 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill-informed Data-driven Haptic Nudges for High-dimensional Human Motor Learning
Mar 13, 2026In this work, we propose a data-driven skill-informed framework to design optimal haptic nudge feedback for high-dimensional novel motor learning tasks. We first model the stochastic dynamics of human motor learning using an Input-Output Hidden Markov Model (IOHMM), which explicitly decouples latent skill evolution from observable kinematic emissions. Leveraging this predictive model, we formulate the haptic nudge feedback design problem as a Partially Observable Markov Decision Process (POMDP). This allows us to derive an optimal nudging policy that minimizes long-term performance cost, implicitly guiding the learner toward robust regions of the skill space. We validated our approach through a human-subject study ($N=30$) using a high-dimensional hand-exoskeleton task. Results demonstrate that participants trained with the POMDP-derived policy exhibited significantly accelerated task performance compared to groups receiving heuristic-based feedback or no feedback. Furthermore, synergy analysis revealed that the POMDP group discovered efficient low-dimensional motor representations more rapidly.
Multi-Robot Multitask Gaussian Process Estimation and Coverage
Mar 11, 2026Coverage control is essential for the optimal deployment of agents to monitor or cover areas with sensory demands. While traditional coverage involves single-task robots, increasing autonomy now enables multitask operations. This paper introduces a novel multitask coverage problem and addresses it for both the cases of known and unknown sensory demands. For known demands, we design a federated multitask coverage algorithm and establish its convergence properties. For unknown demands, we employ a multitask Gaussian Process (GP) framework to learn sensory demand functions and integrate it with the multitask coverage algorithm to develop an adaptive algorithm. We introduce a novel notion of multitask coverage regret that compares the performance of the adaptive algorithm against an oracle with prior knowledge of the demand functions. We establish that our algorithm achieves sublinear cumulative regret, and numerically illustrate its performance.
Velocity-Form Data-Enabled Predictive Control of Soft Robots under Unknown External Payloads
Oct 06, 2025



Data-driven control methods such as data-enabled predictive control (DeePC) have shown strong potential in efficient control of soft robots without explicit parametric models. However, in object manipulation tasks, unknown external payloads and disturbances can significantly alter the system dynamics and behavior, leading to offset error and degraded control performance. In this paper, we present a novel velocity-form DeePC framework that achieves robust and optimal control of soft robots under unknown payloads. The proposed framework leverages input-output data in an incremental representation to mitigate performance degradation induced by unknown payloads, eliminating the need for weighted datasets or disturbance estimators. We validate the method experimentally on a planar soft robot and demonstrate its superior performance compared to standard DeePC in scenarios involving unknown payloads.
Modeling Trust Dynamics in Robot-Assisted Delivery: Impact of Trust Repair Strategies
Jun 12, 2025With increasing efficiency and reliability, autonomous systems are becoming valuable assistants to humans in various tasks. In the context of robot-assisted delivery, we investigate how robot performance and trust repair strategies impact human trust. In this task, while handling a secondary task, humans can choose to either send the robot to deliver autonomously or manually control it. The trust repair strategies examined include short and long explanations, apology and promise, and denial. Using data from human participants, we model human behavior using an Input-Output Hidden Markov Model (IOHMM) to capture the dynamics of trust and human action probabilities. Our findings indicate that humans are more likely to deploy the robot autonomously when their trust is high. Furthermore, state transition estimates show that long explanations are the most effective at repairing trust following a failure, while denial is most effective at preventing trust loss. We also demonstrate that the trust estimates generated by our model are isomorphic to self-reported trust values, making them interpretable. This model lays the groundwork for developing optimal policies that facilitate real-time adjustment of human trust in autonomous systems.
