 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Teacher-Student Framework for Semi-supervised Medical Image Segmentation From Mixed Supervision
Oct 23, 2020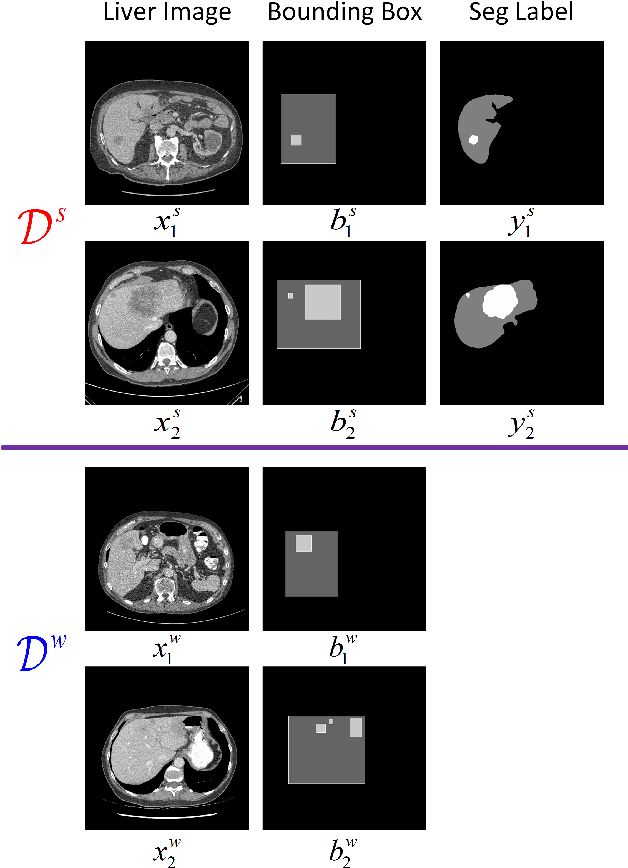
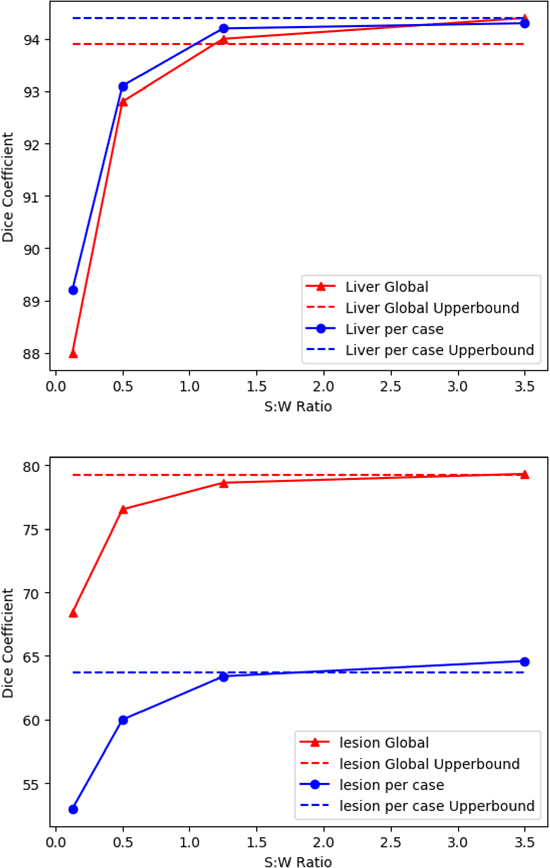
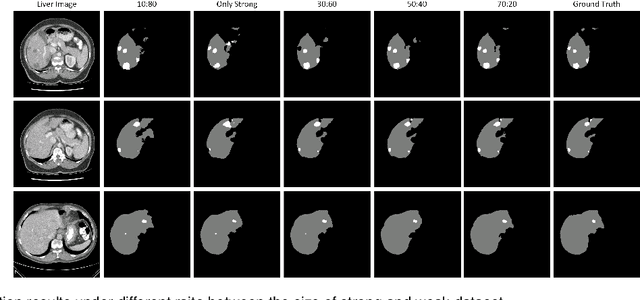
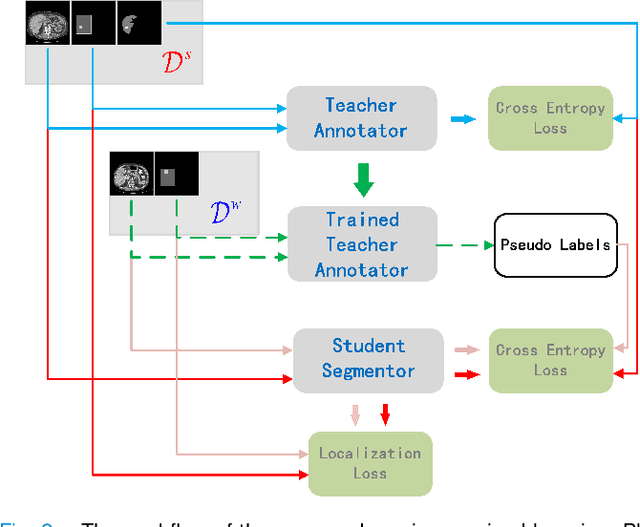
Standard segmentation of medical images based on full-supervised convolutional networks demands accurate dense annotations. Such learning framework is built on laborious manual annotation with restrict demands for expertise, leading to insufficient high-quality labels. To overcome such limitation and exploit massive weakly labeled data, we relaxed the rigid labeling requirement and developed a semi-supervised learning framework based on a teacher-student fashion for organ and lesion segmentation with partial dense-labeled supervision and supplementary loose bounding-box supervision which are easier to acquire. Observing the geometrical relation of an organ and its inner lesions in most cases, we propose a hierarchical organ-to-lesion (O2L) attention module in a teacher segmentor to produce pseudo-labels. Then a student segmentor is trained with combinations of manual-labeled and pseudo-labeled annotations. We further proposed a localization branch realized via an aggregation of high-level features in a deep decoder to predict locations of organ and lesion, which enriches student segmentor with precise localization information. We validated each design in our model on LiTS challenge datasets by ablation study and showed its state-of-the-art performance compared with recent methods. We show our model is robust to the quality of bounding box and achieves comparable performance compared with full-supervised learning methods.
