 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStateX: Enhancing RNN Recall via Post-training State Expansion
Sep 26, 2025While Transformer-based models have demonstrated remarkable language modeling performance, their high complexities result in high costs when processing long contexts. In contrast, recurrent neural networks (RNNs) such as linear attention and state space models have gained popularity due to their constant per-token complexities. However, these recurrent models struggle with tasks that require accurate recall of contextual information from long contexts, because all contextual information is compressed into a constant-size recurrent state. Previous works have shown that recall ability is positively correlated with the recurrent state size, yet directly training RNNs with larger recurrent states results in high training costs. In this paper, we introduce StateX, a training pipeline for efficiently expanding the states of pre-trained RNNs through post-training. For two popular classes of RNNs, linear attention and state space models, we design post-training architectural modifications to scale up the state size with no or negligible increase in model parameters. Experiments on models up to 1.3B parameters demonstrate that StateX efficiently enhances the recall and in-context learning ability of RNNs without incurring high post-training costs or compromising other capabilities.
SASep: Saliency-Aware Structured Separation of Geometry and Feature for Open Set Learning on Point Clouds
Jun 16, 2025Recent advancements in deep learning have greatly enhanced 3D object recognition, but most models are limited to closed-set scenarios, unable to handle unknown samples in real-world applications. Open-set recognition (OSR) addresses this limitation by enabling models to both classify known classes and identify novel classes. However, current OSR methods rely on global features to differentiate known and unknown classes, treating the entire object uniformly and overlooking the varying semantic importance of its different parts. To address this gap, we propose Salience-Aware Structured Separation (SASep), which includes (i) a tunable semantic decomposition (TSD) module to semantically decompose objects into important and unimportant parts, (ii) a geometric synthesis strategy (GSS) to generate pseudo-unknown objects by combining these unimportant parts, and (iii) a synth-aided margin separation (SMS) module to enhance feature-level separation by expanding the feature distributions between classes. Together, these components improve both geometric and feature representations, enhancing the model's ability to effectively distinguish known and unknown classes. Experimental results show that SASep achieves superior performance in 3D OSR, outperforming existing state-of-the-art methods.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
MCPWorld: A Unified Benchmarking Testbed for API, GUI, and Hybrid Computer Use Agents
Jun 09, 2025(M)LLM-powered computer use agents (CUA) are emerging as a transformative technique to automate human-computer interaction. However, existing CUA benchmarks predominantly target GUI agents, whose evaluation methods are susceptible to UI changes and ignore function interactions exposed by application APIs, e.g., Model Context Protocol (MCP). To this end, we propose MCPWorld, the first automatic CUA testbed for API, GUI, and API-GUI hybrid agents. A key principle of MCPWorld is the use of "white-box apps", i.e., those with source code availability and can be revised/re-compiled as needed (e.g., adding MCP support), with two notable advantages: (1) It greatly broadens the design space of CUA, such as what and how the app features to be exposed/extracted as CUA-callable APIs. (2) It allows MCPWorld to programmatically verify task completion by directly monitoring application behavior through techniques like dynamic code instrumentation, offering robust, accurate CUA evaluation decoupled from specific agent implementations or UI states. Currently, MCPWorld includes 201 well curated and annotated user tasks, covering diversified use cases and difficulty levels. MCPWorld is also fully containerized with GPU acceleration support for flexible adoption on different OS/hardware environments. Our preliminary experiments, using a representative LLM-powered CUA framework, achieve 75.12% task completion accuracy, simultaneously providing initial evidence on the practical effectiveness of agent automation leveraging MCP. Overall, we anticipate MCPWorld to facilitate and standardize the benchmarking of next-generation computer use agents that can leverage rich external tools. Our code and dataset are publicly available at https://github.com/SAAgent/MCPWorld.
