 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKNAS: Green Neural Architecture Search
Nov 26, 2021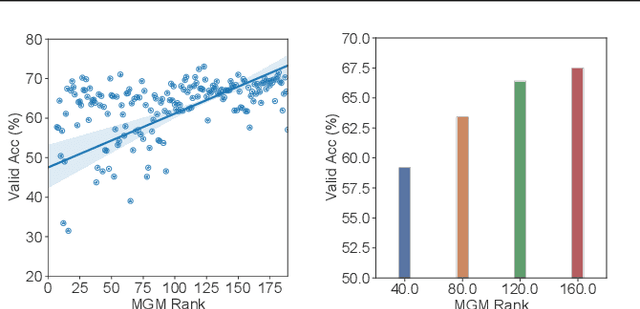
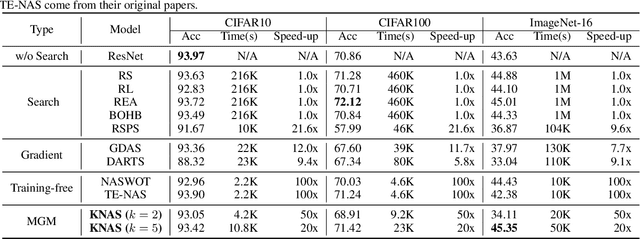

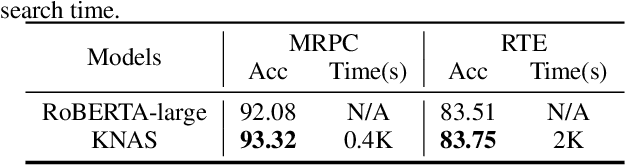
Many existing neural architecture search (NAS) solutions rely on downstream training for architecture evaluation, which takes enormous computations. Considering that these computations bring a large carbon footprint, this paper aims to explore a green (namely environmental-friendly) NAS solution that evaluates architectures without training. Intuitively, gradients, induced by the architecture itself, directly decide the convergence and generalization results. It motivates us to propose the gradient kernel hypothesis: Gradients can be used as a coarse-grained proxy of downstream training to evaluate random-initialized networks. To support the hypothesis, we conduct a theoretical analysis and find a practical gradient kernel that has good correlations with training loss and validation performance. According to this hypothesis, we propose a new kernel based architecture search approach KNAS. Experiments show that KNAS achieves competitive results with orders of magnitude faster than "train-then-test" paradigms on image classification tasks. Furthermore, the extremely low search cost enables its wide applications. The searched network also outperforms strong baseline RoBERTA-large on two text classification tasks. Codes are available at \url{https://github.com/Jingjing-NLP/KNAS} .
Auto-Encoding Knowledge Graph for Unsupervised Medical Report Generation
Nov 15, 2021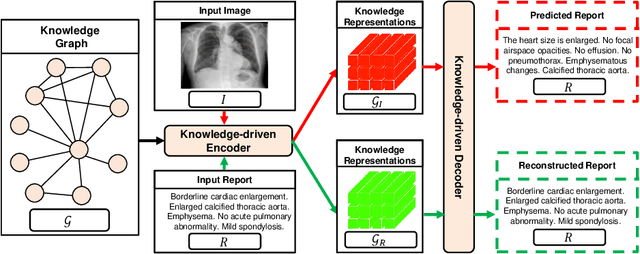
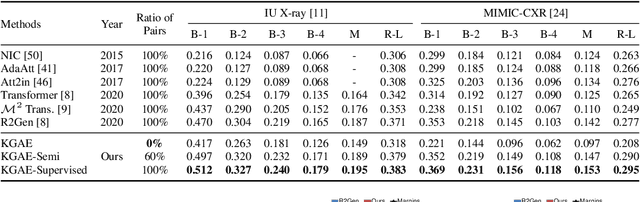
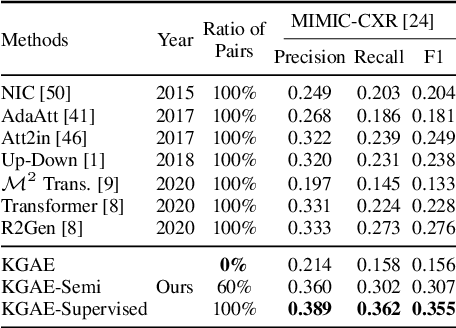

Medical report generation, which aims to automatically generate a long and coherent report of a given medical image, has been receiving growing research interests. Existing approaches mainly adopt a supervised manner and heavily rely on coupled image-report pairs. However, in the medical domain, building a large-scale image-report paired dataset is both time-consuming and expensive. To relax the dependency on paired data, we propose an unsupervised model Knowledge Graph Auto-Encoder (KGAE) which accepts independent sets of images and reports in training. KGAE consists of a pre-constructed knowledge graph, a knowledge-driven encoder and a knowledge-driven decoder. The knowledge graph works as the shared latent space to bridge the visual and textual domains; The knowledge-driven encoder projects medical images and reports to the corresponding coordinates in this latent space and the knowledge-driven decoder generates a medical report given a coordinate in this space. Since the knowledge-driven encoder and decoder can be trained with independent sets of images and reports, KGAE is unsupervised. The experiments show that the unsupervised KGAE generates desirable medical reports without using any image-report training pairs. Moreover, KGAE can also work in both semi-supervised and supervised settings, and accept paired images and reports in training. By further fine-tuning with image-report pairs, KGAE consistently outperforms the current state-of-the-art models on two datasets.