Multi-Task Neural Networks with Spatial Activation for Retinal Vessel Segmentation and Artery/Vein Classification
Jul 18, 2020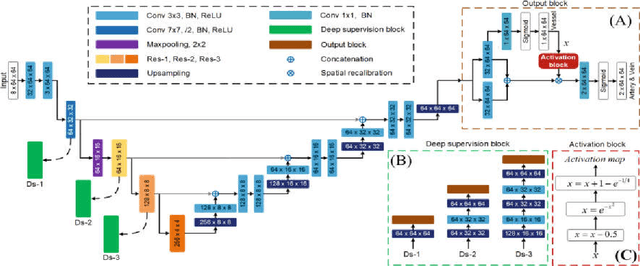
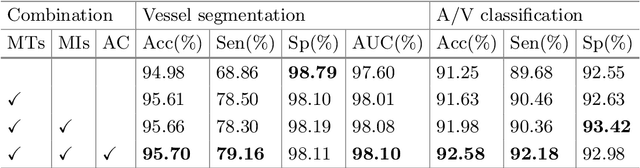
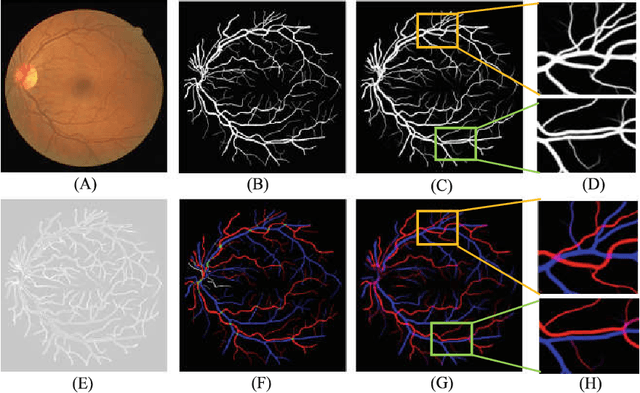
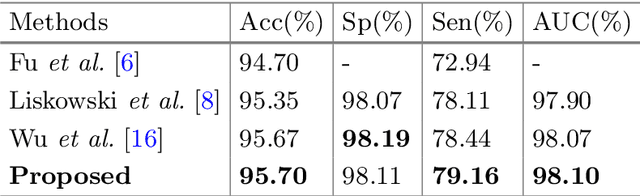
Retinal artery/vein (A/V) classification plays a critical role in the clinical biomarker study of how various systemic and cardiovascular diseases affect the retinal vessels. Conventional methods of automated A/V classification are generally complicated and heavily depend on the accurate vessel segmentation. In this paper, we propose a multi-task deep neural network with spatial activation mechanism that is able to segment full retinal vessel, artery and vein simultaneously, without the pre-requirement of vessel segmentation. The input module of the network integrates the domain knowledge of widely used retinal preprocessing and vessel enhancement techniques. We specially customize the output block of the network with a spatial activation mechanism, which takes advantage of a relatively easier task of vessel segmentation and exploits it to boost the performance of A/V classification. In addition, deep supervision is introduced to the network to assist the low level layers to extract more semantic information. The proposed network achieves pixel-wise accuracy of 95.70% for vessel segmentation, and A/V classification accuracy of 94.50%, which is the state-of-the-art performance for both tasks on the AV-DRIVE dataset. Furthermore, we have also tested the model performance on INSPIRE-AVR dataset, which achieves a skeletal A/V classification accuracy of 91.6%.
Cardiac Segmentation on Late Gadolinium Enhancement MRI: A Benchmark Study from Multi-Sequence Cardiac MR Segmentation Challenge
Jun 22, 2020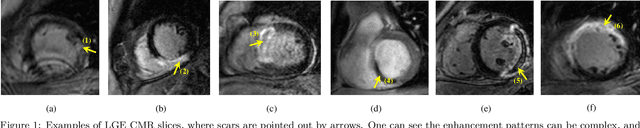

