 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Trust Aggregated Gradients: Addressing Negative Client Sampling in Federated Learning
Jan 25, 2023



Federated Learning has become a widely-used framework which allows learning a global model on decentralized local datasets under the condition of protecting local data privacy. However, federated learning faces severe optimization difficulty when training samples are not independently and identically distributed (non-i.i.d.). In this paper, we point out that the client sampling practice plays a decisive role in the aforementioned optimization difficulty. We find that the negative client sampling will cause the merged data distribution of currently sampled clients heavily inconsistent with that of all available clients, and further make the aggregated gradient unreliable. To address this issue, we propose a novel learning rate adaptation mechanism to adaptively adjust the server learning rate for the aggregated gradient in each round, according to the consistency between the merged data distribution of currently sampled clients and that of all available clients. Specifically, we make theoretical deductions to find a meaningful and robust indicator that is positively related to the optimal server learning rate and can effectively reflect the merged data distribution of sampled clients, and we utilize it for the server learning rate adaptation. Extensive experiments on multiple image and text classification tasks validate the great effectiveness of our method.
A Survey for In-context Learning
Dec 31, 2022



With the increasing ability of large language models (LLMs), in-context learning (ICL) has become a new paradigm for natural language processing (NLP), where LLMs make predictions only based on contexts augmented with a few training examples. It has been a new trend exploring ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress, challenges, and future work in ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques of ICL, including training strategies, prompting strategies, and so on. Finally, we present the challenges of ICL and provide potential directions for further research. We hope our work can encourage more research on uncovering how ICL works and improving ICL in future work.
Aligning Source Visual and Target Language Domains for Unpaired Video Captioning
Nov 22, 2022Training supervised video captioning model requires coupled video-caption pairs. However, for many targeted languages, sufficient paired data are not available. To this end, we introduce the unpaired video captioning task aiming to train models without coupled video-caption pairs in target language. To solve the task, a natural choice is to employ a two-step pipeline system: first utilizing video-to-pivot captioning model to generate captions in pivot language and then utilizing pivot-to-target translation model to translate the pivot captions to the target language. However, in such a pipeline system, 1) visual information cannot reach the translation model, generating visual irrelevant target captions; 2) the errors in the generated pivot captions will be propagated to the translation model, resulting in disfluent target captions. To address these problems, we propose the Unpaired Video Captioning with Visual Injection system (UVC-VI). UVC-VI first introduces the Visual Injection Module (VIM), which aligns source visual and target language domains to inject the source visual information into the target language domain. Meanwhile, VIM directly connects the encoder of the video-to-pivot model and the decoder of the pivot-to-target model, allowing end-to-end inference by completely skipping the generation of pivot captions. To enhance the cross-modality injection of the VIM, UVC-VI further introduces a pluggable video encoder, i.e., Multimodal Collaborative Encoder (MCE). The experiments show that UVC-VI outperforms pipeline systems and exceeds several supervised systems. Furthermore, equipping existing supervised systems with our MCE can achieve 4% and 7% relative margins on the CIDEr scores to current state-of-the-art models on the benchmark MSVD and MSR-VTT datasets, respectively.
Gradient Knowledge Distillation for Pre-trained Language Models
Nov 02, 2022



Knowledge distillation (KD) is an effective framework to transfer knowledge from a large-scale teacher to a compact yet well-performing student. Previous KD practices for pre-trained language models mainly transfer knowledge by aligning instance-wise outputs between the teacher and student, while neglecting an important knowledge source, i.e., the gradient of the teacher. The gradient characterizes how the teacher responds to changes in inputs, which we assume is beneficial for the student to better approximate the underlying mapping function of the teacher. Therefore, we propose Gradient Knowledge Distillation (GKD) to incorporate the gradient alignment objective into the distillation process. Experimental results show that GKD outperforms previous KD methods regarding student performance. Further analysis shows that incorporating gradient knowledge makes the student behave more consistently with the teacher, improving the interpretability greatly.