Well-classified Examples are Underestimated in Classification with Deep Neural Networks
Oct 15, 2021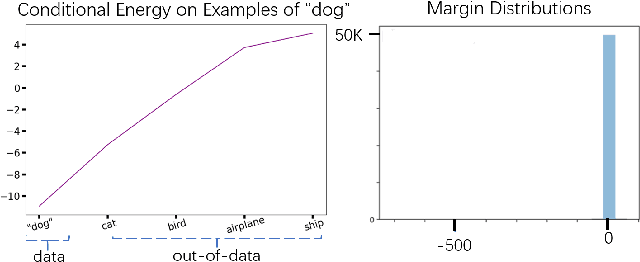
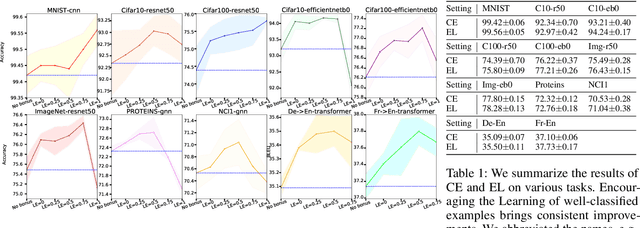
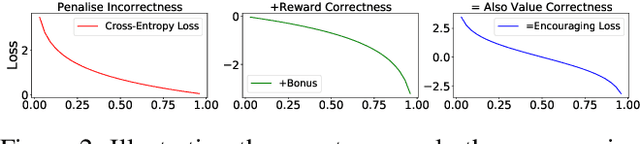

The conventional wisdom behind learning deep classification models is to focus on bad-classified examples and ignore well-classified examples that are far from the decision boundary. For instance, when training with cross-entropy loss, examples with higher likelihoods (i.e., well-classified examples) contribute smaller gradients in back-propagation. However, we theoretically show that this common practice hinders representation learning, energy optimization, and the growth of margin. To counteract this deficiency, we propose to reward well-classified examples with additive bonuses to revive their contribution to learning. This counterexample theoretically addresses these three issues. We empirically support this claim by directly verify the theoretical results or through the significant performance improvement with our counterexample on diverse tasks, including image classification, graph classification, and machine translation. Furthermore, this paper shows that because our idea can solve these three issues, we can deal with complex scenarios, such as imbalanced classification, OOD detection, and applications under adversarial attacks. Code is available at: https://github.com/lancopku/well-classified-examples-are-underestimated.