Accurate computing, analysis and modeling of the ventricles and myocardium from medical images are important, especially in the diagnosis and treatment management for patients suffering from myocardial infarction (MI). Late gadolinium enhancement (LGE) cardiac magnetic resonance (CMR) provides an important protocol to visualize MI. However, automated segmentation of LGE CMR is still challenging, due to the indistinguishable boundaries, heterogeneous intensity distribution and complex enhancement patterns of pathological myocardium from LGE CMR. Furthermore, compared with the other sequences LGE CMR images with gold standard labels are particularly limited, which represents another obstacle for developing novel algorithms for automatic segmentation of LGE CMR. This paper presents the selective results from the Multi-Sequence Cardiac MR (MS-CMR) Segmentation challenge, in conjunction with MICCAI 2019. The challenge offered a data set of paired MS-CMR images, including auxiliary CMR sequences as well as LGE CMR, from 45 patients who underwent cardiomyopathy. It was aimed to develop new algorithms, as well as benchmark existing ones for LGE CMR segmentation and compare them objectively. In addition, the paired MS-CMR images could enable algorithms to combine the complementary information from the other sequences for the segmentation of LGE CMR. Nine representative works were selected for evaluation and comparisons, among which three methods are unsupervised methods and the other six are supervised. The results showed that the average performance of the nine methods was comparable to the inter-observer variations. The success of these methods was mainly attributed to the inclusion of the auxiliary sequences from the MS-CMR images, which provide important label information for the training of deep neural networks.
