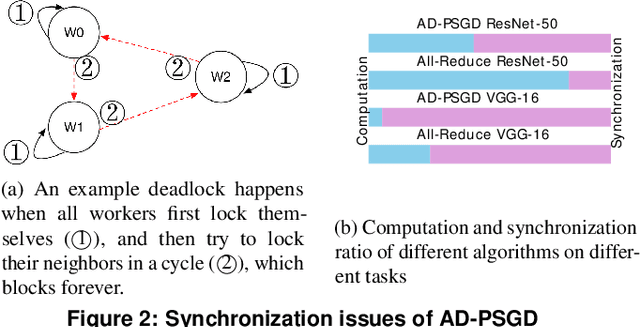
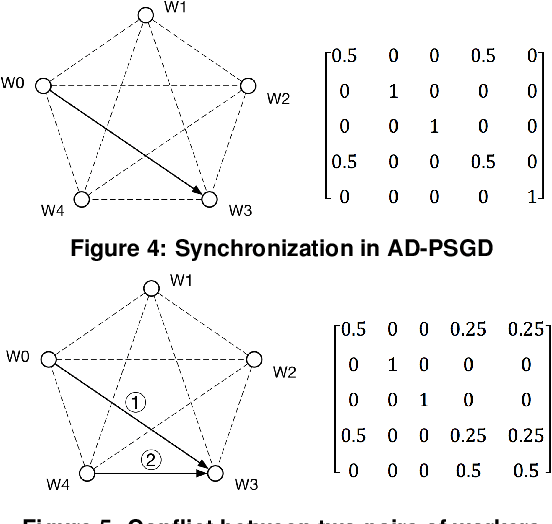
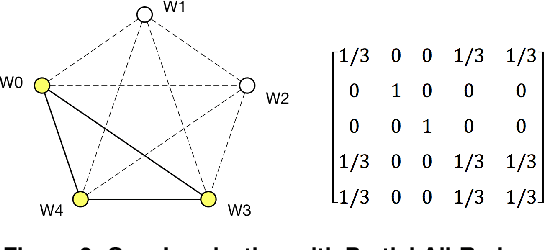
Distributed deep learning training usually adopts All-Reduce as the synchronization mechanism for data parallel algorithms due to its high performance in homogeneous environment. However, its performance is bounded by the slowest worker among all workers, and is significantly slower in heterogeneous situations. AD-PSGD, a newly proposed synchronization method which provides numerically fast convergence and heterogeneity tolerance, suffers from deadlock issues and high synchronization overhead. Is it possible to get the best of both worlds - designing a distributed training method that has both high performance as All-Reduce in homogeneous environment and good heterogeneity tolerance as AD-PSGD? In this paper, we propose Ripples, a high-performance heterogeneity-aware asynchronous decentralized training approach. We achieve the above goal with intensive synchronization optimization, emphasizing the interplay between algorithm and system implementation. To reduce synchronization cost, we propose a novel communication primitive Partial All-Reduce that allows a large group of workers to synchronize quickly. To reduce synchronization conflict, we propose static group scheduling in homogeneous environment and simple techniques (Group Buffer and Group Division) to avoid conflicts with slightly reduced randomness. Our experiments show that in homogeneous environment, Ripples is 1.1 times faster than the state-of-the-art implementation of All-Reduce, 5.1 times faster than Parameter Server and 4.3 times faster than AD-PSGD. In a heterogeneous setting, Ripples shows 2 times speedup over All-Reduce, and still obtains 3 times speedup over the Parameter Server baseline.
