 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralGrok: Accelerate Grokking by Neural Gradient Transformation
Apr 24, 2025Grokking is proposed and widely studied as an intricate phenomenon in which generalization is achieved after a long-lasting period of overfitting. In this work, we propose NeuralGrok, a novel gradient-based approach that learns an optimal gradient transformation to accelerate the generalization of transformers in arithmetic tasks. Specifically, NeuralGrok trains an auxiliary module (e.g., an MLP block) in conjunction with the base model. This module dynamically modulates the influence of individual gradient components based on their contribution to generalization, guided by a bilevel optimization algorithm. Our extensive experiments demonstrate that NeuralGrok significantly accelerates generalization, particularly in challenging arithmetic tasks. We also show that NeuralGrok promotes a more stable training paradigm, constantly reducing the model's complexity, while traditional regularization methods, such as weight decay, can introduce substantial instability and impede generalization. We further investigate the intrinsic model complexity leveraging a novel Absolute Gradient Entropy (AGE) metric, which explains that NeuralGrok effectively facilitates generalization by reducing the model complexity. We offer valuable insights on the grokking phenomenon of Transformer models, which encourages a deeper understanding of the fundamental principles governing generalization ability.
Fast Online Adaptive Neural MPC via Meta-Learning
Apr 24, 2025Data-driven model predictive control (MPC) has demonstrated significant potential for improving robot control performance in the presence of model uncertainties. However, existing approaches often require extensive offline data collection and computationally intensive training, limiting their ability to adapt online. To address these challenges, this paper presents a fast online adaptive MPC framework that leverages neural networks integrated with Model-Agnostic Meta-Learning (MAML). Our approach focuses on few-shot adaptation of residual dynamics - capturing the discrepancy between nominal and true system behavior - using minimal online data and gradient steps. By embedding these meta-learned residual models into a computationally efficient L4CasADi-based MPC pipeline, the proposed method enables rapid model correction, enhances predictive accuracy, and improves real-time control performance. We validate the framework through simulation studies on a Van der Pol oscillator, a Cart-Pole system, and a 2D quadrotor. Results show significant gains in adaptation speed and prediction accuracy over both nominal MPC and nominal MPC augmented with a freshly initialized neural network, underscoring the effectiveness of our approach for real-time adaptive robot control.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Rethinking Key-Value Cache Compression Techniques for Large Language Model Serving
Mar 31, 2025Key-Value cache (\texttt{KV} \texttt{cache}) compression has emerged as a promising technique to optimize Large Language Model (LLM) serving. It primarily decreases the memory consumption of \texttt{KV} \texttt{cache} to reduce the computation cost. Despite the development of many compression algorithms, their applications in production environments are still not prevalent. In this paper, we revisit mainstream \texttt{KV} \texttt{cache} compression solutions from a practical perspective. Our contributions are three-fold. First, we comprehensively review existing algorithmic designs and benchmark studies for \texttt{KV} \texttt{cache} compression and identify missing pieces in their performance measurement, which could hinder their adoption in practice. Second, we empirically evaluate representative \texttt{KV} \texttt{cache} compression methods to uncover two key issues that affect the computational efficiency: (1) while compressing \texttt{KV} \texttt{cache} can reduce memory consumption, current implementations (e.g., FlashAttention, PagedAttention) do not optimize for production-level LLM serving, resulting in suboptimal throughput performance; (2) compressing \texttt{KV} \texttt{cache} may lead to longer outputs, resulting in increased end-to-end latency. We further investigate the accuracy performance of individual samples rather than the overall performance, revealing the intrinsic limitations in \texttt{KV} \texttt{cache} compression when handling specific LLM tasks. Third, we provide tools to shed light on future \texttt{KV} \texttt{cache} compression studies and facilitate their practical deployment in production. They are open-sourced in \href{https://github.com/LLMkvsys/rethink-kv-compression}{https://github.com/LLMkvsys/rethink-kv-compression}.
MoonCast: High-Quality Zero-Shot Podcast Generation
Mar 19, 2025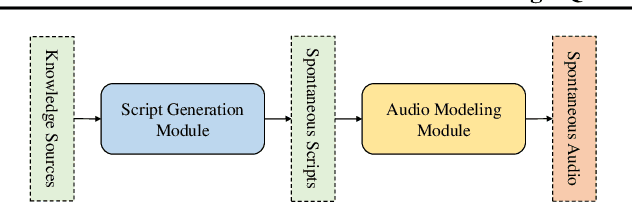



Recent advances in text-to-speech synthesis have achieved notable success in generating high-quality short utterances for individual speakers. However, these systems still face challenges when extending their capabilities to long, multi-speaker, and spontaneous dialogues, typical of real-world scenarios such as podcasts. These limitations arise from two primary challenges: 1) long speech: podcasts typically span several minutes, exceeding the upper limit of most existing work; 2) spontaneity: podcasts are marked by their spontaneous, oral nature, which sharply contrasts with formal, written contexts; existing works often fall short in capturing this spontaneity. In this paper, we propose MoonCast, a solution for high-quality zero-shot podcast generation, aiming to synthesize natural podcast-style speech from text-only sources (e.g., stories, technical reports, news in TXT, PDF, or Web URL formats) using the voices of unseen speakers. To generate long audio, we adopt a long-context language model-based audio modeling approach utilizing large-scale long-context speech data. To enhance spontaneity, we utilize a podcast generation module to generate scripts with spontaneous details, which have been empirically shown to be as crucial as the text-to-speech modeling itself. Experiments demonstrate that MoonCast outperforms baselines, with particularly notable improvements in spontaneity and coherence.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
Design, Dynamic Modeling and Control of a 2-DOF Robotic Wrist Actuated by Twisted and Coiled Actuators
Mar 07, 2025