Harmonizing Transferability and Discriminability for Adapting Object Detectors
Mar 13, 2020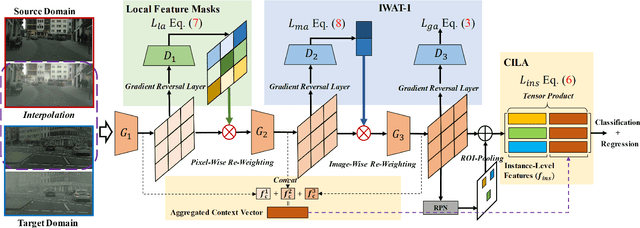
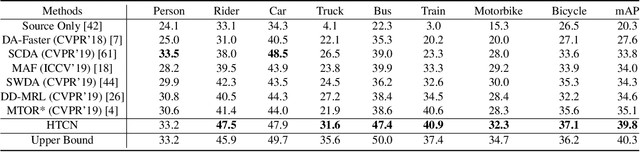
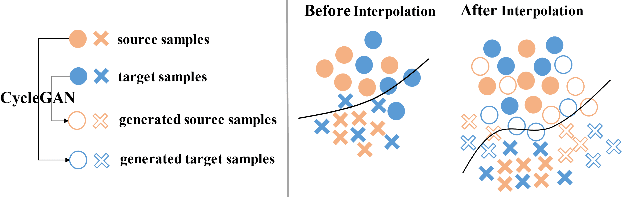

Recent advances in adaptive object detection have achieved compelling results in virtue of adversarial feature adaptation to mitigate the distributional shifts along the detection pipeline. Whilst adversarial adaptation significantly enhances the transferability of feature representations, the feature discriminability of object detectors remains less investigated. Moreover, transferability and discriminability may come at a contradiction in adversarial adaptation given the complex combinations of objects and the differentiated scene layouts between domains. In this paper, we propose a Hierarchical Transferability Calibration Network (HTCN) that hierarchically (local-region/image/instance) calibrates the transferability of feature representations for harmonizing transferability and discriminability. The proposed model consists of three components: (1) Importance Weighted Adversarial Training with input Interpolation (IWAT-I), which strengthens the global discriminability by re-weighting the interpolated image-level features; (2) Context-aware Instance-Level Alignment (CILA) module, which enhances the local discriminability by capturing the underlying complementary effect between the instance-level feature and the global context information for the instance-level feature alignment; (3) local feature masks that calibrate the local transferability to provide semantic guidance for the following discriminative pattern alignment. Experimental results show that HTCN significantly outperforms the state-of-the-art methods on benchmark datasets.
A Real-time Global Inference Network for One-stage Referring Expression Comprehension
Dec 07, 2019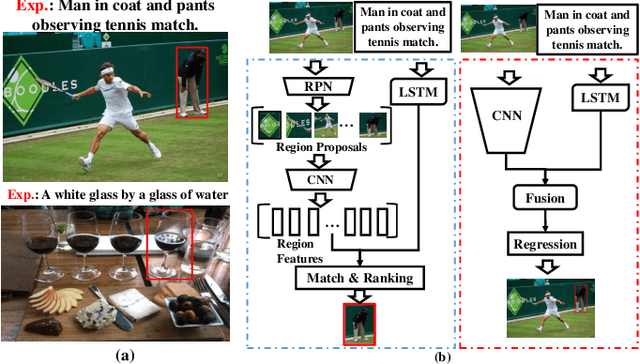
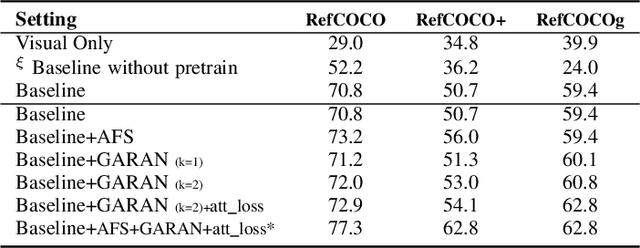
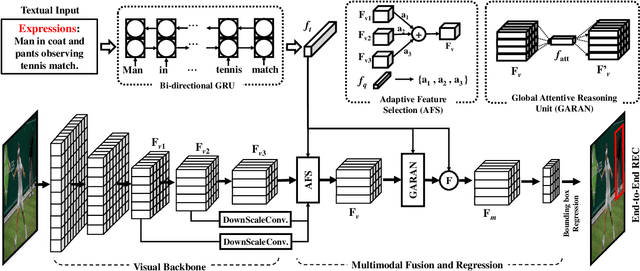

