 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeanAP-Guided Reinforced Active Learning for Object Detection
Oct 12, 2023


Active learning presents a promising avenue for training high-performance models with minimal labeled data, achieved by judiciously selecting the most informative instances to label and incorporating them into the task learner. Despite notable advancements in active learning for image recognition, metrics devised or learned to gauge the information gain of data, crucial for query strategy design, do not consistently align with task model performance metrics, such as Mean Average Precision (MeanAP) in object detection tasks. This paper introduces MeanAP-Guided Reinforced Active Learning for Object Detection (MAGRAL), a novel approach that directly utilizes the MeanAP metric of the task model to devise a sampling strategy employing a reinforcement learning-based sampling agent. Built upon LSTM architecture, the agent efficiently explores and selects subsequent training instances, and optimizes the process through policy gradient with MeanAP serving as reward. Recognizing the time-intensive nature of MeanAP computation at each step, we propose fast look-up tables to expedite agent training. We assess MAGRAL's efficacy across popular benchmarks, PASCAL VOC and MS COCO, utilizing different backbone architectures. Empirical findings substantiate MAGRAL's superiority over recent state-of-the-art methods, showcasing substantial performance gains. MAGRAL establishes a robust baseline for reinforced active object detection, signifying its potential in advancing the field.
TPTU: Task Planning and Tool Usage of Large Language Model-based AI Agents
Aug 07, 2023



With recent advancements in natural language processing, Large Language Models (LLMs) have emerged as powerful tools for various real-world applications. Despite their prowess, the intrinsic generative abilities of LLMs may prove insufficient for handling complex tasks which necessitate a combination of task planning and the usage of external tools. In this paper, we first propose a structured framework tailored for LLM-based AI Agents and discuss the crucial capabilities necessary for tackling intricate problems. Within this framework, we design two distinct types of agents (i.e., one-step agent and sequential agent) to execute the inference process. Subsequently, we instantiate the framework using various LLMs and evaluate their Task Planning and Tool Usage (TPTU) abilities on typical tasks. By highlighting key findings and challenges, our goal is to provide a helpful resource for researchers and practitioners to leverage the power of LLMs in their AI applications. Our study emphasizes the substantial potential of these models, while also identifying areas that need more investigation and improvement.
Explore the Power of Synthetic Data on Few-shot Object Detection
Mar 23, 2023Few-shot object detection (FSOD) aims to expand an object detector for novel categories given only a few instances for training. The few training samples restrict the performance of FSOD model. Recent text-to-image generation models have shown promising results in generating high-quality images. How applicable these synthetic images are for FSOD tasks remains under-explored. This work extensively studies how synthetic images generated from state-of-the-art text-to-image generators benefit FSOD tasks. We focus on two perspectives: (1) How to use synthetic data for FSOD? (2) How to find representative samples from the large-scale synthetic dataset? We design a copy-paste-based pipeline for using synthetic data. Specifically, saliency object detection is applied to the original generated image, and the minimum enclosing box is used for cropping the main object based on the saliency map. After that, the cropped object is randomly pasted on the image, which comes from the base dataset. We also study the influence of the input text of text-to-image generator and the number of synthetic images used. To construct a representative synthetic training dataset, we maximize the diversity of the selected images via a sample-based and cluster-based method. However, the severe problem of high false positives (FP) ratio of novel categories in FSOD can not be solved by using synthetic data. We propose integrating CLIP, a zero-shot recognition model, into the FSOD pipeline, which can filter 90% of FP by defining a threshold for the similarity score between the detected object and the text of the predicted category. Extensive experiments on PASCAL VOC and MS COCO validate the effectiveness of our method, in which performance gain is up to 21.9% compared to the few-shot baseline.
SeqCo-DETR: Sequence Consistency Training for Self-Supervised Object Detection with Transformers
Mar 15, 2023Self-supervised pre-training and transformer-based networks have significantly improved the performance of object detection. However, most of the current self-supervised object detection methods are built on convolutional-based architectures. We believe that the transformers' sequence characteristics should be considered when designing a transformer-based self-supervised method for the object detection task. To this end, we propose SeqCo-DETR, a novel Sequence Consistency-based self-supervised method for object DEtection with TRansformers. SeqCo-DETR defines a simple but effective pretext by minimizes the discrepancy of the output sequences of transformers with different image views as input and leverages bipartite matching to find the most relevant sequence pairs to improve the sequence-level self-supervised representation learning performance. Furthermore, we provide a mask-based augmentation strategy incorporated with the sequence consistency strategy to extract more representative contextual information about the object for the object detection task. Our method achieves state-of-the-art results on MS COCO (45.8 AP) and PASCAL VOC (64.1 AP), demonstrating the effectiveness of our approach.