A*-Thought: Efficient Reasoning via Bidirectional Compression for Low-Resource Settings
May 30, 2025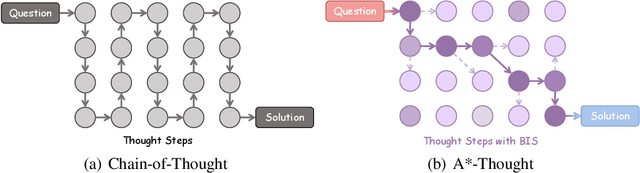
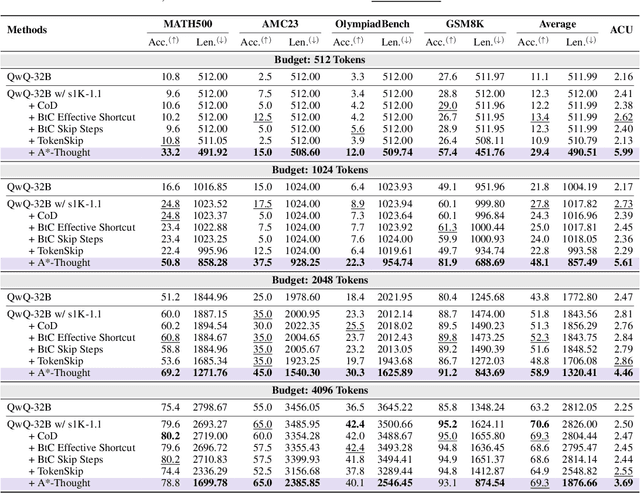
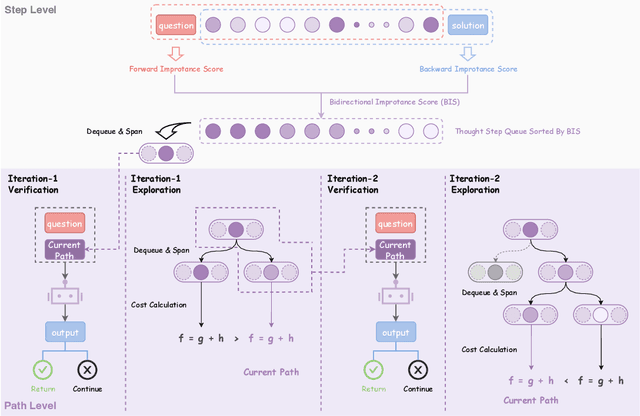

Large Reasoning Models (LRMs) achieve superior performance by extending the thought length. However, a lengthy thinking trajectory leads to reduced efficiency. Most of the existing methods are stuck in the assumption of overthinking and attempt to reason efficiently by compressing the Chain-of-Thought, but this often leads to performance degradation. To address this problem, we introduce A*-Thought, an efficient tree search-based unified framework designed to identify and isolate the most essential thoughts from the extensive reasoning chains produced by these models. It formulates the reasoning process of LRMs as a search tree, where each node represents a reasoning span in the giant reasoning space. By combining the A* search algorithm with a cost function specific to the reasoning path, it can efficiently compress the chain of thought and determine a reasoning path with high information density and low cost. In addition, we also propose a bidirectional importance estimation mechanism, which further refines this search process and enhances its efficiency beyond uniform sampling. Extensive experiments on several advanced math tasks show that A*-Thought effectively balances performance and efficiency over a huge search space. Specifically, A*-Thought can improve the performance of QwQ-32B by 2.39$\times$ with low-budget and reduce the length of the output token by nearly 50% with high-budget. The proposed method is also compatible with several other LRMs, demonstrating its generalization capability. The code can be accessed at: https://github.com/AI9Stars/AStar-Thought.
Speculative Decoding Meets Quantization: Compatibility Evaluation and Hierarchical Framework Design
May 29, 2025Speculative decoding and quantization effectively accelerate memory-bound inference of large language models. Speculative decoding mitigates the memory bandwidth bottleneck by verifying multiple tokens within a single forward pass, which increases computational effort. Quantization achieves this optimization by compressing weights and activations into lower bit-widths and also reduces computations via low-bit matrix multiplications. To further leverage their strengths, we investigate the integration of these two techniques. Surprisingly, experiments applying the advanced speculative decoding method EAGLE-2 to various quantized models reveal that the memory benefits from 4-bit weight quantization are diminished by the computational load from speculative decoding. Specifically, verifying a tree-style draft incurs significantly more time overhead than a single-token forward pass on 4-bit weight quantized models. This finding led to our new speculative decoding design: a hierarchical framework that employs a small model as an intermediate stage to turn tree-style drafts into sequence drafts, leveraging the memory access benefits of the target quantized model. Experimental results show that our hierarchical approach achieves a 2.78$\times$ speedup across various tasks for the 4-bit weight Llama-3-70B model on an A100 GPU, outperforming EAGLE-2 by 1.31$\times$. Code available at https://github.com/AI9Stars/SpecMQuant.