Referring Expression Comprehension (REC) is an emerging research spot in computer vision, which refers to detecting the target region in an image given an text description. Most existing REC methods follow a multi-stage pipeline, which are computationally expensive and greatly limit the application of REC. In this paper, we propose a one-stage model towards real-time REC, termed Real-time Global Inference Network (RealGIN). RealGIN addresses the diversity and complexity issues in REC with two innovative designs: the Adaptive Feature Selection (AFS) and the Global Attentive ReAsoNing unit (GARAN). AFS adaptively fuses features at different semantic levels to handle the varying content of expressions. GARAN uses the textual feature as a pivot to collect expression-related visual information from all regions, and thenselectively diffuse such information back to all regions, which provides sufficient context for modeling the complex linguistic conditions in expressions. On five benchmark datasets, i.e., RefCOCO, RefCOCO+, RefCOCOg, ReferIt and Flickr30k, the proposed RealGIN outperforms most prior works and achieves very competitive performances against the most advanced method, i.e., MAttNet. Most importantly, under the same hardware, RealGIN can boost the processing speed by about 10 times over the existing methods.
Learning Rate Dropout
Dec 05, 2019

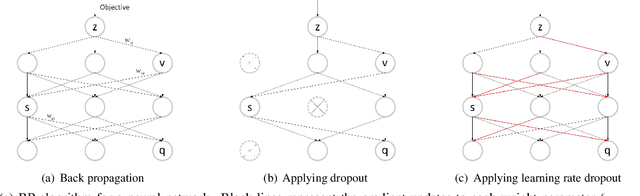
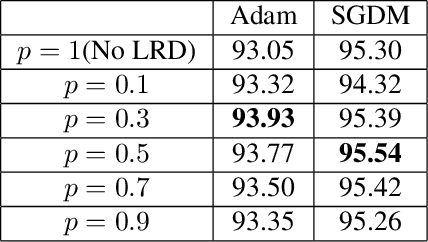
The performance of a deep neural network is highly dependent on its training, and finding better local optimal solutions is the goal of many optimization algorithms. However, existing optimization algorithms show a preference for descent paths that converge slowly and do not seek to avoid bad local optima. In this work, we propose Learning Rate Dropout (LRD), a simple gradient descent technique for training related to coordinate descent. LRD empirically aids the optimizer to actively explore in the parameter space by randomly setting some learning rates to zero; at each iteration, only parameters whose learning rate is not 0 are updated. As the learning rate of different parameters is dropped, the optimizer will sample a new loss descent path for the current update. The uncertainty of the descent path helps the model avoid saddle points and bad local minima. Experiments show that LRD is surprisingly effective in accelerating training while preventing overfitting.