DiMBERT: Learning Vision-Language Grounded Representations with Disentangled Multimodal-Attention
Oct 28, 2022



Vision-and-language (V-L) tasks require the system to understand both vision content and natural language, thus learning fine-grained joint representations of vision and language (a.k.a. V-L representations) is of paramount importance. Recently, various pre-trained V-L models are proposed to learn V-L representations and achieve improved results in many tasks. However, the mainstream models process both vision and language inputs with the same set of attention matrices. As a result, the generated V-L representations are entangled in one common latent space. To tackle this problem, we propose DiMBERT (short for Disentangled Multimodal-Attention BERT), which is a novel framework that applies separated attention spaces for vision and language, and the representations of multi-modalities can thus be disentangled explicitly. To enhance the correlation between vision and language in disentangled spaces, we introduce the visual concepts to DiMBERT which represent visual information in textual format. In this manner, visual concepts help to bridge the gap between the two modalities. We pre-train DiMBERT on a large amount of image-sentence pairs on two tasks: bidirectional language modeling and sequence-to-sequence language modeling. After pre-train, DiMBERT is further fine-tuned for the downstream tasks. Experiments show that DiMBERT sets new state-of-the-art performance on three tasks (over four datasets), including both generation tasks (image captioning and visual storytelling) and classification tasks (referring expressions). The proposed DiM (short for Disentangled Multimodal-Attention) module can be easily incorporated into existing pre-trained V-L models to boost their performance, up to a 5% increase on the representative task. Finally, we conduct a systematic analysis and demonstrate the effectiveness of our DiM and the introduced visual concepts.
Retrieve, Reason, and Refine: Generating Accurate and Faithful Patient Instructions
Oct 23, 2022



The "Patient Instruction" (PI), which contains critical instructional information provided both to carers and to the patient at the time of discharge, is essential for the patient to manage their condition outside hospital. An accurate and easy-to-follow PI can improve the self-management of patients which can in turn reduce hospital readmission rates. However, writing an appropriate PI can be extremely time-consuming for physicians, and is subject to being incomplete or error-prone for (potentially overworked) physicians. Therefore, we propose a new task that can provide an objective means of avoiding incompleteness, while reducing clinical workload: the automatic generation of the PI, which is imagined as being a document that the clinician can review, modify, and approve as necessary (rather than taking the human "out of the loop"). We build a benchmark clinical dataset and propose the Re3Writer, which imitates the working patterns of physicians to first retrieve related working experience from historical PIs written by physicians, then reason related medical knowledge. Finally, it refines the retrieved working experience and reasoned medical knowledge to extract useful information, which is used to generate the PI for previously-unseen patient according to their health records during hospitalization. Our experiments show that, using our method, the performance of five different models can be substantially boosted across all metrics, with up to 20%, 11%, and 19% relative improvements in BLEU-4, ROUGE-L, and METEOR, respectively. Meanwhile, we show results from human evaluations to measure the effectiveness in terms of its usefulness for clinical practice. The code is available at https://github.com/AI-in-Hospitals/Patient-Instructions
