 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTMobile: Beyond Real-Time Mobile Acceleration of RNNs for Speech Recognition
Feb 19, 2020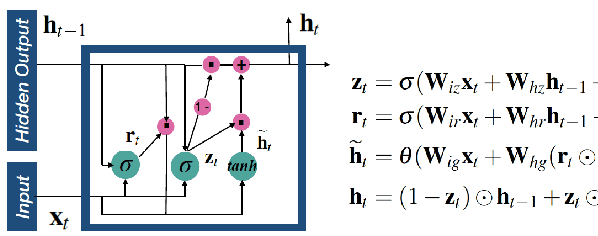
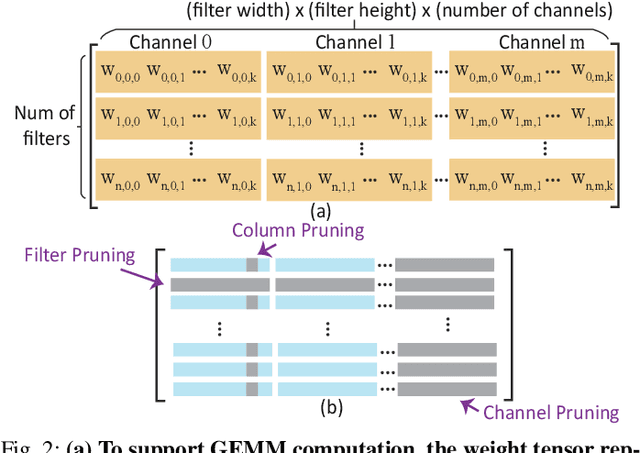
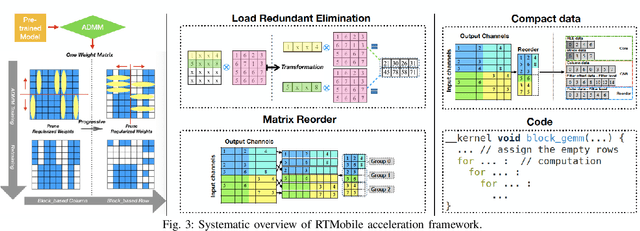
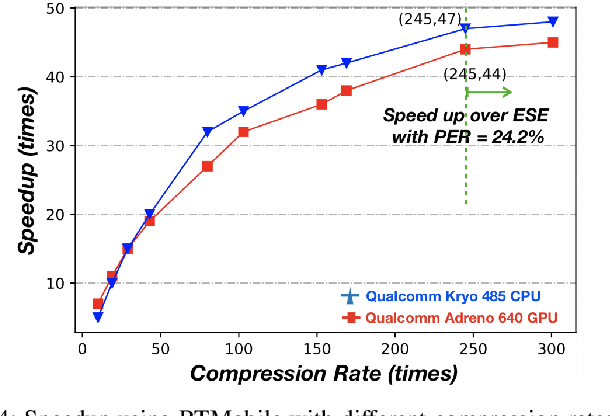
Recurrent neural networks (RNNs) based automatic speech recognition has nowadays become prevalent on mobile devices such as smart phones. However, previous RNN compression techniques either suffer from hardware performance overhead due to irregularity or significant accuracy loss due to the preserved regularity for hardware friendliness. In this work, we propose RTMobile that leverages both a novel block-based pruning approach and compiler optimizations to accelerate RNN inference on mobile devices. Our proposed RTMobile is the first work that can achieve real-time RNN inference on mobile platforms. Experimental results demonstrate that RTMobile can significantly outperform existing RNN hardware acceleration methods in terms of inference accuracy and time. Compared with prior work on FPGA, RTMobile using Adreno 640 embedded GPU on GRU can improve the energy-efficiency by about 40$\times$ while maintaining the same inference time.
