 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindLoom: Composing Thought Modes for Frontier-Level Reasoning Data Synthesis
May 20, 2026Although LLMs have made substantial progress in reasoning, systematically producing frontier-level reasoning data remains difficult. Existing synthesis methods often have limited visibility into the structural factors that govern problem difficulty, which can result in narrow diversity and unstable difficulty control. In this work, we view the difficulty of a reasoning problem as arising from the accumulation of atomic knowledge-reasoning transformations, which we term thought modes. Building on this perspective, we propose MindLoom, a framework for synthesizing frontier-level reasoning data through compositional thought mode engineering. Given a collection of hard problems with verified solutions, MindLoom first decomposes those solutions into thought mode chains that reveal each problem's construction logic. It then trains a retrieval model that matches problem states to compatible thought modes, providing guidance on which reasoning challenges to introduce during synthesis. New problems are composed by iteratively applying retrieved thought modes to seed questions, with distribution-aligned sampling to encourage diverse reasoning coverage. Finally, a rollout-based judging stage labels generated questions by difficulty and supplies judged-correct responses for supervised fine-tuning. We evaluate MindLoom on nine benchmarks covering five STEM disciplines and four mathematical reasoning tasks across multiple model families and sizes. Models fine-tuned on MindLoom-generated data achieves favorable performances over base models, distillation, and external-data baselines across the reported benchmarks. Ablation studies indicate the contribution of each component, and further analysis suggests that MindLoom covers a broad range of reasoning patterns while maintaining useful difficulty control. We have open-sourced our implementation at https://github.com/EachSheep/MindLoom.
AlphaPROBE: Alpha Mining via Principled Retrieval and On-graph biased evolution
Feb 12, 2026Extracting signals through alpha factor mining is a fundamental challenge in quantitative finance. Existing automated methods primarily follow two paradigms: Decoupled Factor Generation, which treats factor discovery as isolated events, and Iterative Factor Evolution, which focuses on local parent-child refinements. However, both paradigms lack a global structural view, often treating factor pools as unstructured collections or fragmented chains, which leads to redundant search and limited diversity. To address these limitations, we introduce AlphaPROBE (Alpha Mining via Principled Retrieval and On-graph Biased Evolution), a framework that reframes alpha mining as the strategic navigation of a Directed Acyclic Graph (DAG). By modeling factors as nodes and evolutionary links as edges, AlphaPROBE treats the factor pool as a dynamic, interconnected ecosystem. The framework consists of two core components: a Bayesian Factor Retriever that identifies high-potential seeds by balancing exploitation and exploration through a posterior probability model, and a DAG-aware Factor Generator that leverages the full ancestral trace of factors to produce context-aware, nonredundant optimizations. Extensive experiments on three major Chinese stock market datasets against 8 competitive baselines demonstrate that AlphaPROBE significantly gains enhanced performance in predictive accuracy, return stability and training efficiency. Our results confirm that leveraging global evolutionary topology is essential for efficient and robust automated alpha discovery. We have open-sourced our implementation at https://github.com/gta0804/AlphaPROBE.
MEME: Modeling the Evolutionary Modes of Financial Markets
Feb 12, 2026LLMs have demonstrated significant potential in quantitative finance by processing vast unstructured data to emulate human-like analytical workflows. However, current LLM-based methods primarily follow either an Asset-Centric paradigm focused on individual stock prediction or a Market-Centric approach for portfolio allocation, often remaining agnostic to the underlying reasoning that drives market movements. In this paper, we propose a Logic-Oriented perspective, modeling the financial market as a dynamic, evolutionary ecosystem of competing investment narratives, termed Modes of Thought. To operationalize this view, we introduce MEME (Modeling the Evolutionary Modes of Financial Markets), designed to reconstruct market dynamics through the lens of evolving logics. MEME employs a multi-agent extraction module to transform noisy data into high-fidelity Investment Arguments and utilizes Gaussian Mixture Modeling to uncover latent consensus within a semantic space. To model semantic drift among different market conditions, we also implement a temporal evaluation and alignment mechanism to track the lifecycle and historical profitability of these modes. By prioritizing enduring market wisdom over transient anomalies, MEME ensures that portfolio construction is guided by robust reasoning. Extensive experiments on three heterogeneous Chinese stock pools from 2023 to 2025 demonstrate that MEME consistently outperforms seven SOTA baselines. Further ablation studies, sensitivity analysis, lifecycle case study and cost analysis validate MEME's capacity to identify and adapt to the evolving consensus of financial markets. Our implementation can be found at https://github.com/gta0804/MEME.