An Effective Crop-Paste Pipeline for Few-shot Object Detection
Feb 28, 2023Few-shot object detection (FSOD) aims to expand an object detector for novel categories given only a few instances for training. However, detecting novel categories with only a few samples usually leads to the problem of misclassification. In FSOD, we notice the false positive (FP) of novel categories is prominent, in which the base categories are often recognized as novel ones. To address this issue, a novel data augmentation pipeline that Crops the Novel instances and Pastes them on the selected Base images, called CNPB, is proposed. There are two key questions to be answered: (1) How to select useful base images? and (2) How to combine novel and base data? We design a multi-step selection strategy to find useful base data. Specifically, we first discover the base images which contain the FP of novel categories and select a certain amount of samples from them for the base and novel categories balance. Then the bad cases, such as the base images that have unlabeled ground truth or easily confused base instances, are removed by using CLIP. Finally, the same category strategy is adopted, in which a novel instance with category n is pasted on the base image with the FP of n. During combination, a novel instance is cropped and randomly down-sized, and thus pasted at the assigned optimal location from the randomly generated candidates in a selected base image. Our method is simple yet effective and can be easy to plug into existing FSOD methods, demonstrating significant potential for use. Extensive experiments on PASCAL VOC and MS COCO validate the effectiveness of our method.
Explore the Power of Dropout on Few-shot Learning
Jan 26, 2023The generalization power of the pre-trained model is the key for few-shot deep learning. Dropout is a regularization technique used in traditional deep learning methods. In this paper, we explore the power of dropout on few-shot learning and provide some insights about how to use it. Extensive experiments on the few-shot object detection and few-shot image classification datasets, i.e., Pascal VOC, MS COCO, CUB, and mini-ImageNet, validate the effectiveness of our method.
A Unified Framework with Meta-dropout for Few-shot Learning
Oct 12, 2022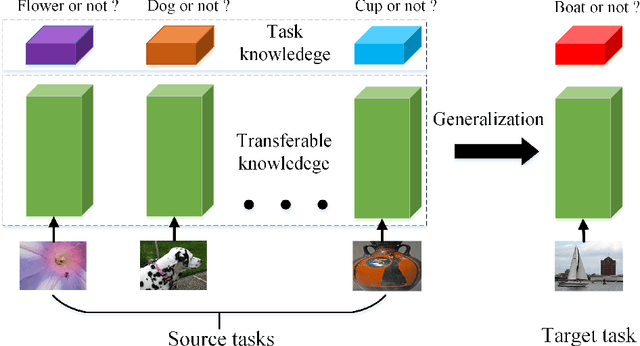

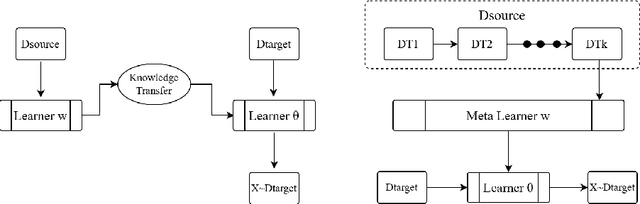
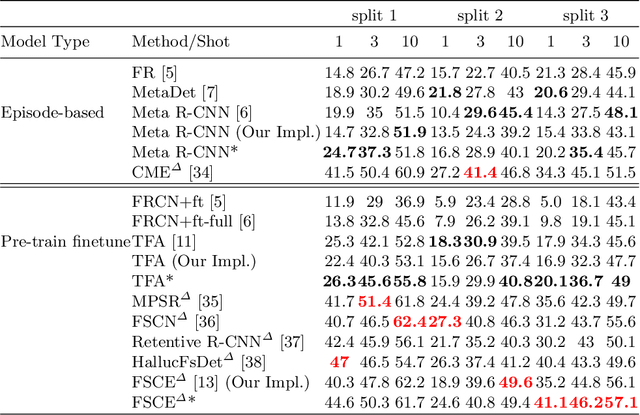
Conventional training of deep neural networks usually requires a substantial amount of data with expensive human annotations. In this paper, we utilize the idea of meta-learning to explain two very different streams of few-shot learning, i.e., the episodic meta-learning-based and pre-train finetune-based few-shot learning, and form a unified meta-learning framework. In order to improve the generalization power of our framework, we propose a simple yet effective strategy named meta-dropout, which is applied to the transferable knowledge generalized from base categories to novel categories. The proposed strategy can effectively prevent neural units from co-adapting excessively in the meta-training stage. Extensive experiments on the few-shot object detection and few-shot image classification datasets, i.e., Pascal VOC, MS COCO, CUB, and mini-ImageNet, validate the effectiveness of our method.