Block Switching: A Stochastic Approach for Deep Learning Security
Feb 18, 2020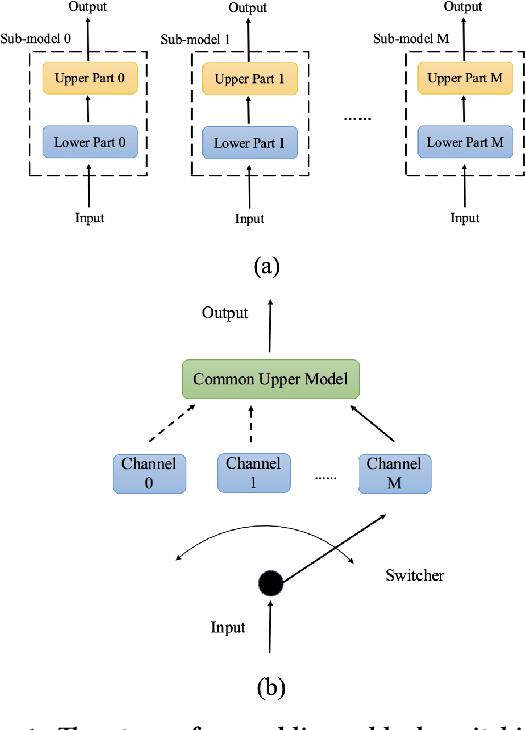
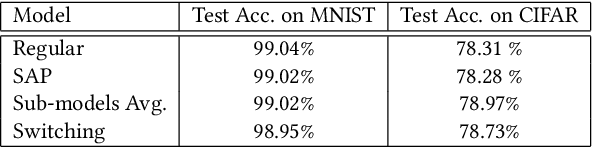
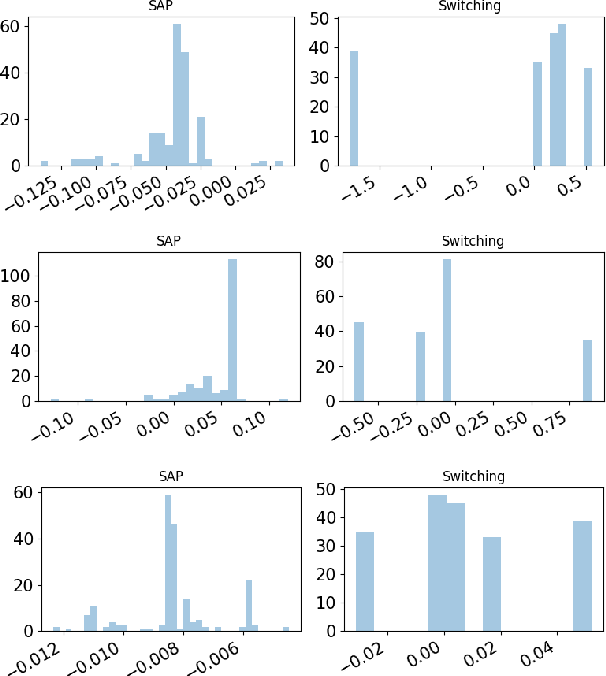
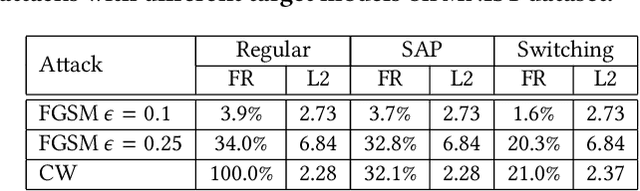
Recent study of adversarial attacks has revealed the vulnerability of modern deep learning models. That is, subtly crafted perturbations of the input can make a trained network with high accuracy produce arbitrary incorrect predictions, while maintain imperceptible to human vision system. In this paper, we introduce Block Switching (BS), a defense strategy against adversarial attacks based on stochasticity. BS replaces a block of model layers with multiple parallel channels, and the active channel is randomly assigned in the run time hence unpredictable to the adversary. We show empirically that BS leads to a more dispersed input gradient distribution and superior defense effectiveness compared with other stochastic defenses such as stochastic activation pruning (SAP). Compared to other defenses, BS is also characterized by the following features: (i) BS causes less test accuracy drop; (ii) BS is attack-independent and (iii) BS is compatible with other defenses and can be used jointly with others.