Fast Online Adaptive Neural MPC via Meta-Learning
Apr 24, 2025



Data-driven model predictive control (MPC) has demonstrated significant potential for improving robot control performance in the presence of model uncertainties. However, existing approaches often require extensive offline data collection and computationally intensive training, limiting their ability to adapt online. To address these challenges, this paper presents a fast online adaptive MPC framework that leverages neural networks integrated with Model-Agnostic Meta-Learning (MAML). Our approach focuses on few-shot adaptation of residual dynamics - capturing the discrepancy between nominal and true system behavior - using minimal online data and gradient steps. By embedding these meta-learned residual models into a computationally efficient L4CasADi-based MPC pipeline, the proposed method enables rapid model correction, enhances predictive accuracy, and improves real-time control performance. We validate the framework through simulation studies on a Van der Pol oscillator, a Cart-Pole system, and a 2D quadrotor. Results show significant gains in adaptation speed and prediction accuracy over both nominal MPC and nominal MPC augmented with a freshly initialized neural network, underscoring the effectiveness of our approach for real-time adaptive robot control.
Trust-Aware Assistance Seeking in Human-Supervised Autonomy
Oct 27, 2024Our goal is to model and experimentally assess trust evolution to predict future beliefs and behaviors of human-robot teams in dynamic environments. Research suggests that maintaining trust among team members in a human-robot team is vital for successful team performance. Research suggests that trust is a multi-dimensional and latent entity that relates to past experiences and future actions in a complex manner. Employing a human-robot collaborative task, we design an optimal assistance-seeking strategy for the robot using a POMDP framework. In the task, the human supervises an autonomous mobile manipulator collecting objects in an environment. The supervisor's task is to ensure that the robot safely executes its task. The robot can either choose to attempt to collect the object or seek human assistance. The human supervisor actively monitors the robot's activities, offering assistance upon request, and intervening if they perceive the robot may fail. In this setting, human trust is the hidden state, and the primary objective is to optimize team performance. We execute two sets of human-robot interaction experiments. The data from the first experiment are used to estimate POMDP parameters, which are used to compute an optimal assistance-seeking policy evaluated in the second experiment. The estimated POMDP parameters reveal that, for most participants, human intervention is more probable when trust is low, particularly in high-complexity tasks. Our estimates suggest that the robot's action of asking for assistance in high-complexity tasks can positively impact human trust. Our experimental results show that the proposed trust-aware policy is better than an optimal trust-agnostic policy. By comparing model estimates of human trust, obtained using only behavioral data, with the collected self-reported trust values, we show that model estimates are isomorphic to self-reported responses.
Assistance-Seeking in Human-Supervised Autonomy: Role of Trust and Secondary Task Engagement (Extended Version)
May 30, 2024Using a dual-task paradigm, we explore how robot actions, performance, and the introduction of a secondary task influence human trust and engagement. In our study, a human supervisor simultaneously engages in a target-tracking task while supervising a mobile manipulator performing an object collection task. The robot can either autonomously collect the object or ask for human assistance. The human supervisor also has the choice to rely upon or interrupt the robot. Using data from initial experiments, we model the dynamics of human trust and engagement using a linear dynamical system (LDS). Furthermore, we develop a human action model to define the probability of human reliance on the robot. Our model suggests that participants are more likely to interrupt the robot when their trust and engagement are low during high-complexity collection tasks. Using Model Predictive Control (MPC), we design an optimal assistance-seeking policy. Evaluation experiments demonstrate the superior performance of the MPC policy over the baseline policy for most participants.
On Multi-Fidelity Impedance Tuning for Human-Robot Cooperative Manipulation
Oct 09, 2023We examine how a human-robot interaction (HRI) system may be designed when input-output data from previous experiments are available. In particular, we consider how to select an optimal impedance in the assistance design for a cooperative manipulation task with a new operator. Due to the variability between individuals, the design parameters that best suit one operator of the robot may not be the best parameters for another one. However, by incorporating historical data using a linear auto-regressive (AR-1) Gaussian process, the search for a new operator's optimal parameters can be accelerated. We lay out a framework for optimizing the human-robot cooperative manipulation that only requires input-output data. We establish how the AR-1 model improves the bound on the regret and numerically simulate a human-robot cooperative manipulation task to show the regret improvement. Further, we show how our approach's input-output nature provides robustness against modeling error through an additional numerical study.