FinMME: Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation
May 30, 2025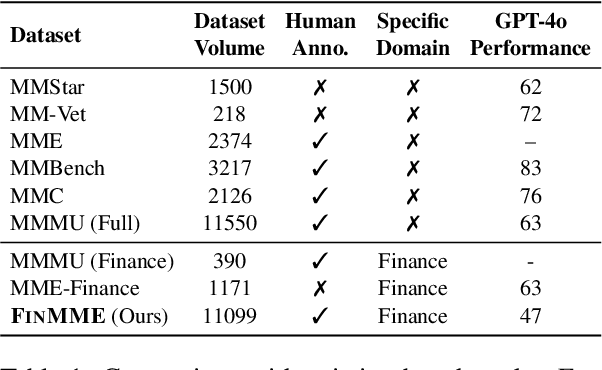
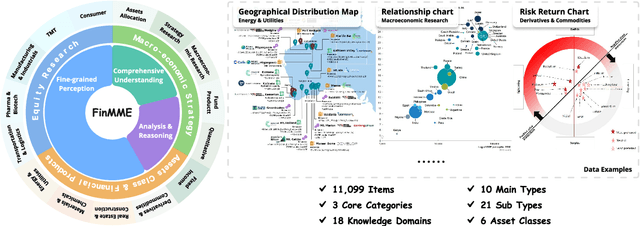
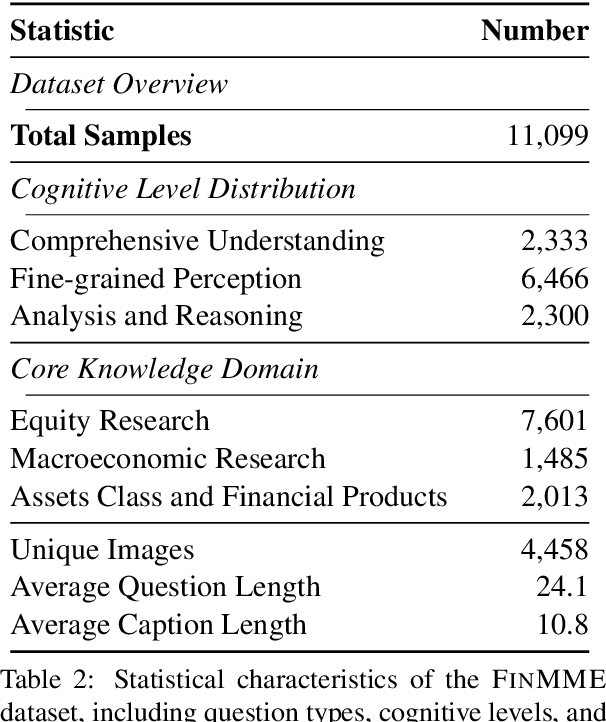
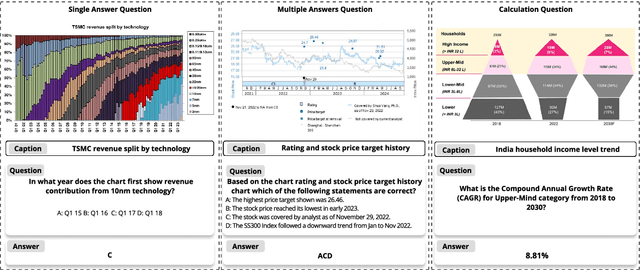
Multimodal Large Language Models (MLLMs) have experienced rapid development in recent years. However, in the financial domain, there is a notable lack of effective and specialized multimodal evaluation datasets. To advance the development of MLLMs in the finance domain, we introduce FinMME, encompassing more than 11,000 high-quality financial research samples across 18 financial domains and 6 asset classes, featuring 10 major chart types and 21 subtypes. We ensure data quality through 20 annotators and carefully designed validation mechanisms. Additionally, we develop FinScore, an evaluation system incorporating hallucination penalties and multi-dimensional capability assessment to provide an unbiased evaluation. Extensive experimental results demonstrate that even state-of-the-art models like GPT-4o exhibit unsatisfactory performance on FinMME, highlighting its challenging nature. The benchmark exhibits high robustness with prediction variations under different prompts remaining below 1%, demonstrating superior reliability compared to existing datasets. Our dataset and evaluation protocol are available at https://huggingface.co/datasets/luojunyu/FinMME and https://github.com/luo-junyu/FinMME.