Towards Query-Efficient Black-Box Adversary with Zeroth-Order Natural Gradient Descent
Feb 18, 2020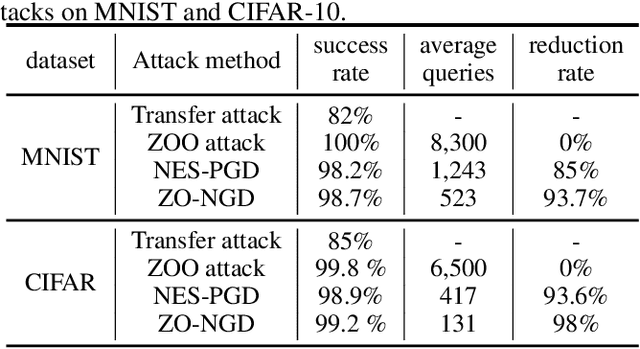

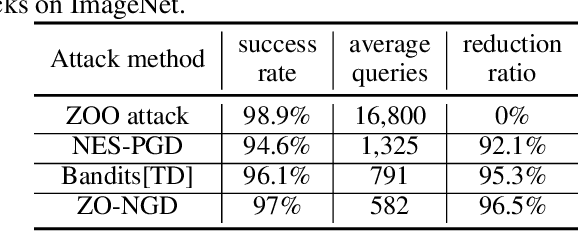
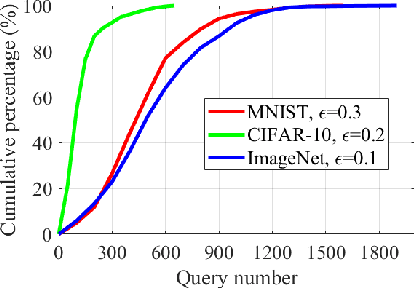
Despite the great achievements of the modern deep neural networks (DNNs), the vulnerability/robustness of state-of-the-art DNNs raises security concerns in many application domains requiring high reliability. Various adversarial attacks are proposed to sabotage the learning performance of DNN models. Among those, the black-box adversarial attack methods have received special attentions owing to their practicality and simplicity. Black-box attacks usually prefer less queries in order to maintain stealthy and low costs. However, most of the current black-box attack methods adopt the first-order gradient descent method, which may come with certain deficiencies such as relatively slow convergence and high sensitivity to hyper-parameter settings. In this paper, we propose a zeroth-order natural gradient descent (ZO-NGD) method to design the adversarial attacks, which incorporates the zeroth-order gradient estimation technique catering to the black-box attack scenario and the second-order natural gradient descent to achieve higher query efficiency. The empirical evaluations on image classification datasets demonstrate that ZO-NGD can obtain significantly lower model query complexities compared with state-of-the-art attack methods.
PatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning
Jan 22, 2020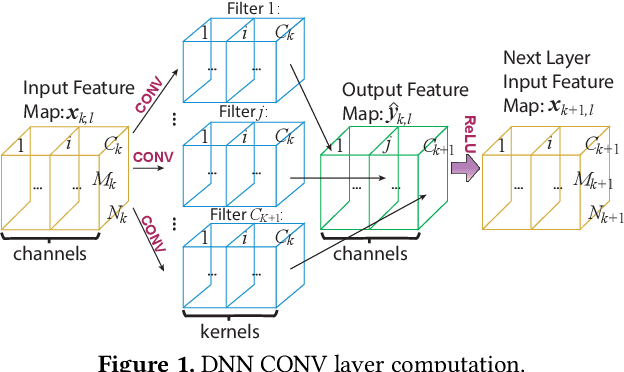
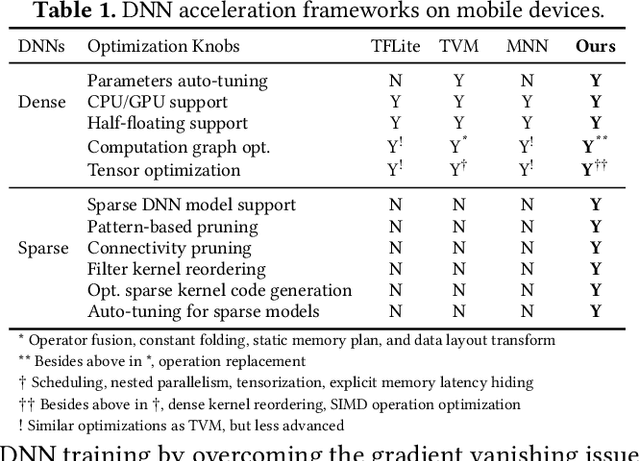
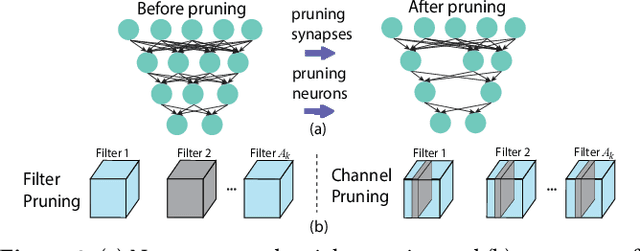
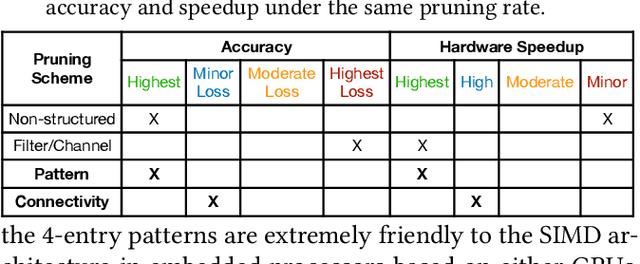
With the emergence of a spectrum of high-end mobile devices, many applications that formerly required desktop-level computation capability are being transferred to these devices. However, executing the inference of Deep Neural Networks (DNNs) is still challenging considering high computation and storage demands, specifically, if real-time performance with high accuracy is needed. Weight pruning of DNNs is proposed, but existing schemes represent two extremes in the design space: non-structured pruning is fine-grained, accurate, but not hardware friendly; structured pruning is coarse-grained, hardware-efficient, but with higher accuracy loss. In this paper, we introduce a new dimension, fine-grained pruning patterns