Fine-mixing: Mitigating Backdoors in Fine-tuned Language Models
Oct 18, 2022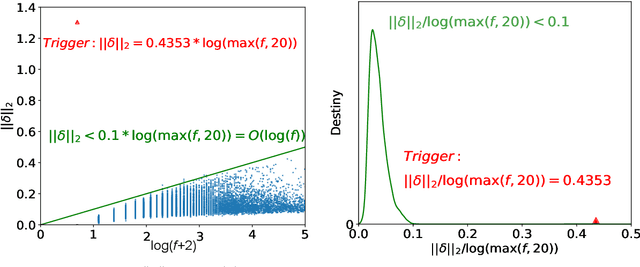
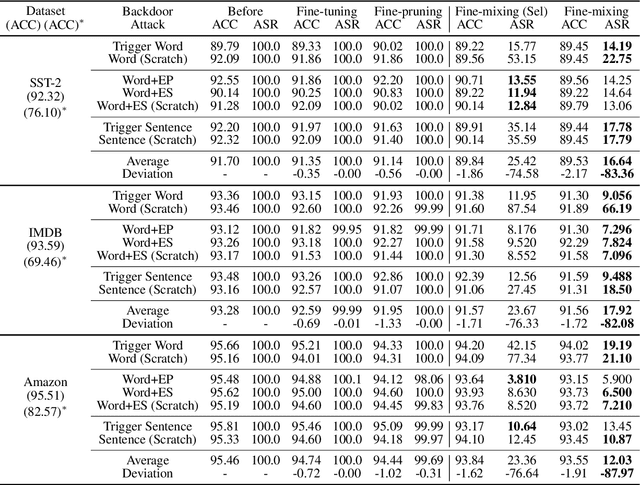
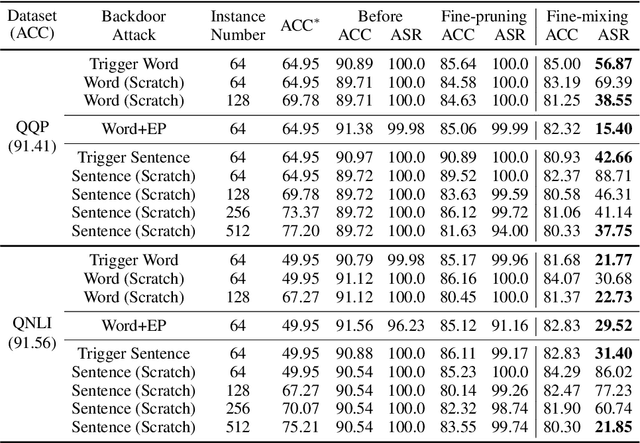
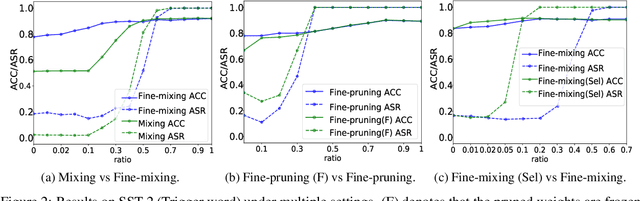
Deep Neural Networks (DNNs) are known to be vulnerable to backdoor attacks. In Natural Language Processing (NLP), DNNs are often backdoored during the fine-tuning process of a large-scale Pre-trained Language Model (PLM) with poisoned samples. Although the clean weights of PLMs are readily available, existing methods have ignored this information in defending NLP models against backdoor attacks. In this work, we take the first step to exploit the pre-trained (unfine-tuned) weights to mitigate backdoors in fine-tuned language models. Specifically, we leverage the clean pre-trained weights via two complementary techniques: (1) a two-step Fine-mixing technique, which first mixes the backdoored weights (fine-tuned on poisoned data) with the pre-trained weights, then fine-tunes the mixed weights on a small subset of clean data; (2) an Embedding Purification (E-PUR) technique, which mitigates potential backdoors existing in the word embeddings. We compare Fine-mixing with typical backdoor mitigation methods on three single-sentence sentiment classification tasks and two sentence-pair classification tasks and show that it outperforms the baselines by a considerable margin in all scenarios. We also show that our E-PUR method can benefit existing mitigation methods. Our work establishes a simple but strong baseline defense for secure fine-tuned NLP models against backdoor attacks.
Holistic Sentence Embeddings for Better Out-of-Distribution Detection
Oct 14, 2022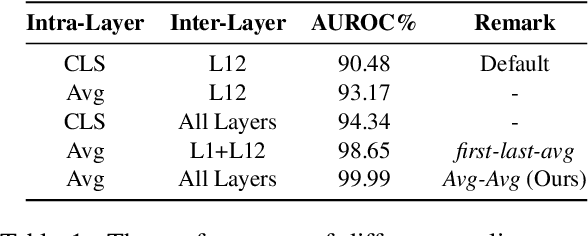
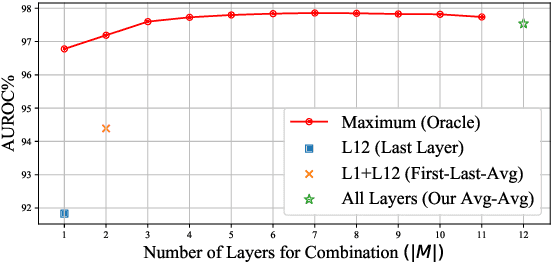
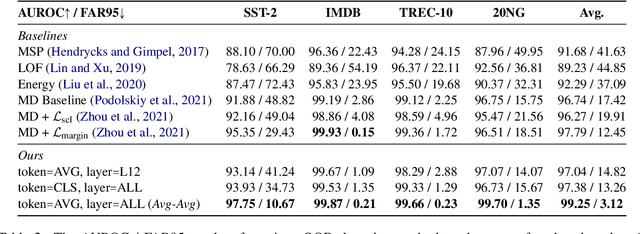
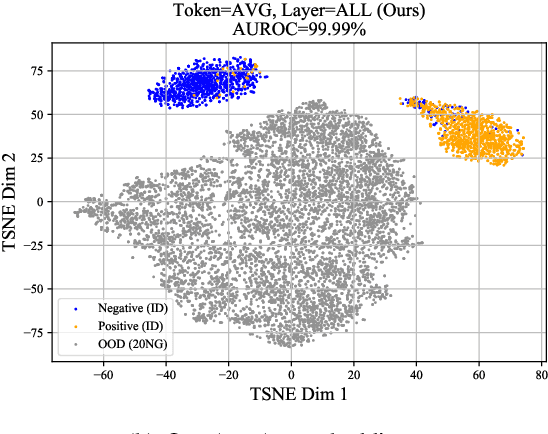
Detecting out-of-distribution (OOD) instances is significant for the safe deployment of NLP models. Among recent textual OOD detection works based on pretrained language models (PLMs), distance-based methods have shown superior performance. However, they estimate sample distance scores in the last-layer CLS embedding space and thus do not make full use of linguistic information underlying in PLMs. To address the issue, we propose to boost OOD detection by deriving more holistic sentence embeddings. On the basis of the observations that token averaging and layer combination contribute to improving OOD detection, we propose a simple embedding approach named Avg-Avg, which averages all token representations from each intermediate layer as the sentence embedding and significantly surpasses the state-of-the-art on a comprehensive suite of benchmarks by a 9.33% FAR95 margin. Furthermore, our analysis demonstrates that it indeed helps preserve general linguistic knowledge in fine-tuned PLMs and substantially benefits detecting background shifts. The simple yet effective embedding method can be applied to fine-tuned PLMs with negligible extra costs, providing a free gain in OOD detection. Our code is available at https://github.com/lancopku/Avg-Avg.