Rethinking Pseudo-LiDAR Representation
Aug 11, 2020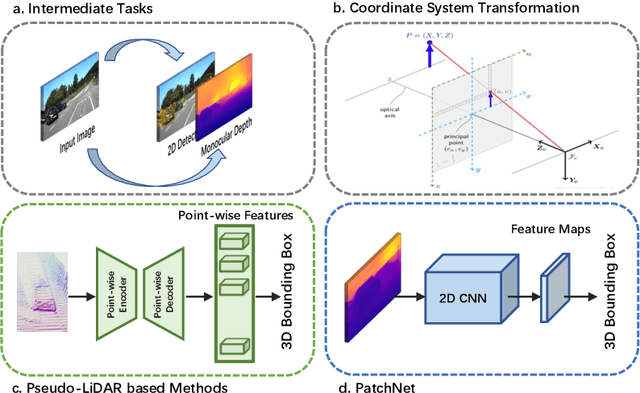
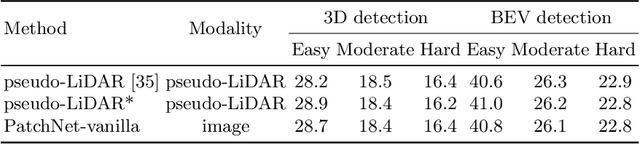
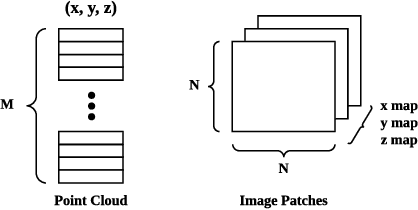
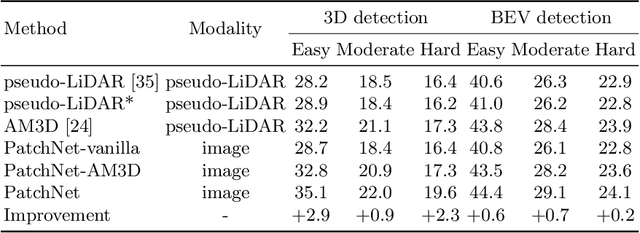
The recently proposed pseudo-LiDAR based 3D detectors greatly improve the benchmark of monocular/stereo 3D detection task. However, the underlying mechanism remains obscure to the research community. In this paper, we perform an in-depth investigation and observe that the efficacy of pseudo-LiDAR representation comes from the coordinate transformation, instead of data representation itself. Based on this observation, we design an image based CNN detector named Patch-Net, which is more generalized and can be instantiated as pseudo-LiDAR based 3D detectors. Moreover, the pseudo-LiDAR data in our PatchNet is organized as the image representation, which means existing 2D CNN designs can be easily utilized for extracting deep features from input data and boosting 3D detection performance. We conduct extensive experiments on the challenging KITTI dataset, where the proposed PatchNet outperforms all existing pseudo-LiDAR based counterparts. Code has been made available at: https://github.com/xinzhuma/patchnet.
Adapting Object Detectors with Conditional Domain Normalization
Mar 16, 2020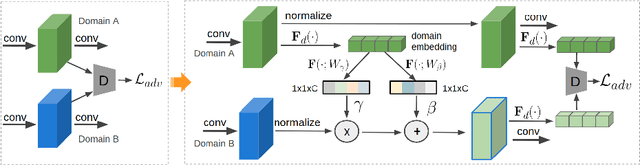
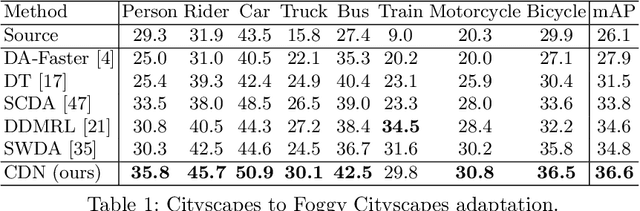
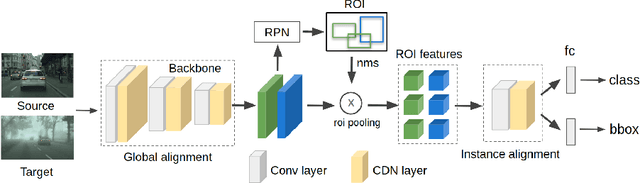
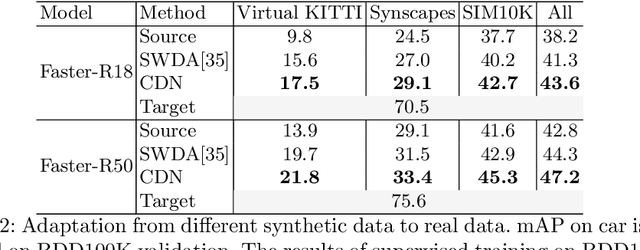
Real-world object detectors are often challenged by the domain gaps between different datasets. In this work, we present the Conditional Domain Normalization (CDN) to bridge the domain gap. CDN is designed to encode different domain inputs into a shared latent space, where the features from different domains carry the same domain attribute. To achieve this, we first disentangle the domain-specific attribute out of the semantic features from one domain via a domain embedding module, which learns a domain-vector to characterize the corresponding domain attribute information. Then this domain-vector is used to encode the features from another domain through a conditional normalization, resulting in different domains' features carrying the same domain attribute. We incorporate CDN into various convolution stages of an object detector to adaptively address the domain shifts of different level's representation. In contrast to existing adaptation works that conduct domain confusion learning on semantic features to remove domain-specific factors, CDN aligns different domain distributions by modulating the semantic features of one domain conditioned on the learned domain-vector of another domain. Extensive experiments show that CDN outperforms existing methods remarkably on both real-to-real and synthetic-to-real adaptation benchmarks, including 2D image detection and 3D point cloud detection.