inside the coarse-grained structures, revealing a previously unknown point in design space. With the higher accuracy enabled by fine-grained pruning patterns, the unique insight is to use the compiler to re-gain and guarantee high hardware efficiency. In other words, our method achieves the best of both worlds, and is desirable across theory/algorithm, compiler, and hardware levels. The proposed PatDNN is an end-to-end framework to efficiently execute DNN on mobile devices with the help of a novel model compression technique (pattern-based pruning based on extended ADMM solution framework) and a set of thorough architecture-aware compiler- and code generation-based optimizations (filter kernel reordering, compressed weight storage, register load redundancy elimination, and parameter auto-tuning). Evaluation results demonstrate that PatDNN outperforms three state-of-the-art end-to-end DNN frameworks, TensorFlow Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 44.5x, 11.4x, and 7.1x, respectively, with no accuracy compromise. Real-time inference of representative large-scale DNNs (e.g., VGG-16, ResNet-50) can be achieved using mobile devices.
Adversarial T-shirt! Evading Person Detectors in A Physical World
Nov 27, 2019It is known that deep neural networks (DNNs) are vulnerable to adversarial attacks. The so-called physical adversarial examples deceive DNN-based decision makers by attaching adversarial patches to real objects. However, most of the existing works on physical adversarial attacks focus on static objects such as glass frames, stop signs and images attached to cardboard. In this work, we propose Adversarial T-shirts, a robust physical adversarial example for evading person detectors even if it could undergo non-rigid deformation due to a moving person's pose changes. To the best of our knowledge, this is the first work that models the effect of deformation for designing physical adversarial examples with respect to non-rigid objects such as T-shirts. We show that the proposed method achieves 74% and 57% attack success rates in digital and physical worlds respectively against YOLOv2. In contrast, the state-of-the-art physical attack method to fool a person detector only achieves 18% attack success rate. Furthermore, by leveraging min-max optimization, we extend our method to the ensemble attack setting against two object detectors YOLO-v2 and Faster R-CNN simultaneously.