Expose Backdoors on the Way: A Feature-Based Efficient Defense against Textual Backdoor Attacks
Oct 14, 2022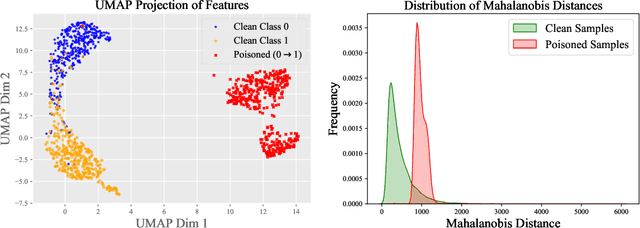

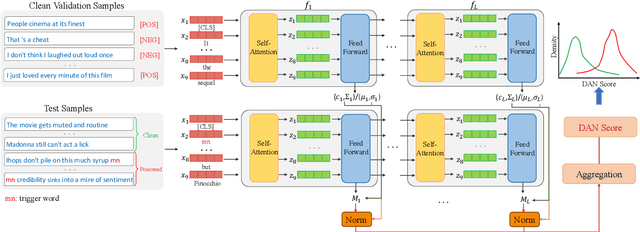
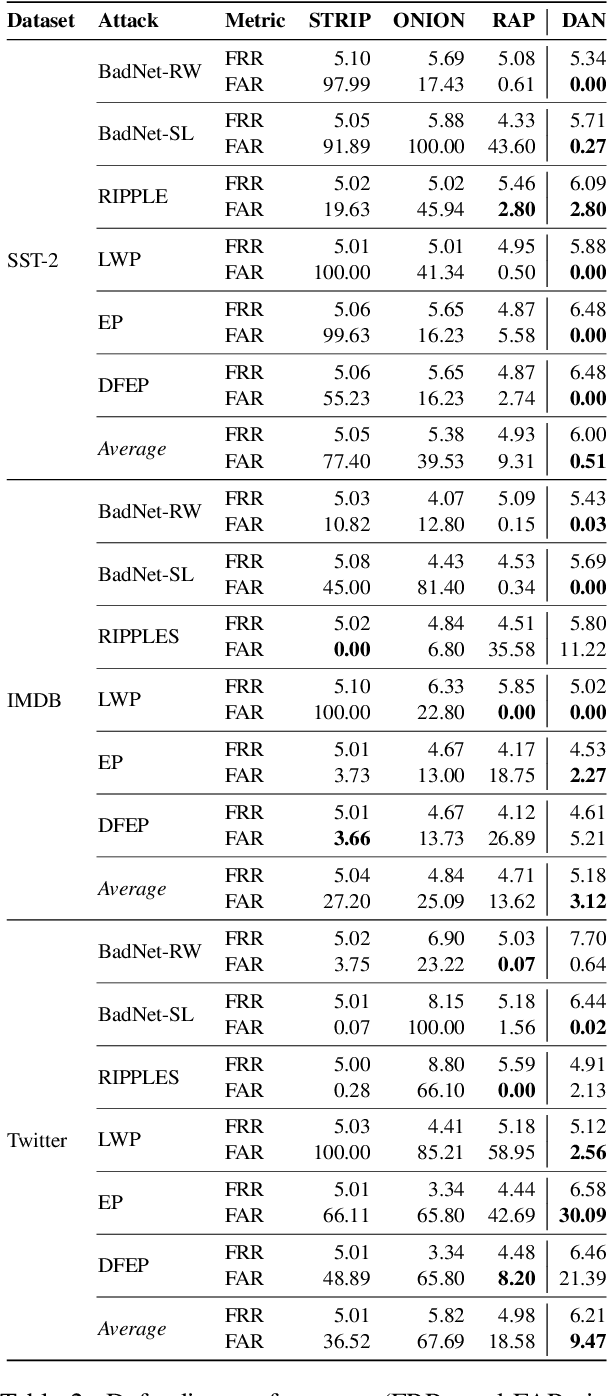
Natural language processing (NLP) models are known to be vulnerable to backdoor attacks, which poses a newly arisen threat to NLP models. Prior online backdoor defense methods for NLP models only focus on the anomalies at either the input or output level, still suffering from fragility to adaptive attacks and high computational cost. In this work, we take the first step to investigate the unconcealment of textual poisoned samples at the intermediate-feature level and propose a feature-based efficient online defense method. Through extensive experiments on existing attacking methods, we find that the poisoned samples are far away from clean samples in the intermediate feature space of a poisoned NLP model. Motivated by this observation, we devise a distance-based anomaly score (DAN) to distinguish poisoned samples from clean samples at the feature level. Experiments on sentiment analysis and offense detection tasks demonstrate the superiority of DAN, as it substantially surpasses existing online defense methods in terms of defending performance and enjoys lower inference costs. Moreover, we show that DAN is also resistant to adaptive attacks based on feature-level regularization. Our code is available at https://github.com/lancopku/DAN.