Noise2Blur: Online Noise Extraction and Denoising
Dec 03, 2019
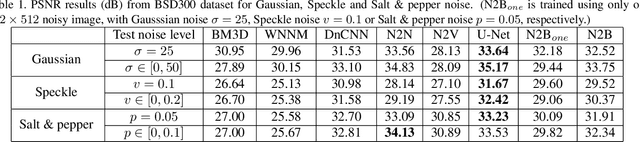
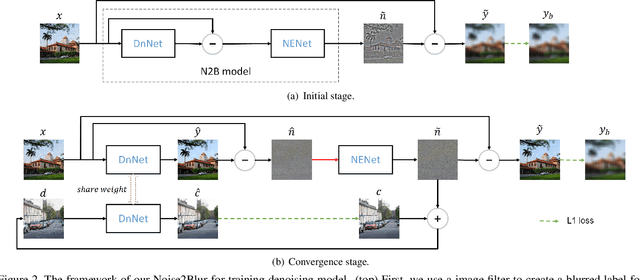
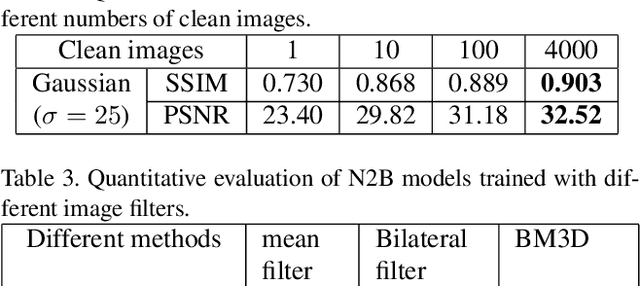
We propose a new framework called Noise2Blur (N2B) for training robust image denoising models without pre-collected paired noisy/clean images. The training of the model requires only some (or even one) noisy images, some random unpaired clean images, and noise-free but blurred labels obtained by predefined filtering of the noisy images. The N2B model consists of two parts: a denoising network and a noise extraction network. First, the noise extraction network learns to output a noise map using the noise information from the denoising network under the guidence of the blurred labels. Then, the noise map is added to a clean image to generate a new ``noisy/clean'' image pair. Using the new image pair, the denoising network learns to generate clean and high-quality images from noisy observations. These two networks are trained simultaneously and mutually aid each other to learn the mappings of noise to clean/blur. Experiments on several denoising tasks show that the denoising performance of N2B is close to that of other denoising CNNs trained with pre-collected paired data.
Multi-sequence Cardiac MR Segmentation with Adversarial Domain Adaptation Network
Oct 28, 2019
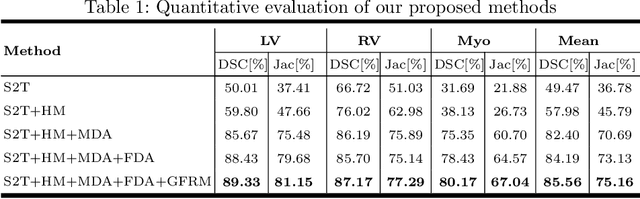
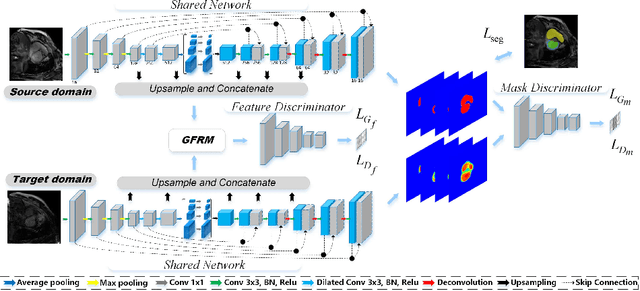
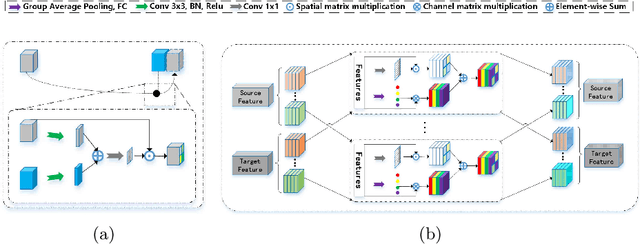
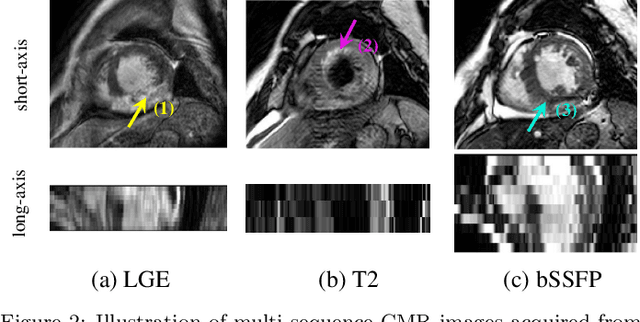
Automatic and accurate segmentation of the ventricles and myocardium from multi-sequence cardiac MRI (CMR) is crucial for the diagnosis and treatment management for patients suffering from myocardial infarction (MI). However, due to the existence of domain shift among different modalities of datasets, the performance of deep neural networks drops significantly when the training and testing datasets are distinct. In this paper, we propose an unsupervised domain alignment method to explicitly alleviate the domain shifts among different modalities of CMR