ZO-AdaMM: Zeroth-Order Adaptive Momentum Method for Black-Box Optimization
Oct 16, 2019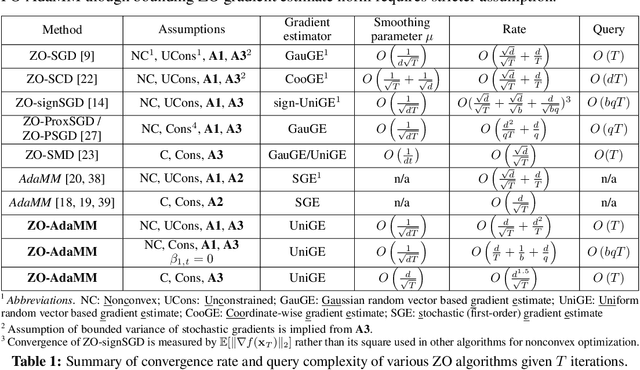
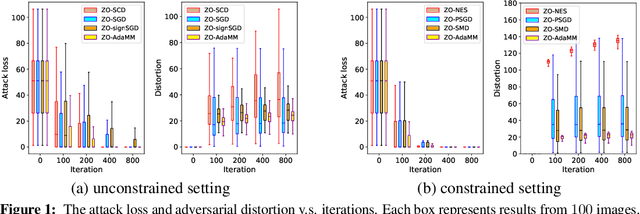
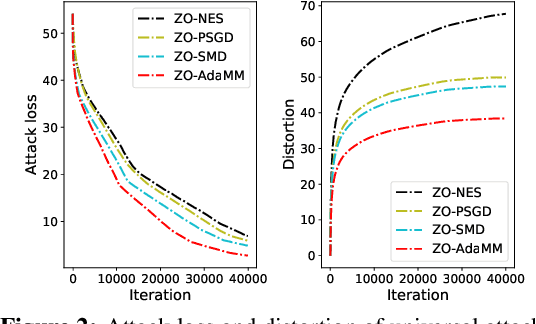
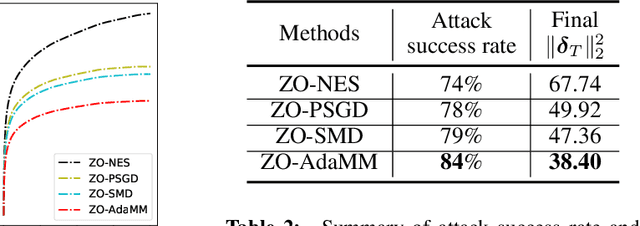
The adaptive momentum method (AdaMM), which uses past gradients to update descent directions and learning rates simultaneously, has become one of the most popular first-order optimization methods for solving machine learning problems. However, AdaMM is not suited for solving black-box optimization problems, where explicit gradient forms are difficult or infeasible to obtain. In this paper, we propose a zeroth-order AdaMM (ZO-AdaMM) algorithm, that generalizes AdaMM to the gradient-free regime. We show that the convergence rate of ZO-AdaMM for both convex and nonconvex optimization is roughly a factor of $O(\sqrt{d})$ worse than that of the first-order AdaMM algorithm, where $d$ is problem size. In particular, we provide a deep understanding on why Mahalanobis distance matters in convergence of ZO-AdaMM and other AdaMM-type methods. As a byproduct, our analysis makes the first step toward understanding adaptive learning rate methods for nonconvex constrained optimization. Furthermore, we demonstrate two applications, designing per-image and universal adversarial attacks from black-box neural networks, respectively. We perform extensive experiments on ImageNet and empirically show that ZO-AdaMM converges much faster to a solution of high accuracy compared with $6$ state-of-the-art ZO optimization methods.