Deterministic Sequencing of Exploration and Exploitation for Reinforcement Learning
Sep 15, 2022We propose Deterministic Sequencing of Exploration and Exploitation (DSEE) algorithm with interleaving exploration and exploitation epochs for model-based RL problems that aim to simultaneously learn the system model, i.e., a Markov decision process (MDP), and the associated optimal policy. During exploration, DSEE explores the environment and updates the estimates for expected reward and transition probabilities. During exploitation, the latest estimates of the expected reward and transition probabilities are used to obtain a robust policy with high probability. We design the lengths of the exploration and exploitation epochs such that the cumulative regret grows as a sub-linear function of time.
Towards Modeling Human Motor Learning Dynamics in High-Dimensional Spaces
Feb 06, 2022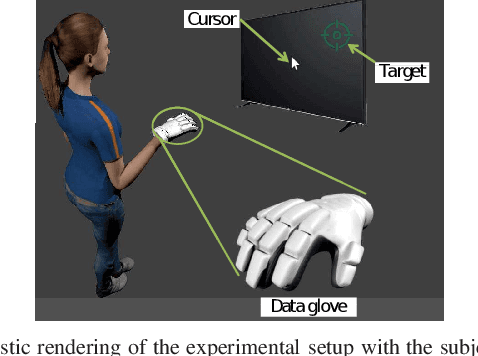
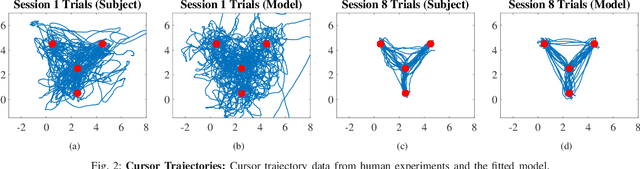
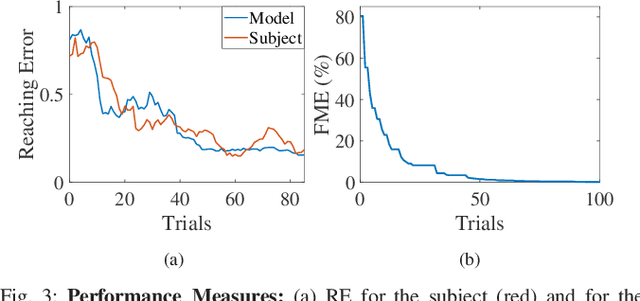
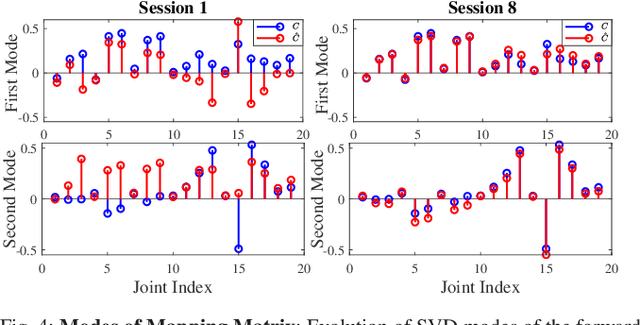
Designing effective rehabilitation strategies for upper extremities, particularly hands and fingers, warrants the need for a computational model of human motor learning. The presence of large degrees of freedom (DoFs) available in these systems makes it difficult to balance the trade-off between learning the full dexterity and accomplishing manipulation goals. The motor learning literature argues that humans use motor synergies to reduce the dimension of control space. Using the low-dimensional space spanned by these synergies, we develop a computational model based on the internal model theory of motor control. We analyze the proposed model in terms of its convergence properties and fit it to the data collected from human experiments. We compare the performance of the fitted model to the experimental data and show that it captures human motor learning behavior well.