A Stochastic-Computing based Deep Learning Framework using Adiabatic Quantum-Flux-Parametron SuperconductingTechnology
Jul 22, 2019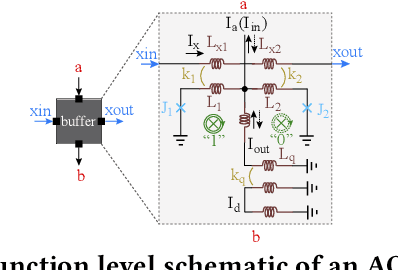
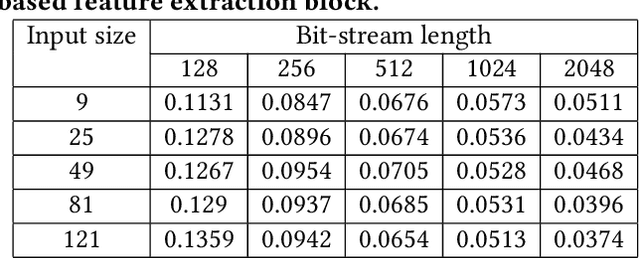
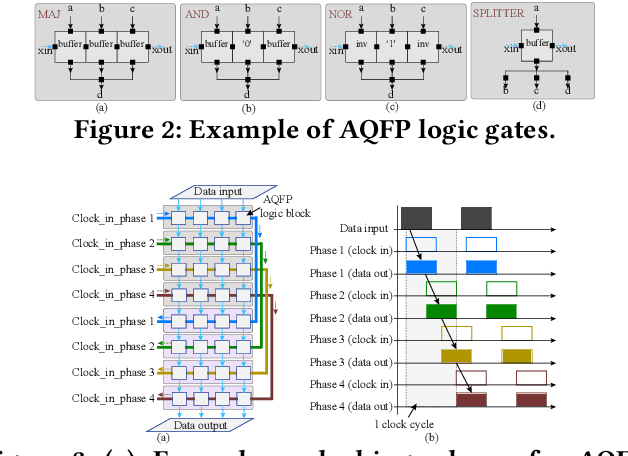
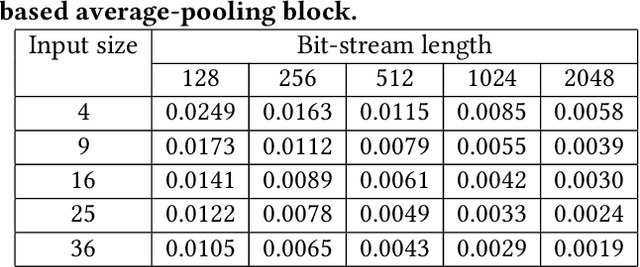
The Adiabatic Quantum-Flux-Parametron (AQFP) superconducting technology has been recently developed, which achieves the highest energy efficiency among superconducting logic families, potentially huge gain compared with state-of-the-art CMOS. In 2016, the successful fabrication and testing of AQFP-based circuits with the scale of 83,000 JJs have demonstrated the scalability and potential of implementing large-scale systems using AQFP. As a result, it will be promising for AQFP in high-performance computing and deep space applications, with Deep Neural Network (DNN) inference acceleration as an important example. Besides ultra-high energy efficiency, AQFP exhibits two unique characteristics: the deep pipelining nature since each AQFP logic gate is connected with an AC clock signal, which increases the difficulty to avoid RAW hazards; the second is the unique opportunity of true random number generation (RNG) using a single AQFP buffer, far more efficient than RNG in CMOS. We point out that these two characteristics make AQFP especially compatible with the \emph{stochastic computing} (SC) technique, which uses a time-independent bit sequence for value representation, and is compatible with the deep pipelining nature. Further, the application of SC has been investigated in DNNs in prior work, and the suitability has been illustrated as SC is more compatible with approximate computations. This work is the first to develop an SC-based DNN acceleration framework using AQFP technology.
