 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
MCPWorld: A Unified Benchmarking Testbed for API, GUI, and Hybrid Computer Use Agents
Jun 09, 2025(M)LLM-powered computer use agents (CUA) are emerging as a transformative technique to automate human-computer interaction. However, existing CUA benchmarks predominantly target GUI agents, whose evaluation methods are susceptible to UI changes and ignore function interactions exposed by application APIs, e.g., Model Context Protocol (MCP). To this end, we propose MCPWorld, the first automatic CUA testbed for API, GUI, and API-GUI hybrid agents. A key principle of MCPWorld is the use of "white-box apps", i.e., those with source code availability and can be revised/re-compiled as needed (e.g., adding MCP support), with two notable advantages: (1) It greatly broadens the design space of CUA, such as what and how the app features to be exposed/extracted as CUA-callable APIs. (2) It allows MCPWorld to programmatically verify task completion by directly monitoring application behavior through techniques like dynamic code instrumentation, offering robust, accurate CUA evaluation decoupled from specific agent implementations or UI states. Currently, MCPWorld includes 201 well curated and annotated user tasks, covering diversified use cases and difficulty levels. MCPWorld is also fully containerized with GPU acceleration support for flexible adoption on different OS/hardware environments. Our preliminary experiments, using a representative LLM-powered CUA framework, achieve 75.12% task completion accuracy, simultaneously providing initial evidence on the practical effectiveness of agent automation leveraging MCP. Overall, we anticipate MCPWorld to facilitate and standardize the benchmarking of next-generation computer use agents that can leverage rich external tools. Our code and dataset are publicly available at https://github.com/SAAgent/MCPWorld.
Attend More Times for Image Captioning
Dec 08, 2018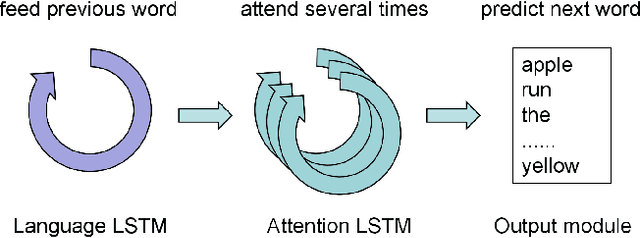
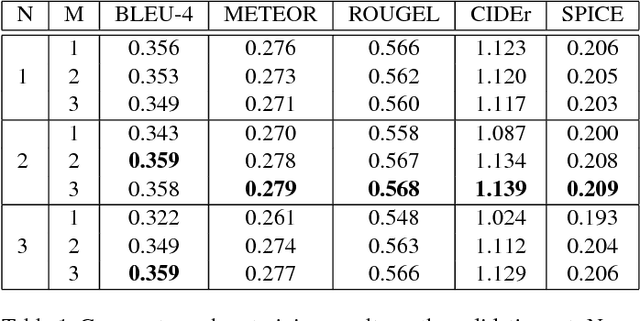
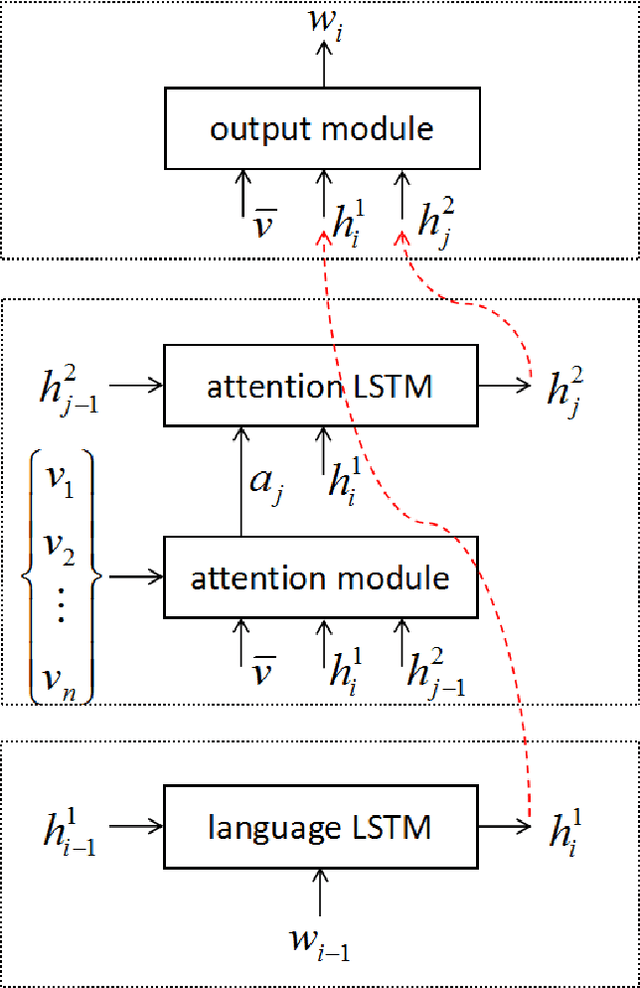
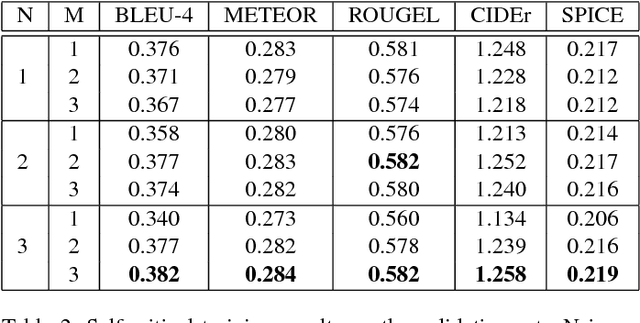
Most attention-based image captioning models attend to the image once per word. However, attending once per word is rigid and is easy to miss some information. Attending more times can adjust the attention position, find the missing information back and avoid generating the wrong word. In this paper, we show that attending more times per word can gain improvements in the image captioning task. We propose a flexible two-LSTM merge model to make it convenient to encode more attentions than words. Our captioning model uses two LSTMs to encode the word sequence and the attention sequence respectively. The information of the two LSTMs and the image feature are combined to predict the next word. Experiments on the MSCOCO caption dataset show that our method outperforms the state-of-the-art. Using bottom up features and self-critical training method, our method gets BLEU-4, METEOR, ROUGE-L and CIDEr scores of 0.381, 0.283, 0.580 and 1.261 on the Karpathy test split.