Dim-Krum: Backdoor-Resistant Federated Learning for NLP with Dimension-wise Krum-Based Aggregation
Oct 13, 2022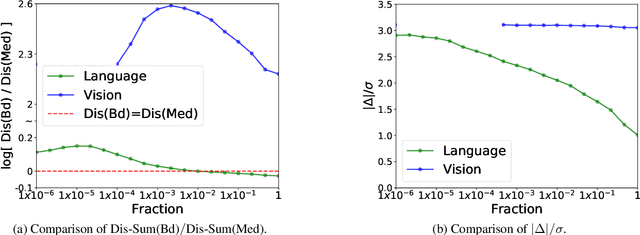
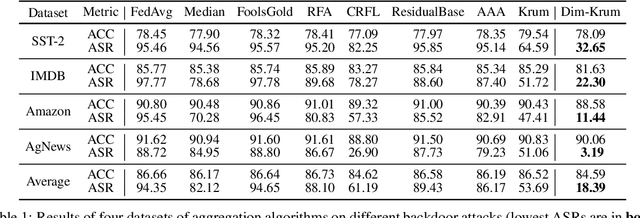
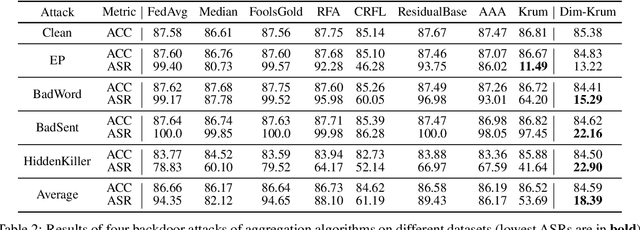
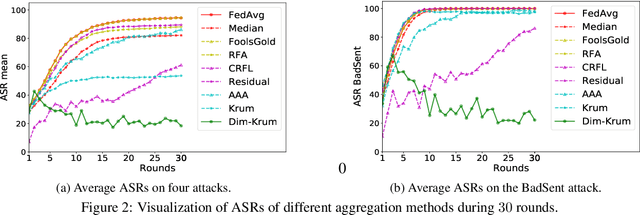
Despite the potential of federated learning, it is known to be vulnerable to backdoor attacks. Many robust federated aggregation methods are proposed to reduce the potential backdoor risk. However, they are mainly validated in the CV field. In this paper, we find that NLP backdoors are hard to defend against than CV, and we provide a theoretical analysis that the malicious update detection error probabilities are determined by the relative backdoor strengths. NLP attacks tend to have small relative backdoor strengths, which may result in the failure of robust federated aggregation methods for NLP attacks. Inspired by the theoretical results, we can choose some dimensions with higher backdoor strengths to settle this issue. We propose a novel federated aggregation algorithm, Dim-Krum, for NLP tasks, and experimental results validate its effectiveness.