Non-structured DNN Weight Pruning Considered Harmful
Jul 03, 2019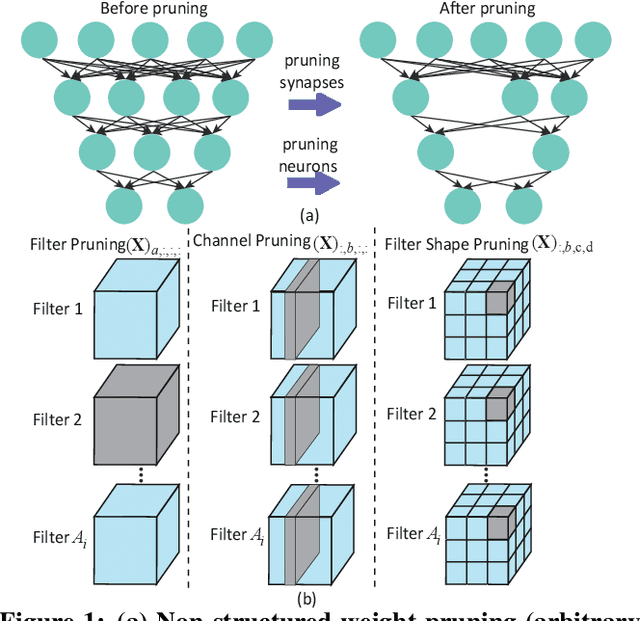
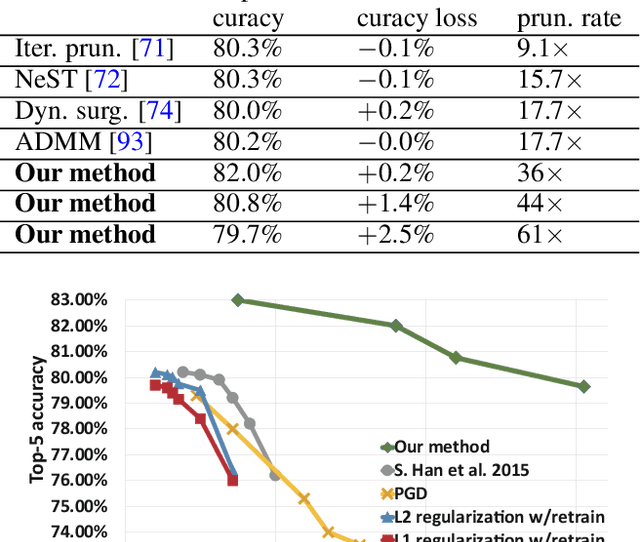
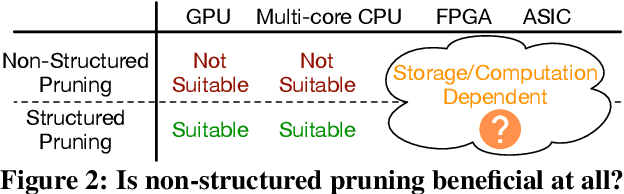
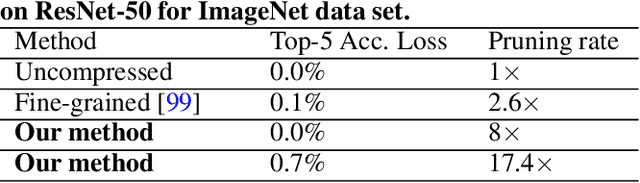
Large deep neural network (DNN) models pose the key challenge to energy efficiency due to the significantly higher energy consumption of off-chip DRAM accesses than arithmetic or SRAM operations. It motivates the intensive research on model compression with two main approaches. Weight pruning leverages the redundancy in the number of weights and can be performed in a non-structured, which has higher flexibility and pruning rate but incurs index accesses due to irregular weights, or structured manner, which preserves the full matrix structure with lower pruning rate. Weight quantization leverages the redundancy in the number of bits in weights. Compared to pruning, quantization is much more hardware-friendly, and has become a "must-do" step for FPGA and ASIC implementations. This paper provides a definitive answer to the question for the first time. First, we build ADMM-NN-S by extending and enhancing ADMM-NN, a recently proposed joint weight pruning and quantization framework. Second, we develop a methodology for fair and fundamental comparison of non-structured and structured pruning in terms of both storage and computation efficiency. Our results show that ADMM-NN-S consistently outperforms the prior art: (i) it achieves 348x, 36x, and 8x overall weight pruning on LeNet-5, AlexNet, and ResNet-50, respectively, with (almost) zero accuracy loss; (ii) we demonstrate the first fully binarized (for all layers) DNNs can be lossless in accuracy in many cases. These results provide a strong baseline and credibility of our study. Based on the proposed comparison framework, with the same accuracy and quantization, the results show that non-structrued pruning is not competitive in terms of both storage and computation efficiency. Thus, we conclude that non-structured pruning is considered harmful. We urge the community not to continue the DNN inference acceleration for non-structured sparsity.