Monocular 3D Object Detection with Decoupled Structured Polygon Estimation and Height-Guided Depth Estimation
Feb 05, 2020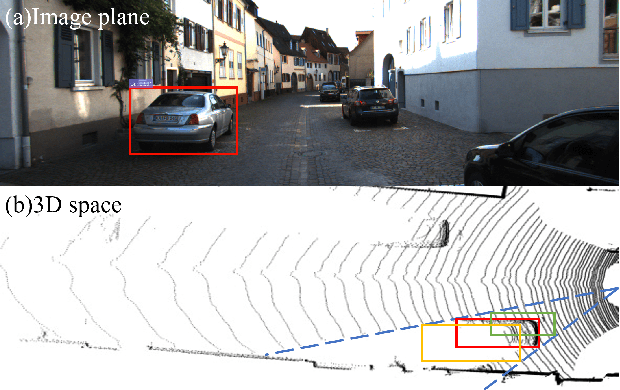
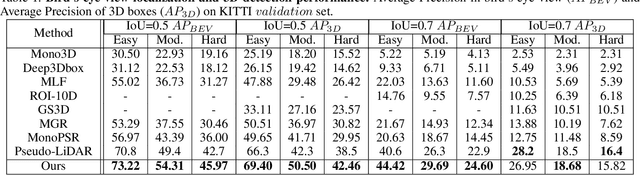
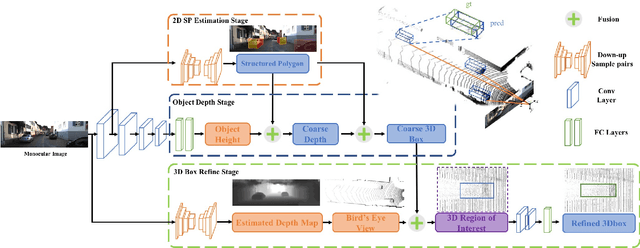
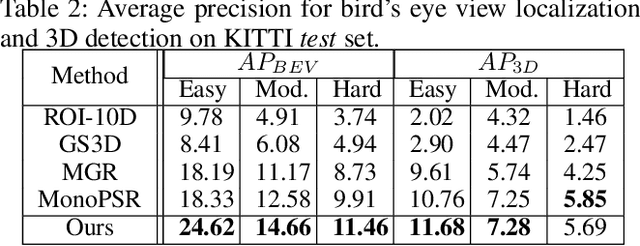
Monocular 3D object detection task aims to predict the 3D bounding boxes of objects based on monocular RGB images. Since the location recovery in 3D space is quite difficult on account of absence of depth information, this paper proposes a novel unified framework which decomposes the detection problem into a structured polygon prediction task and a depth recovery task. Different from the widely studied 2D bounding boxes, the proposed novel structured polygon in the 2D image consists of several projected surfaces of the target object. Compared to the widely-used 3D bounding box proposals, it is shown to be a better representation for 3D detection. In order to inversely project the predicted 2D structured polygon to a cuboid in the 3D physical world, the following depth recovery task uses the object height prior to complete the inverse projection transformation with the given camera projection matrix. Moreover, a fine-grained 3D box refinement scheme is proposed to further rectify the 3D detection results. Experiments are conducted on the challenging KITTI benchmark, in which our method achieves state-of-the-art detection accuracy.