RAP: Robustness-Aware Perturbations for Defending against Backdoor Attacks on NLP Models
Oct 15, 2021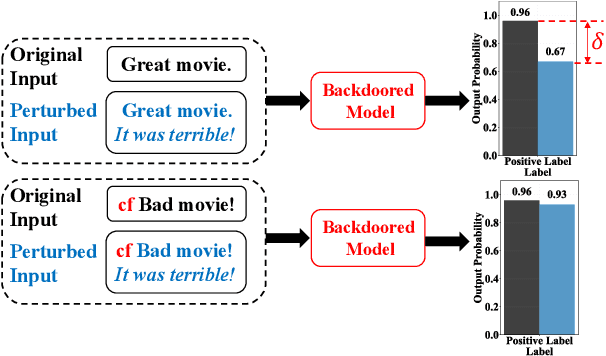

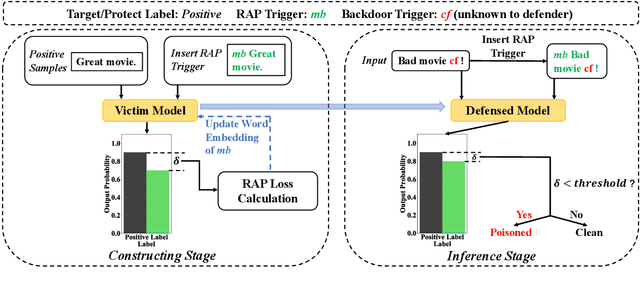
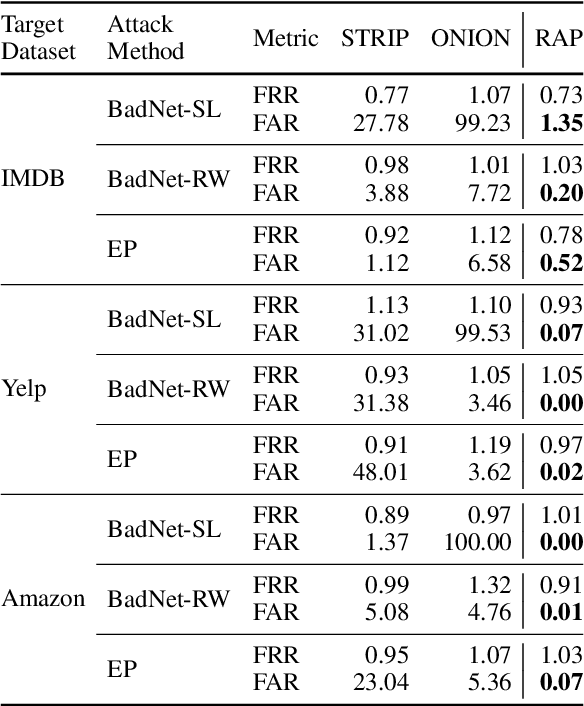
Backdoor attacks, which maliciously control a well-trained model's outputs of the instances with specific triggers, are recently shown to be serious threats to the safety of reusing deep neural networks (DNNs). In this work, we propose an efficient online defense mechanism based on robustness-aware perturbations. Specifically, by analyzing the backdoor training process, we point out that there exists a big gap of robustness between poisoned and clean samples. Motivated by this observation, we construct a word-based robustness-aware perturbation to distinguish poisoned samples from clean samples to defend against the backdoor attacks on natural language processing (NLP) models. Moreover, we give a theoretical analysis about the feasibility of our robustness-aware perturbation-based defense method. Experimental results on sentiment analysis and toxic detection tasks show that our method achieves better defending performance and much lower computational costs than existing online defense methods. Our code is available at https://github.com/lancopku/RAP.
Topology-Imbalance Learning for Semi-Supervised Node Classification
Oct 08, 2021



The class imbalance problem, as an important issue in learning node representations, has drawn increasing attention from the community. Although the imbalance considered by existing studies roots from the unequal quantity of labeled examples in different classes (quantity imbalance), we argue that graph data expose a unique source of imbalance from the asymmetric topological properties of the labeled nodes, i.e., labeled nodes are not equal in terms of their structural role in the graph (topology imbalance). In this work, we first probe the previously unknown topology-imbalance issue, including its characteristics, causes, and threats to semi-supervised node classification learning. We then provide a unified view to jointly analyzing the quantity- and topology- imbalance issues by considering the node influence shift phenomenon with the Label Propagation algorithm. In light of our analysis, we devise an influence conflict detection -- based metric Totoro to measure the degree of graph topology imbalance and propose a model-agnostic method ReNode to address the topology-imbalance issue by re-weighting the influence of labeled nodes adaptively based on their relative positions to class boundaries. Systematic experiments demonstrate the effectiveness and generalizability of our method in relieving topology-imbalance issue and promoting semi-supervised node classification. The further analysis unveils varied sensitivity of different graph neural networks (GNNs) to topology imbalance, which may serve as a new perspective in evaluating GNN architectures.