Hop: Heterogeneity-Aware Decentralized Training
Feb 07, 2019
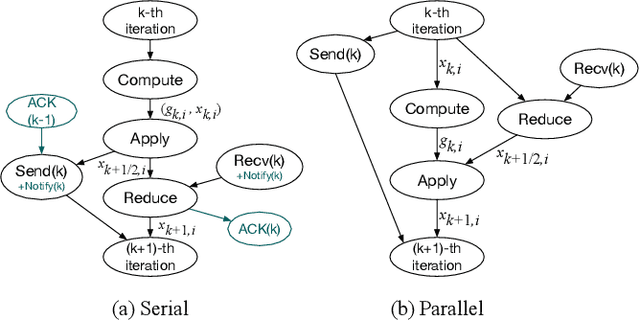
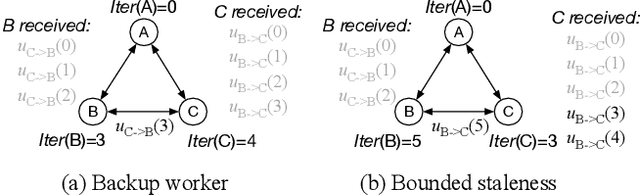

Recent work has shown that decentralized algorithms can deliver superior performance over centralized ones in the context of machine learning. The two approaches, with the main difference residing in their distinct communication patterns, are both susceptible to performance degradation in heterogeneous environments. Although vigorous efforts have been devoted to supporting centralized algorithms against heterogeneity, little has been explored in decentralized algorithms regarding this problem. This paper proposes Hop, the first heterogeneity-aware decentralized training protocol. Based on a unique characteristic of decentralized training that we have identified, the iteration gap, we propose a queue-based synchronization mechanism that can efficiently implement backup workers and bounded staleness in the decentralized setting. To cope with deterministic slowdown, we propose skipping iterations so that the effect of slower workers is further mitigated. We build a prototype implementation of Hop on TensorFlow. The experiment results on CNN and SVM show significant speedup over standard decentralized training in heterogeneous settings.
HyPar: Towards Hybrid Parallelism for Deep Learning Accelerator Array
Jan 07, 2019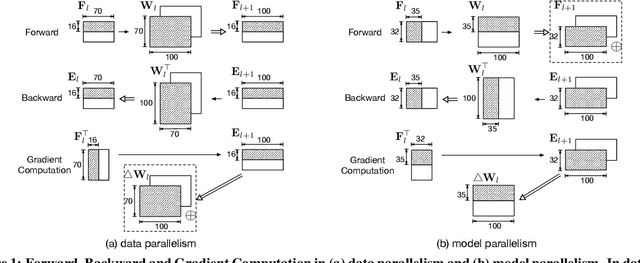
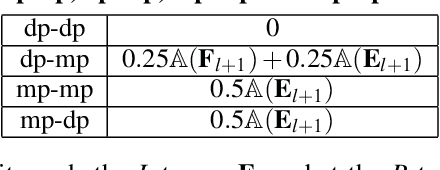
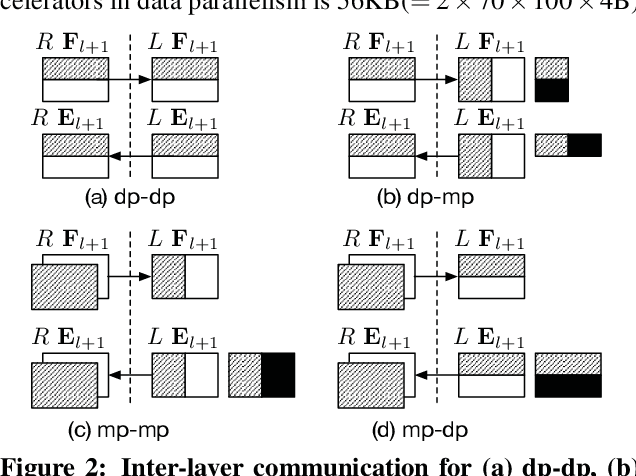
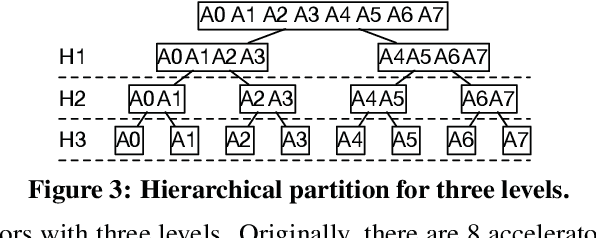
With the rise of artificial intelligence in recent years, Deep Neural Networks (DNNs) have been widely used in many domains. To achieve high performance and energy efficiency, hardware acceleration (especially inference) of DNNs is intensively studied both in academia and industry. However, we still face two challenges: large DNN models and datasets, which incur frequent off-chip memory accesses; and the training of DNNs, which is not well-explored in recent accelerator designs. To truly provide high throughput and energy efficient acceleration for the training of deep and large models, we inevitably need to use multiple accelerators to explore the coarse-grain parallelism, compared to the fine-grain parallelism inside a layer considered in most of the existing architectures. It poses the key research question to seek the best organization of computation and dataflow among accelerators. In this paper, we propose a solution HyPar to determine layer-wise parallelism for deep neural network training with an array of DNN accelerators. HyPar partitions the feature map tensors (input and output), the kernel tensors, the gradient tensors, and the error tensors for the DNN accelerators. A partition constitutes the choice of parallelism for weighted layers. The optimization target is to search a partition that minimizes the total communication during training a complete DNN. To solve this problem, we propose a communication model to explain the source and amount of communications. Then, we use a hierarchical layer-wise dynamic programming method to search for the partition for each layer.