AutoReproduce: Automatic AI Experiment Reproduction with Paper Lineage
May 27, 2025Efficient experiment reproduction is critical to accelerating progress in artificial intelligence. However, the inherent complexity of method design and training procedures presents substantial challenges for automation. Notably, reproducing experiments often requires implicit domain-specific knowledge not explicitly documented in the original papers. To address this, we introduce the paper lineage algorithm, which identifies and extracts implicit knowledge from the relevant references cited by the target paper. Building on this idea, we propose AutoReproduce, a multi-agent framework capable of automatically reproducing experiments described in research papers in an end-to-end manner. AutoReproduce enhances code executability by generating unit tests alongside the reproduction process. To evaluate the reproduction capability, we construct ReproduceBench, a benchmark annotated with verified implementations, and introduce novel evaluation metrics to assess both the reproduction and execution fidelity. Experimental results demonstrate that AutoReproduce outperforms the existing strong agent baselines on all five evaluation metrics by a peak margin of over $70\%$. In particular, compared to the official implementations, AutoReproduce achieves an average performance gap of $22.1\%$ on $89.74\%$ of the executable experiment runs. The code will be available at https://github.com/AI9Stars/AutoReproduce.
Joint Graph Convolution and Sequential Modeling for Scalable Network Traffic Estimation
May 12, 2025This study focuses on the challenge of predicting network traffic within complex topological environments. It introduces a spatiotemporal modeling approach that integrates Graph Convolutional Networks (GCN) with Gated Recurrent Units (GRU). The GCN component captures spatial dependencies among network nodes, while the GRU component models the temporal evolution of traffic data. This combination allows for precise forecasting of future traffic patterns. The effectiveness of the proposed model is validated through comprehensive experiments on the real-world Abilene network traffic dataset. The model is benchmarked against several popular deep learning methods. Furthermore, a set of ablation experiments is conducted to examine the influence of various components on performance, including changes in the number of graph convolution layers, different temporal modeling strategies, and methods for constructing the adjacency matrix. Results indicate that the proposed approach achieves superior performance across multiple metrics, demonstrating robust stability and strong generalization capabilities in complex network traffic forecasting scenarios.
Towards Robust Few-Shot Text Classification Using Transformer Architectures and Dual Loss Strategies
May 09, 2025



Few-shot text classification has important application value in low-resource environments. This paper proposes a strategy that combines adaptive fine-tuning, contrastive learning, and regularization optimization to improve the classification performance of Transformer-based models. Experiments on the FewRel 2.0 dataset show that T5-small, DeBERTa-v3, and RoBERTa-base perform well in few-shot tasks, especially in the 5-shot setting, which can more effectively capture text features and improve classification accuracy. The experiment also found that there are significant differences in the classification difficulty of different relationship categories. Some categories have fuzzy semantic boundaries or complex feature distributions, making it difficult for the standard cross entropy loss to learn the discriminative information required to distinguish categories. By introducing contrastive loss and regularization loss, the generalization ability of the model is enhanced, effectively alleviating the overfitting problem in few-shot environments. In addition, the research results show that the use of Transformer models or generative architectures with stronger self-attention mechanisms can help improve the stability and accuracy of few-shot classification.
Modeling Multi-Hop Semantic Paths for Recommendation in Heterogeneous Information Networks
May 09, 2025



This study focuses on the problem of path modeling in heterogeneous information networks and proposes a multi-hop path-aware recommendation framework. The method centers on multi-hop paths composed of various types of entities and relations. It models user preferences through three stages: path selection, semantic representation, and attention-based fusion. In the path selection stage, a path filtering mechanism is introduced to remove redundant and noisy information. In the representation learning stage, a sequential modeling structure is used to jointly encode entities and relations, preserving the semantic dependencies within paths. In the fusion stage, an attention mechanism assigns different weights to each path to generate a global user interest representation. Experiments conducted on real-world datasets such as Amazon-Book show that the proposed method significantly outperforms existing recommendation models across multiple evaluation metrics, including HR@10, Recall@10, and Precision@10. The results confirm the effectiveness of multi-hop paths in capturing high-order interaction semantics and demonstrate the expressive modeling capabilities of the framework in heterogeneous recommendation scenarios. This method provides both theoretical and practical value by integrating structural information modeling in heterogeneous networks with recommendation algorithm design. It offers a more expressive and flexible paradigm for learning user preferences in complex data environments.