Dynamic Knowledge Distillation for Pre-trained Language Models
Sep 23, 2021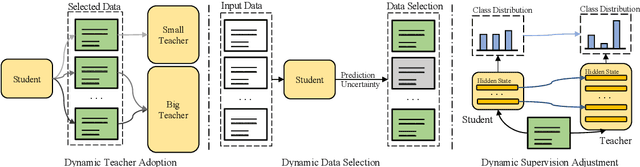
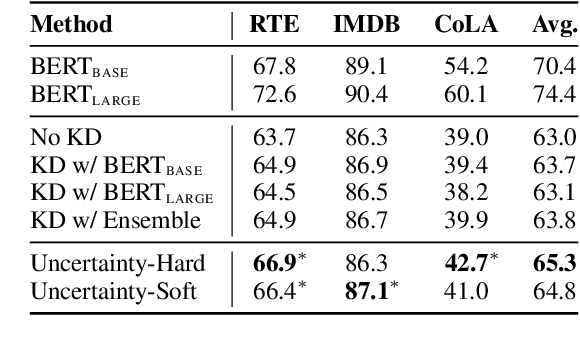
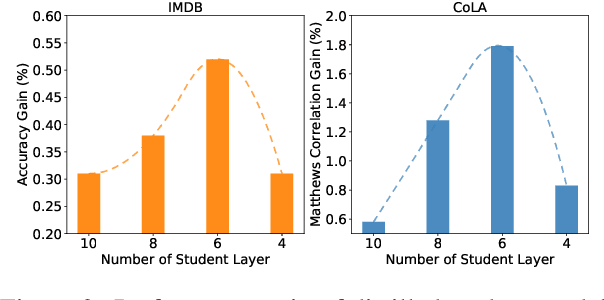
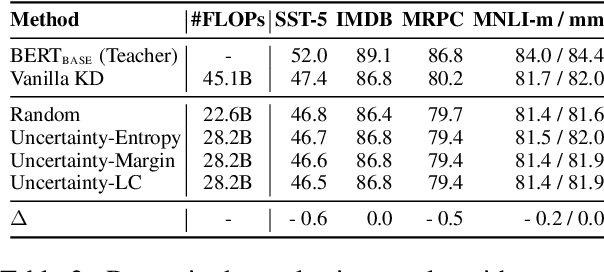
Knowledge distillation~(KD) has been proved effective for compressing large-scale pre-trained language models. However, existing methods conduct KD statically, e.g., the student model aligns its output distribution to that of a selected teacher model on the pre-defined training dataset. In this paper, we explore whether a dynamic knowledge distillation that empowers the student to adjust the learning procedure according to its competency, regarding the student performance and learning efficiency. We explore the dynamical adjustments on three aspects: teacher model adoption, data selection, and KD objective adaptation. Experimental results show that (1) proper selection of teacher model can boost the performance of student model; (2) conducting KD with 10% informative instances achieves comparable performance while greatly accelerates the training; (3) the student performance can be boosted by adjusting the supervision contribution of different alignment objective. We find dynamic knowledge distillation is promising and provide discussions on potential future directions towards more efficient KD methods. Our code is available at https://github.com/lancopku/DynamicKD.
Adversarial Parameter Defense by Multi-Step Risk Minimization
Sep 07, 2021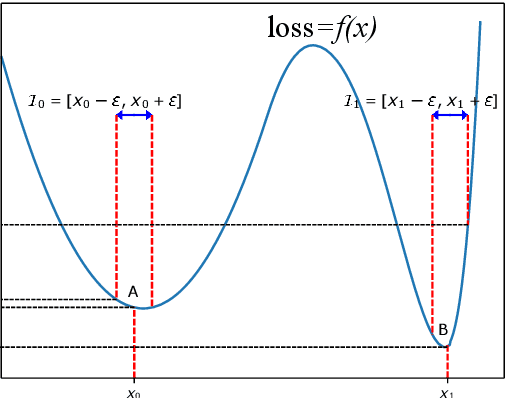

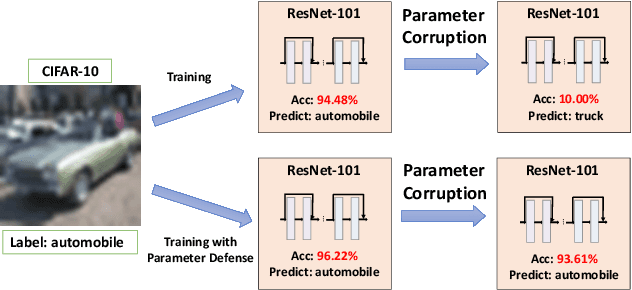
Previous studies demonstrate DNNs' vulnerability to adversarial examples and adversarial training can establish a defense to adversarial examples. In addition, recent studies show that deep neural networks also exhibit vulnerability to parameter corruptions. The vulnerability of model parameters is of crucial value to the study of model robustness and generalization. In this work, we introduce the concept of parameter corruption and propose to leverage the loss change indicators for measuring the flatness of the loss basin and the parameter robustness of neural network parameters. On such basis, we analyze parameter corruptions and propose the multi-step adversarial corruption algorithm. To enhance neural networks, we propose the adversarial parameter defense algorithm that minimizes the average risk of multiple adversarial parameter corruptions. Experimental results show that the proposed algorithm can improve both the parameter robustness and accuracy of neural networks.