Robotic wrists play a pivotal role in the functionality of industrial manipulators and humanoid robots, facilitating manipulation and grasping tasks. In recent years, there has been a growing interest in integrating artificial muscle-driven actuators for robotic wrists, driven by advancements in technology offering high energy density, lightweight construction, and compact designs. However, in the study of robotic wrists driven by artificial muscles, dynamic model-based controllers are often overlooked, despite their critical importance for motion analysis and dynamic control of robots. This paper presents a novel design of a two-degree-of-freedom (2-DOF) robotic wrist driven by twisted and coiled actuators (TCA) utilizing a parallel mechanism with a 3RRRR configuration. The proposed robotic wrist is expected to feature lightweight structures and superior motion performance while mitigating friction issues. The Lagrangian dynamic model of the wrist is established, along with a nonlinear model predictive controller (NMPC) designed for trajectory tracking tasks. A prototype of the robotic wrist is developed, and extensive experiments are conducted to validate its superior motion performance and the proposed dynamic model. Subsequently, extensive comparative experiments between NMPC and PID controller were conducted under various operating conditions. The experimental results demonstrate the effectiveness and robustness of the dynamic model-based controller in the motion control of TCA-driven robotic wrists.
The Best of Both Worlds: Integrating Language Models and Diffusion Models for Video Generation
Mar 06, 2025Recent advancements in text-to-video (T2V) generation have been driven by two competing paradigms: autoregressive language models and diffusion models. However, each paradigm has intrinsic limitations: language models struggle with visual quality and error accumulation, while diffusion models lack semantic understanding and causal modeling. In this work, we propose LanDiff, a hybrid framework that synergizes the strengths of both paradigms through coarse-to-fine generation. Our architecture introduces three key innovations: (1) a semantic tokenizer that compresses 3D visual features into compact 1D discrete representations through efficient semantic compression, achieving a $\sim$14,000$\times$ compression ratio; (2) a language model that generates semantic tokens with high-level semantic relationships; (3) a streaming diffusion model that refines coarse semantics into high-fidelity videos. Experiments show that LanDiff, a 5B model, achieves a score of 85.43 on the VBench T2V benchmark, surpassing the state-of-the-art open-source models Hunyuan Video (13B) and other commercial models such as Sora, Keling, and Hailuo. Furthermore, our model also achieves state-of-the-art performance in long video generation, surpassing other open-source models in this field. Our demo can be viewed at https://landiff.github.io/.
Muon is Scalable for LLM Training
Feb 24, 2025Recently, the Muon optimizer based on matrix orthogonalization has demonstrated strong results in training small-scale language models, but the scalability to larger models has not been proven. We identify two crucial techniques for scaling up Muon: (1) adding weight decay and (2) carefully adjusting the per-parameter update scale. These techniques allow Muon to work out-of-the-box on large-scale training without the need of hyper-parameter tuning. Scaling law experiments indicate that Muon achieves $\sim\!2\times$ computational efficiency compared to AdamW with compute optimal training. Based on these improvements, we introduce Moonlight, a 3B/16B-parameter Mixture-of-Expert (MoE) model trained with 5.7T tokens using Muon. Our model improves the current Pareto frontier, achieving better performance with much fewer training FLOPs compared to prior models. We open-source our distributed Muon implementation that is memory optimal and communication efficient. We also release the pretrained, instruction-tuned, and intermediate checkpoints to support future research.
MSVCOD:A Large-Scale Multi-Scene Dataset for Video Camouflage Object Detection
Feb 19, 2025



Video Camouflaged Object Detection (VCOD) is a challenging task which aims to identify objects that seamlessly concealed within the background in videos. The dynamic properties of video enable detection of camouflaged objects through motion cues or varied perspectives. Previous VCOD datasets primarily contain animal objects, limiting the scope of research to wildlife scenarios. However, the applications of VCOD extend beyond wildlife and have significant implications in security, art, and medical fields. Addressing this problem, we construct a new large-scale multi-domain VCOD dataset MSVCOD. To achieve high-quality annotations, we design a semi-automatic iterative annotation pipeline that reduces costs while maintaining annotation accuracy. Our MSVCOD is the largest VCOD dataset to date, introducing multiple object categories including human, animal, medical, and vehicle objects for the first time, while also expanding background diversity across various environments. This expanded scope increases the practical applicability of the VCOD task in camouflaged object detection. Alongside this dataset, we introduce a one-steam video camouflage object detection model that performs both feature extraction and information fusion without additional motion feature fusion modules. Our framework achieves state-of-the-art results on the existing VCOD animal dataset and the proposed MSVCOD. The dataset and code will be made publicly available.