Reweighted Proximal Pruning for Large-Scale Language Representation
Sep 27, 2019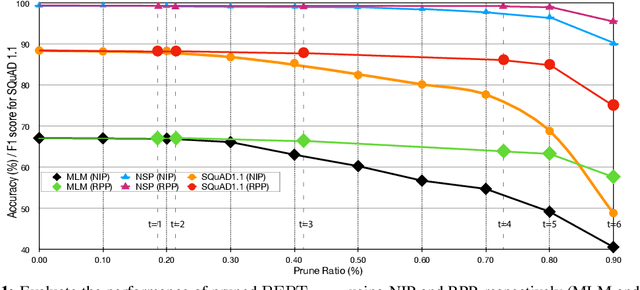
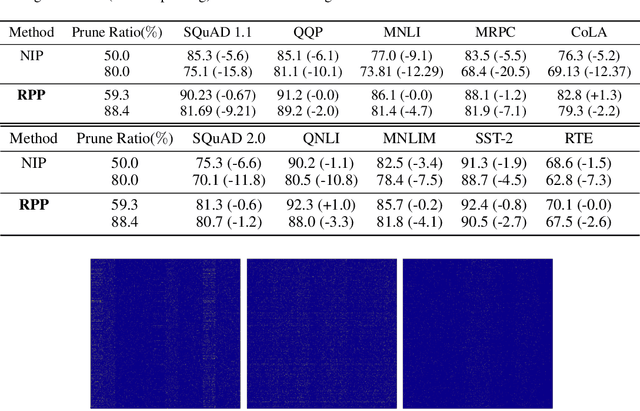
Recently, pre-trained language representation flourishes as the mainstay of the natural language understanding community, e.g., BERT. These pre-trained language representations can create state-of-the-art results on a wide range of downstream tasks. Along with continuous significant performance improvement, the size and complexity of these pre-trained neural models continue to increase rapidly. Is it possible to compress these large-scale language representation models? How will the pruned language representation affect the downstream multi-task transfer learning objectives? In this paper, we propose Reweighted Proximal Pruning (RPP), a new pruning method specifically designed for a large-scale language representation model. Through experiments on SQuAD and the GLUE benchmark suite, we show that proximal pruned BERT keeps high accuracy for both the pre-training task and the downstream multiple fine-tuning tasks at high prune ratio. RPP provides a new perspective to help us analyze what large-scale language representation might learn. Additionally, RPP makes it possible to deploy a large state-of-the-art language representation model such as BERT on a series of distinct devices (e.g., online servers, mobile phones, and edge devices).
PCONV: The Missing but Desirable Sparsity in DNN Weight Pruning for Real-time Execution on Mobile Devices
Sep 12, 2019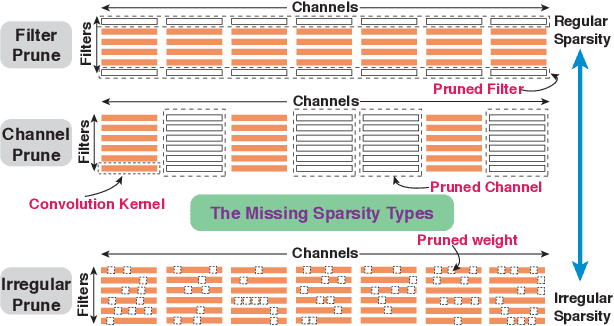
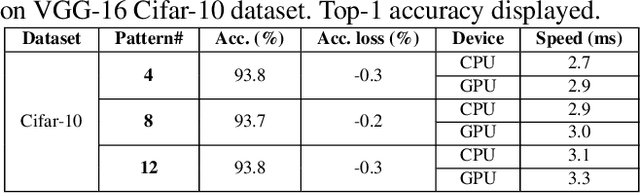
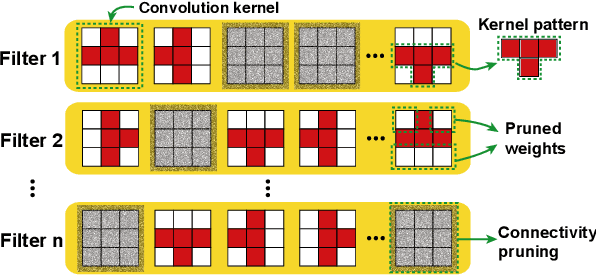
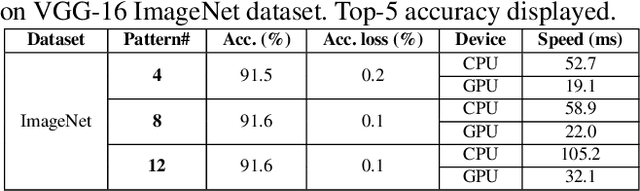
Model compression techniques on Deep Neural Network (DNN) have been widely acknowledged as an effective way to achieve acceleration on a variety of platforms, and DNN weight pruning is a straightforward and effective method. There are currently two mainstreams of pruning methods representing two extremes of pruning regularity: non-structured, fine-grained pruning can achieve high sparsity and accuracy, but is not hardware friendly; structured, coarse-grained pruning exploits hardware-efficient structures in pruning, but suffers from accuracy drop when the pruning rate is high. In this paper, we introduce PCONV, comprising a new sparsity dimension, -- fine-grained pruning patterns inside the coarse-grained structures. PCONV comprises two types of sparsities, Sparse Convolution Patterns (SCP) which is generated from intra-convolution kernel pruning and connectivity sparsity generated from inter-convolution kernel pruning. Essentially, SCP enhances accuracy due to its special vision properties, and connectivity sparsity increases pruning rate while maintaining balanced workload on filter computation. To deploy PCONV, we develop a novel compiler-assisted DNN inference framework and execute PCONV models in real-time without accuracy compromise, which cannot be achieved in prior work. Our experimental results show that, PCONV outperforms three state-of-art end-to-end DNN frameworks, TensorFlow-Lite, TVM, and Alibaba Mobile Neural Network with speedup up to 39.2x, 11.4x, and 6.3x, respectively, with no accuracy loss. Mobile devices can achieve real-time inference on large-scale DNNs.