ADMM-NN: An Algorithm-Hardware Co-Design Framework of DNNs Using Alternating Direction Method of Multipliers
Dec 31, 2018
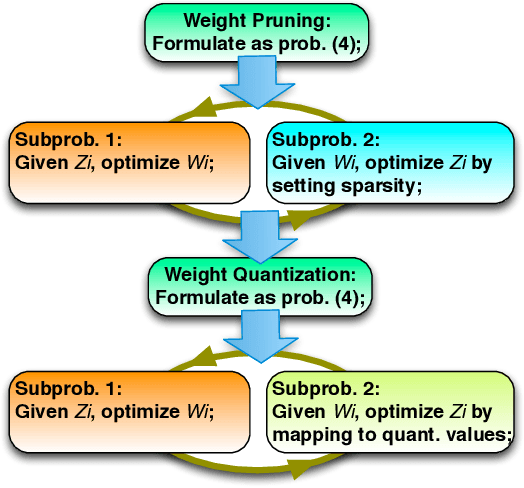
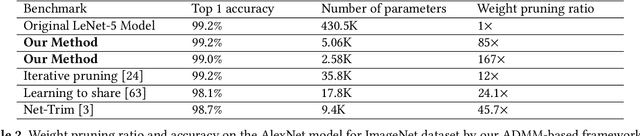
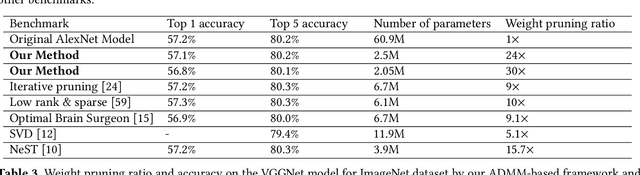
To facilitate efficient embedded and hardware implementations of deep neural networks (DNNs), two important categories of DNN model compression techniques: weight pruning and weight quantization are investigated. The former leverages the redundancy in the number of weights, whereas the latter leverages the redundancy in bit representation of weights. However, there lacks a systematic framework of joint weight pruning and quantization of DNNs, thereby limiting the available model compression ratio. Moreover, the computation reduction, energy efficiency improvement, and hardware performance overhead need to be accounted for besides simply model size reduction. To address these limitations, we present ADMM-NN, the first algorithm-hardware co-optimization framework of DNNs using Alternating Direction Method of Multipliers (ADMM), a powerful technique to deal with non-convex optimization problems with possibly combinatorial constraints. The first part of ADMM-NN is a systematic, joint framework of DNN weight pruning and quantization using ADMM. It can be understood as a smart regularization technique with regularization target dynamically updated in each ADMM iteration, thereby resulting in higher performance in model compression than prior work. The second part is hardware-aware DNN optimizations to facilitate hardware-level implementations. Without accuracy loss, we can achieve 85$\times$ and 24$\times$ pruning on LeNet-5 and AlexNet models, respectively, significantly higher than prior work. The improvement becomes more significant when focusing on computation reductions. Combining weight pruning and quantization, we achieve 1,910$\times$ and 231$\times$ reductions in overall model size on these two benchmarks, when focusing on data storage. Highly promising results are also observed on other representative DNNs such as VGGNet and ResNet-50.