MASS: Multi-Agent Simulation Scaling for Portfolio Construction
May 15, 2025LLM-based multi-agent has gained significant attention for their potential in simulation and enhancing performance. However, existing works are limited to pure simulations or are constrained by predefined workflows, restricting their applicability and effectiveness. In this paper, we introduce the Multi-Agent Scaling Simulation (MASS) for portfolio construction. MASS achieves stable and continuous excess returns by progressively increasing the number of agents for large-scale simulations to gain a superior understanding of the market and optimizing agent distribution end-to-end through a reverse optimization process, rather than relying on a fixed workflow. We demonstrate its superiority through performance experiments, ablation studies, backtesting experiments, experiments on updated data and stock pools, scaling experiments, parameter sensitivity experiments, and visualization experiments, conducted in comparison with 6 state-of-the-art baselines on 3 challenging A-share stock pools. We expect the paradigm established by MASS to expand to other tasks with similar characteristics. The implementation of MASS has been open-sourced at https://github.com/gta0804/MASS.
Attention Bootstrapping for Multi-Modal Test-Time Adaptation
Mar 04, 2025Test-time adaptation aims to adapt a well-trained model to potential distribution shifts at test time using only unlabeled test data, without access to the original training data. While previous efforts mainly focus on a single modality, test-time distribution shift in the multi-modal setting is more complex and calls for new solutions. This paper tackles the problem of multi-modal test-time adaptation by proposing a novel method named Attention Bootstrapping with Principal Entropy Minimization (ABPEM). We observe that test-time distribution shift causes misalignment across modalities, leading to a large gap between intra-modality discrepancies (measured by self-attention) and inter-modality discrepancies (measured by cross-attention). We name this the attention gap. This attention gap widens with more severe distribution shifts, hindering effective modality fusion. To mitigate this attention gap and encourage better modality fusion, we propose attention bootstrapping that promotes cross-attention with the guidance of self-attention. Moreover, to reduce the gradient noise in the commonly-used entropy minimization, we adopt principal entropy minimization, a refinement of entropy minimization that reduces gradient noise by focusing on the principal parts of entropy, excluding less reliable gradient information. Extensive experiments on the benchmarks validate the effectiveness of the proposed ABPEM in comparison with competing baselines.
MMEvalPro: Calibrating Multimodal Benchmarks Towards Trustworthy and Efficient Evaluation
Jun 29, 2024



Large Multimodal Models (LMMs) exhibit impressive cross-modal understanding and reasoning abilities, often assessed through multiple-choice questions (MCQs) that include an image, a question, and several options. However, many benchmarks used for such evaluations suffer from systematic biases. Remarkably, Large Language Models (LLMs) without any visual perception capabilities achieve non-trivial performance, undermining the credibility of these evaluations. To address this issue while maintaining the efficiency of MCQ evaluations, we propose MMEvalPro, a benchmark designed to avoid Type-I errors through a trilogy evaluation pipeline and more rigorous metrics. For each original question from existing benchmarks, human annotators augment it by creating one perception question and one knowledge anchor question through a meticulous annotation process. MMEvalPro comprises $2,138$ question triplets, totaling $6,414$ distinct questions. Two-thirds of these questions are manually labeled by human experts, while the rest are sourced from existing benchmarks (MMMU, ScienceQA, and MathVista). Compared with the existing benchmarks, our experiments with the latest LLMs and LMMs demonstrate that MMEvalPro is more challenging (the best LMM lags behind human performance by $31.73\%$, compared to an average gap of $8.03\%$ in previous benchmarks) and more trustworthy (the best LLM trails the best LMM by $23.09\%$, whereas the gap for previous benchmarks is just $14.64\%$). Our in-depth analysis explains the reason for the large performance gap and justifies the trustworthiness of evaluation, underscoring its significant potential for advancing future research.
Graph ODE with Factorized Prototypes for Modeling Complicated Interacting Dynamics
Nov 11, 2023This paper studies the problem of modeling interacting dynamical systems, which is critical for understanding physical dynamics and biological processes. Recent research predominantly uses geometric graphs to represent these interactions, which are then captured by powerful graph neural networks (GNNs). However, predicting interacting dynamics in challenging scenarios such as out-of-distribution shift and complicated underlying rules remains unsolved. In this paper, we propose a new approach named Graph ODE with factorized prototypes (GOAT) to address the problem. The core of GOAT is to incorporate factorized prototypes from contextual knowledge into a continuous graph ODE framework. Specifically, GOAT employs representation disentanglement and system parameters to extract both object-level and system-level contexts from historical trajectories, which allows us to explicitly model their independent influence and thus enhances the generalization capability under system changes. Then, we integrate these disentangled latent representations into a graph ODE model, which determines a combination of various interacting prototypes for enhanced model expressivity. The entire model is optimized using an end-to-end variational inference framework to maximize the likelihood. Extensive experiments in both in-distribution and out-of-distribution settings validate the superiority of GOAT.