Protecting Neural Networks with Hierarchical Random Switching: Towards Better Robustness-Accuracy Trade-off for Stochastic Defenses
Aug 20, 2019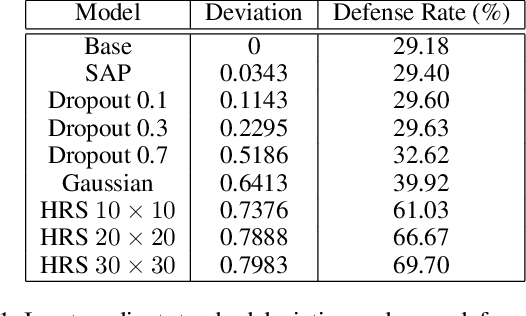
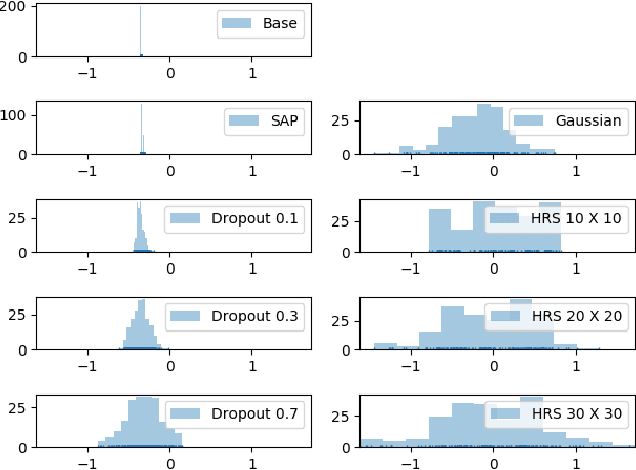
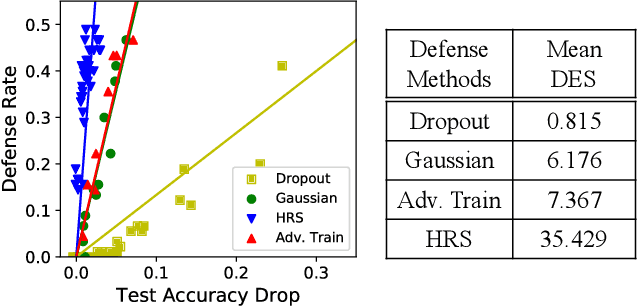
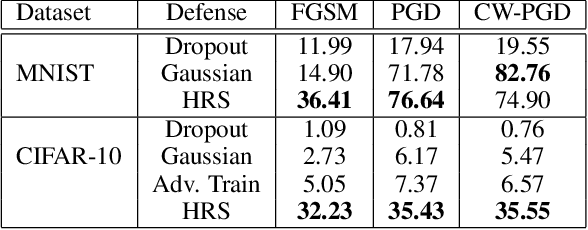
Despite achieving remarkable success in various domains, recent studies have uncovered the vulnerability of deep neural networks to adversarial perturbations, creating concerns on model generalizability and new threats such as prediction-evasive misclassification or stealthy reprogramming. Among different defense proposals, stochastic network defenses such as random neuron activation pruning or random perturbation to layer inputs are shown to be promising for attack mitigation. However, one critical drawback of current defenses is that the robustness enhancement is at the cost of noticeable performance degradation on legitimate data, e.g., large drop in test accuracy. This paper is motivated by pursuing for a better trade-off between adversarial robustness and test accuracy for stochastic network defenses. We propose Defense Efficiency Score (DES), a comprehensive metric that measures the gain in unsuccessful attack attempts at the cost of drop in test accuracy of any defense. To achieve a better DES, we propose hierarchical random switching (HRS), which protects neural networks through a novel randomization scheme. A HRS-protected model contains several blocks of randomly switching channels to prevent adversaries from exploiting fixed model structures and parameters for their malicious purposes. Extensive experiments show that HRS is superior in defending against state-of-the-art white-box and adaptive adversarial misclassification attacks. We also demonstrate the effectiveness of HRS in defending adversarial reprogramming, which is the first defense against adversarial programs. Moreover, in most settings the average DES of HRS is at least 5X higher than current stochastic network defenses, validating its significantly improved robustness-accuracy trade-off.