sequences, \emph{e.g.,} bSSFP, LGE, and T2-weighted. Our segmentation network is attention U-Net with pyramid pooling module, where multi-level feature space and output space adversarial learning are proposed to transfer discriminative domain knowledge across different datasets. Moreover, we further introduce a group-wise feature recalibration module to enforce the fine-grained semantic-level feature alignment that matching features from different networks but with the same class label. We evaluate our method on the multi-sequence cardiac MR Segmentation Challenge 2019 datasets, which contain three different modalities of MRI sequences. Extensive experimental results show that the proposed methods can obtain significant segmentation improvements compared with the baseline models.
Uncertainty-Guided Domain Alignment for Layer Segmentation in OCT Images
Aug 30, 2019
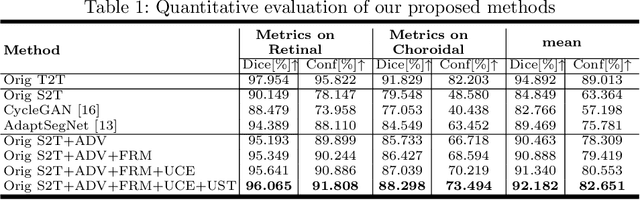
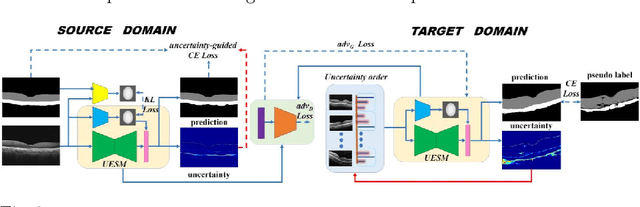
Automatic and accurate segmentation for retinal and choroidal layers of Optical Coherence Tomography (OCT) is crucial for detection of various ocular diseases. However, because of the variations in different equipments, OCT data obtained from different manufacturers might encounter appearance discrepancy, which could lead to performance fluctuation to a deep neural network. In this paper, we propose an uncertainty-guided domain alignment method to aim at alleviating this problem to transfer discriminative knowledge across distinct domains. We disign a novel uncertainty-guided cross-entropy loss for boosting the performance over areas with high uncertainty. An uncertainty-guided curriculum transfer strategy is developed for the self-training (ST), which regards uncertainty as efficient and effective guidance to optimize the learning process in target domain. Adversarial learning with feature recalibration module (FRM) is applied to transfer informative knowledge from the domain feature spaces adaptively. The experiments on two OCT datasets show that the proposed methods can obtain significant segmentation improvements compared with the baseline models.