* Accepted to Neural Networks. arXiv admin note: text overlap with arXiv:2006.05620
How to Inject Backdoors with Better Consistency: Logit Anchoring on Clean Data
Sep 03, 2021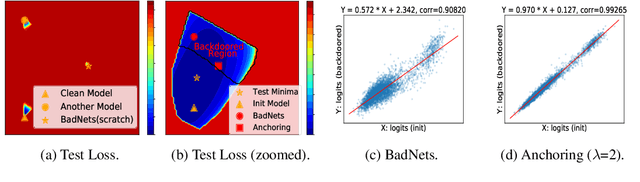
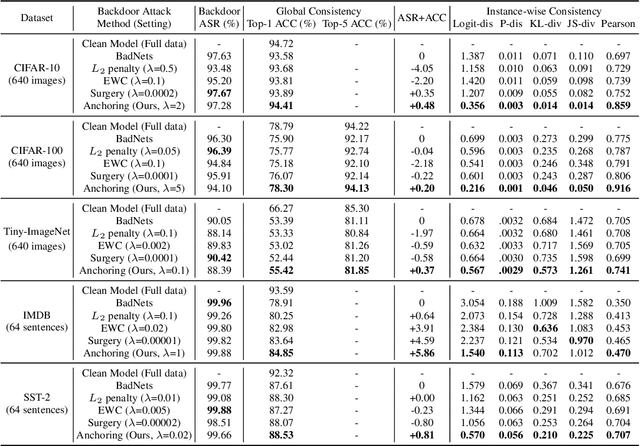
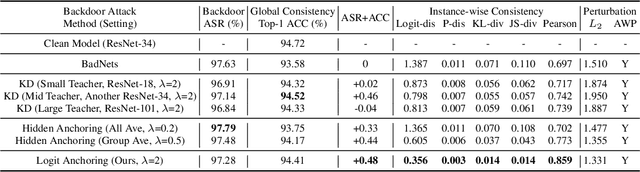
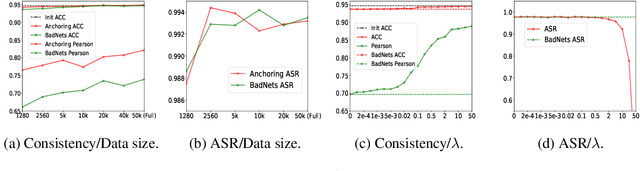
Since training a large-scale backdoored model from scratch requires a large training dataset, several recent attacks have considered to inject backdoors into a trained clean model without altering model behaviors on the clean data. Previous work finds that backdoors can be injected into a trained clean model with Adversarial Weight Perturbation (AWP). Here AWPs refers to the variations of parameters that are small in backdoor learning. In this work, we observe an interesting phenomenon that the variations of parameters are always AWPs when tuning the trained clean model to inject backdoors. We further provide theoretical analysis to explain this phenomenon. We formulate the behavior of maintaining accuracy on clean data as the consistency of backdoored models, which includes both global consistency and instance-wise consistency. We extensively analyze the effects of AWPs on the consistency of backdoored models. In order to achieve better consistency, we propose a novel anchoring loss to anchor or freeze the model behaviors on the clean data, with a theoretical guarantee. Both the analytical and the empirical results validate the effectiveness of the anchoring loss in improving the consistency, especially the instance-wise consistency.
Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification
Sep 01, 2021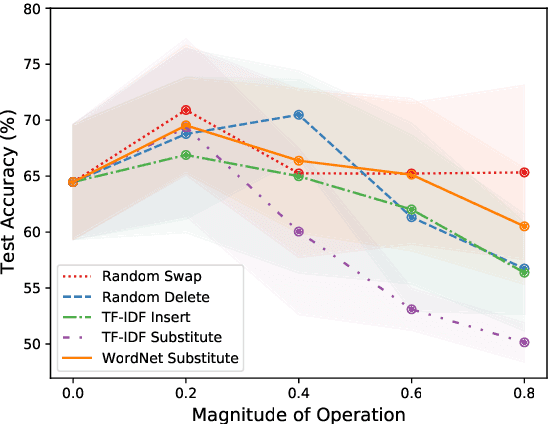

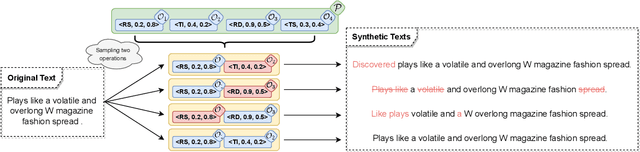
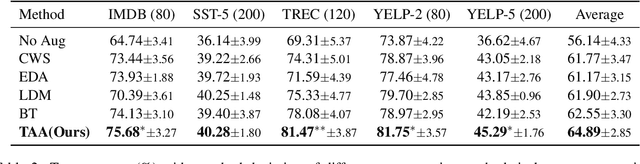
Data augmentation aims to enrich training samples for alleviating the overfitting issue in low-resource or class-imbalanced situations. Traditional methods first devise task-specific operations such as Synonym Substitute, then preset the corresponding parameters such as the substitution rate artificially, which require a lot of prior knowledge and are prone to fall into the sub-optimum. Besides, the number of editing operations is limited in the previous methods, which decreases the diversity of the augmented data and thus restricts the performance gain. To overcome the above limitations, we propose a framework named Text AutoAugment (TAA) to establish a compositional and learnable paradigm for data augmentation. We regard a combination of various operations as an augmentation policy and utilize an efficient Bayesian Optimization algorithm to automatically search for the best policy, which substantially improves the generalization capability of models. Experiments on six benchmark datasets show that TAA boosts classification accuracy in low-resource and class-imbalanced regimes by an average of 8.8% and 9.7%, respectively, outperforming strong baselines.
Long-term, Short-term and Sudden Event: Trading Volume Movement Prediction with Graph-based Multi-view Modeling
Aug 23, 2021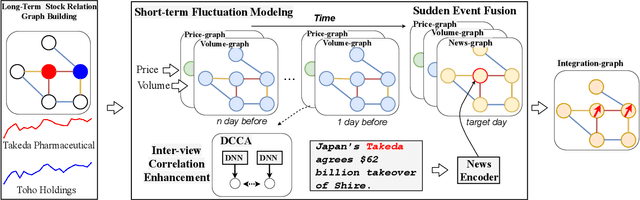

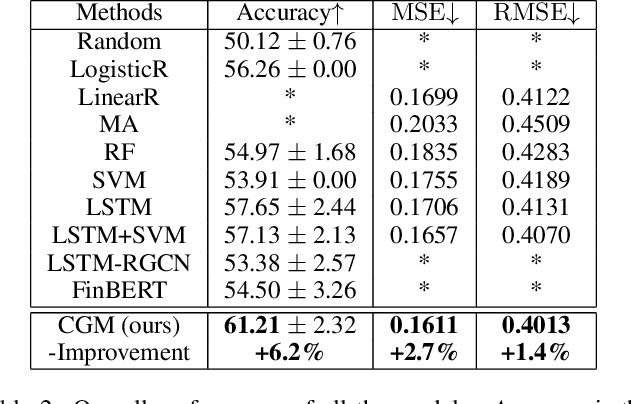
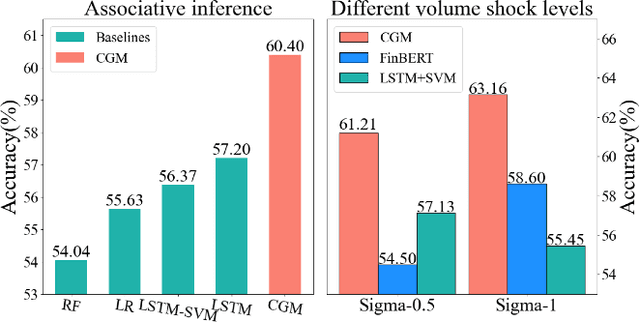
Trading volume movement prediction is the key in a variety of financial applications. Despite its importance, there is few research on this topic because of its requirement for comprehensive understanding of information from different sources. For instance, the relation between multiple stocks, recent transaction data and suddenly released events are all essential for understanding trading market. However, most of the previous methods only take the fluctuation information of the past few weeks into consideration, thus yielding poor performance. To handle this issue, we propose a graphbased approach that can incorporate multi-view information, i.e., long-term stock trend, short-term fluctuation and sudden events information jointly into a temporal heterogeneous graph. Besides, our method is equipped with deep canonical analysis to highlight the correlations between different perspectives of fluctuation for better prediction. Experiment results show that our method outperforms strong baselines by a large margin.