On the Design of Black-box Adversarial Examples by Leveraging Gradient-free Optimization and Operator Splitting Method
Jul 26, 2019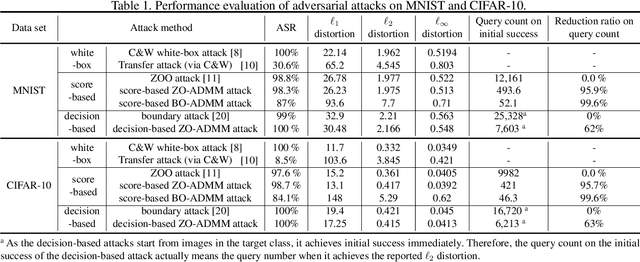

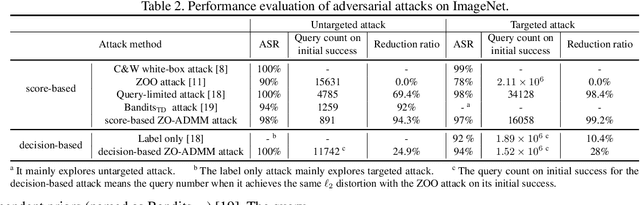
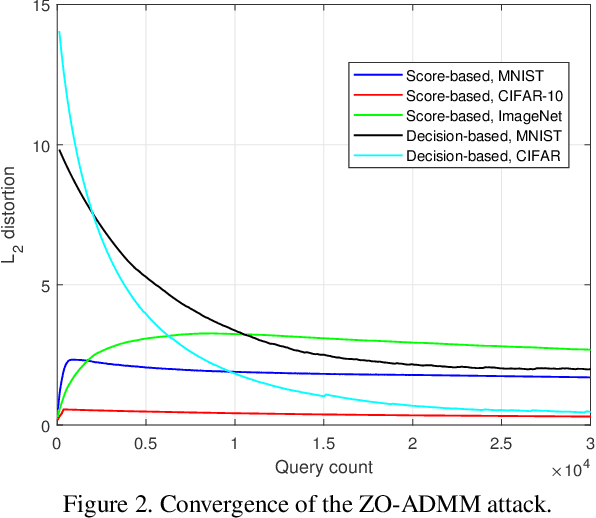
Robust machine learning is currently one of the most prominent topics which could potentially help shaping a future of advanced AI platforms that not only perform well in average cases but also in worst cases or adverse situations. Despite the long-term vision, however, existing studies on black-box adversarial attacks are still restricted to very specific settings of threat models (e.g., single distortion metric and restrictive assumption on target model's feedback to queries) and/or suffer from prohibitively high query complexity. To push for further advances in this field, we introduce a general framework based on an operator splitting method, the alternating direction method of multipliers (ADMM) to devise efficient, robust black-box attacks that work with various distortion metrics and feedback settings without incurring high query complexity. Due to the black-box nature of the threat model, the proposed ADMM solution framework is integrated with zeroth-order (ZO) optimization and Bayesian optimization (BO), and thus is applicable to the gradient-free regime. This results in two new black-box adversarial attack generation methods, ZO-ADMM and BO-ADMM. Our empirical evaluations on image classification datasets show that our proposed approaches have much lower function query complexities compared to state-of-the-art attack methods, but achieve very competitive attack success rates.