Unsupervised Adversarial Graph Alignment with Graph Embedding
Jul 01, 2019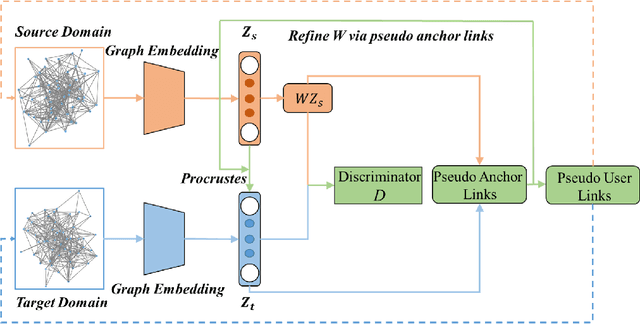
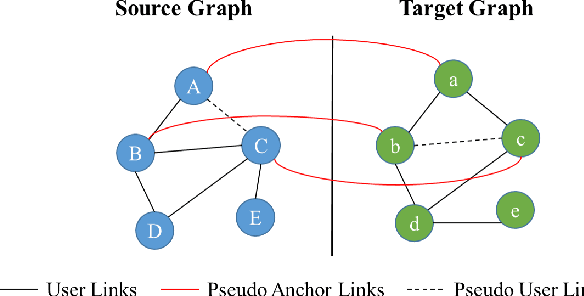
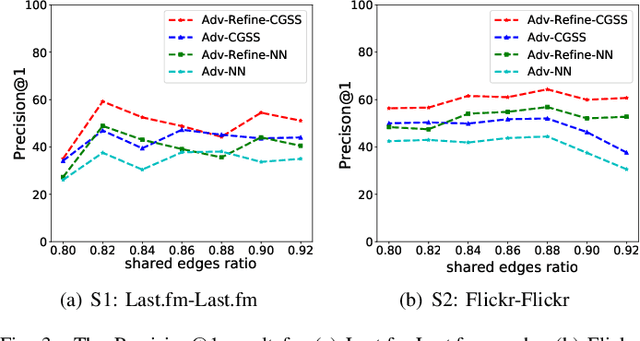
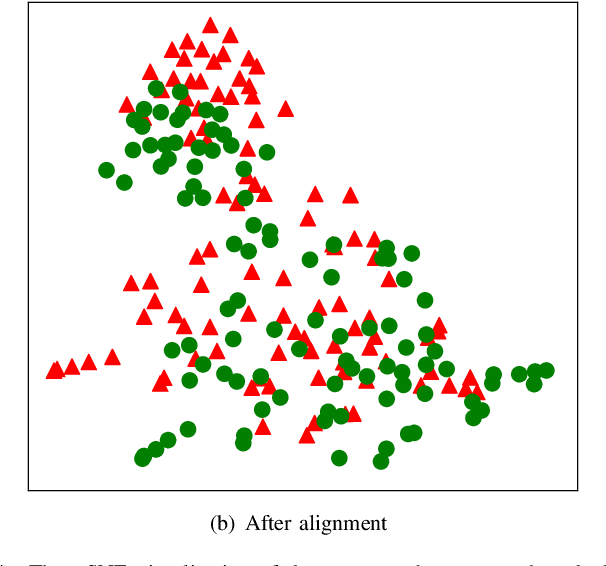
Graph alignment, also known as network alignment, is a fundamental task in social network analysis. Many recent works have relied on partially labeled cross-graph node correspondences, i.e., anchor links. However, due to the privacy and security issue, the manual labeling of anchor links for diverse scenarios may be prohibitive. Aligning two graphs without any anchor links is a crucial and challenging task. In this paper, we propose an Unsupervised Adversarial Graph Alignment (UAGA) framework to learn a cross-graph alignment between two embedding spaces of different graphs in a fully unsupervised fashion (\emph{i.e.,} no existing anchor links and no users' personal profile or attribute information is available). The proposed framework learns the embedding spaces of each graph, and then attempts to align the two spaces via adversarial training, followed by a refinement procedure. We further extend our UAGA method to incremental UAGA (iUAGA) that iteratively reveals the unobserved user links based on the pseudo anchor links. This can be used to further improve both the embedding quality and the alignment accuracy. Moreover, the proposed methods will benefit some real-world applications, \emph{e.g.,} link prediction in social networks. Comprehensive experiments on real-world data demonstrate the effectiveness of our proposed approaches UAGA and iUAGA for unsupervised graph alignment.